Python代码优化概要
Python即是面向过程语言,也是面向对象语言,更多情况下充当脚本语言的角色。虽是脚本语言,但同样涉及到代码优化的问题,代码优化能够让程序运行更快,它是在不改变程序运行结果的情况下使程序运行效率更高,根据80/20原则,实现程序的重构、优化、扩展以及文档相关的事情通常需要消耗80%的工作量。
优化通常包含两方面的内容:
1. 减小代码的体积、提高代码的可读性及可维护性。
2. 改进算法,降低代码复杂度,提高代码运行效率。
选择合适的数据结构一个良好的算法能够对性能起到关键作用,因此性能改进的首要点是对算法的改进。
在算法的时间复杂度排序上依次是:
O(1) > O(lg n) > O(n lg n) > O(n^2) > O(n^3) > O(n^k) > O(k^n) > O(n!)
比如说字典是哈希结构,遍历字典算法复杂度是O(1),而列表算法复杂度是O(n),因此查找对象字典比列表快。
下面列出一些代码优化的技巧,以概要方式总结。由于时间关系,只总结其中一部分,以后会持续更新。
【说明】
测试的工具: 包括time模块,timeit模块,profile模块或cProfile模块
验证的方式: 包括Python Shell,iPython,Python脚本
测试的环境: 包括Python 2.7.6,IPython 2.3.1
NOTE:
1. 一般来说c开头是c语言实现,速度更快些,比如cProfile就比profile快。cPickle比pickle快。
2. 一般来说Python版本较高,在速度上都有很大提升,所以测试环境不同,结果不一样。
++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++
【+= 比 +快】
从Python2.0开始,增加了增强性数据类型,比如说
X += Y
等价于X = X + Y
1. 就优化来说,左侧只需计算一次。在X += Y中,X可以使复杂的对象表达式。在增强形式中,则只需要计算一次。
然而,在完整的X = X + Y中,X出现两次,必须执行两次。因此增强赋值语句通常更快些。
from timeit import Timer #记得导入timeit模块
In [4]: Timer('S = S + "eggs"','S = "SPAM"').timeit()
Out[4]: 2.8523161220051065
In [5]: Timer('S += "eggs"','S = "SPAM"').timeit()
Out[5]: 2.602857082653941普通复制:
>>> M = [1,2,3]
>>> L = M
>>> M = M + [5]
>>> M;L
[1, 2, 3, 4]
[1, 2, 3]>>> M = [1,2,3]
>>> L = M
>>> M += [4]
>>> M;L
[1, 2, 3, 4]
[1, 2, 3, 4]
>>> Timer('L = L + [4,5,6]','L = [1,2,3]').timeit(20000)
4.324376213615835
>>> Timer('L += [4,5,6]','L = [1,2,3]').timeit(20000)
0.005897484107492801【可变对象内置函数比合并操作快】
第一种方法: 普通添加来实现
>>> L = [1,2,3]
>>> L = L + [4]
>>> L
[1, 2, 3, 4]>>> L = [1,2,3]
>>> L.append(4)
>>> L
[1, 2, 3, 4]>>> Timer('L = L + [4]','L = [1,2,3]').timeit(50000)
8.118179033256638
>>> Timer('L.append(4)','L = [1,2,3]').timeit(50000) #内置函数append()方法
0.01078882192950914
>>> Timer('L.extend([4])','L = [1,2,3]').timeit(50000) #内置函数extend()方法
0.020846637858539907++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++
【布尔测试比边界测试快】
>>> Timer('X < Y and Y < Z','X=1;Y=2;Z=3').timeit(100000000) #布尔测试
7.142944090197389
>>> Timer('X < Y < Z','X=1;Y=2;Z=3').timeit(100000000) #边界测试,判断Y结余X,Z之间
11.501173499654769【短路运算比and运算快】
在Python中,if用于条件判断,有下面几种情况
X and Y: X与Y同时为真,方为真
X or Y: X或Y任一位真,就为真, 也叫短路运算,即如果前面为真,后面则不判断
not X: X为假时方为真
In [28]: Timer('2 or 3').timeit(100000000) #短路运算:前面为真,后面不运算,所以速度快些
Out[28]: 3.780060393088206
In [29]: Timer('2 and 3').timeit(100000000) #and,必须运算为所有的,速度相对慢些
Out[29]: 4.313562268420355
In [30]: Timer('0 or 1').timeit(100000000) #or运算,但前面为假,所以和前面速度相当
Out[30]: 4.251177957004984
In [31]: Timer('not 0').timeit(100000000) #not运算,只需要判断一个条件,速度快些
Out[31]: 3.6270803685183637所以在程序中适当使用,可以提高程序效率.
++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++
【append比insert速度快】
列表的append方法要比insert方法快的多,因为后续的引用必须被移动以便使新元素腾地方.
复杂度append末尾添加,复杂度O(1),而insert复杂度是O(n)
>>> Timer('L.append(4)','L=[1,2,3,5,6]').timeit(200000)
0.03233202260122425
>>> Timer('L.insert(3,4)','L=[1,2,3,5,6]').timeit(200000)
18.31223843438289【成员变量测试:字典和集合快于列表和元祖】
可以用in来做成员变量判断,比如'a' in 'abcd'
判断列表和元祖中是否含有某个值的操作要比字典和集合慢的多。
因为Python会对列表中的值进行线性扫描,而另外两个基于哈希表,可以瞬间完成判断。数据越大,越明显!
In [44]: Timer('4 in L','L=(1,2,3,4,5,6,7,8,9)').timeit(100000000)
Out[44]: 12.941504527043435 #列表成员判断
In [45]: Timer('4 in T','T=[1,2,3,4,5,6,7,8,9]').timeit(100000000)
Out[45]: 12.883945908790338 #元祖成员判断,和列表差不多
In [46]: Timer('4 in S','S=set([1,2,3,4,5,6,7,8,9])').timeit(100000000)
Out[46]: 6.254324848690885 #集合成员判断,和字典差不多
In [47]: Timer('4 in D','D={1:"a",2:"b",3:"c",4:"d",5:"e",6:"f",7:"g",8:"h",9:"i"}').timeit(100000000)
Out[47]: 6.3508488422085065 #字典成员判断++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++
【列表合并extend比+速度快】
列表合并(+)是一种相当费资源的操作,因为必须创建一个新列表并将所有对象复制进去。
而extend将元素附加到现有列表中,因此会快很多,尤其是创建一个大列表时尤其如此.
+操作执行结果:
import profile #用cProfile会快些
def func_add(): #测试列表合并操作
lst = []
for i in range(5000):
for item in [[0],[1],[2],[3],[4],[5],[6],[7],[8],[9],[10]]:
lst = lst + item
if __name__=='__main__':
profile.run('func_add()')
#####测试结果:#####
>>>
5 function calls in 9.243 seconds
Ordered by: standard name
ncalls tottime percall cumtime percall filename:lineno(function)
1 0.000 0.000 0.000 0.000 :0(range)
1 0.006 0.006 0.006 0.006 :0(setprofile)
1 0.000 0.000 9.237 9.237 :1()
1 9.236 9.236 9.236 9.236 Learn.py:3(func_add)
1 0.000 0.000 9.243 9.243 profile:0(func_add())
0 0.000 0.000 profile:0(profiler) extend执行结果:
import profile
def func_extend():
lst = []
for i in range(5000):
for item in [[0],[1],[2],[3],[4],[5],[6],[7],[8],[9],[10]]:
lst.extend(item)
if __name__=='__main__':
profile.run('func_extend()')
#####输出结果:#####
>>>
55005 function calls in 0.279 seconds
Ordered by: standard name
ncalls tottime percall cumtime percall filename:lineno(function)
55000 0.124 0.000 0.124 0.000 :0(extend)
1 0.000 0.000 0.000 0.000 :0(range)
1 0.005 0.005 0.005 0.005 :0(setprofile)
1 0.000 0.000 0.274 0.274 :1()
1 0.149 0.149 0.273 0.273 Learn.py:3(func_extend)
1 0.000 0.000 0.279 0.279 profile:0(func_extend())
0 0.000 0.000 profile:0(profiler) ++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++
【xrange比range快】
In [9]: Timer('for i in range(1000): pass').timeit()
Out[9]: 30.839959527228757
In [10]: Timer('for i in xrange(1000): pass').timeit()
Out[10]: 19.644791055468943xrange:每次只迭代一个对象
range:一次生成所有数据,需要一个个扫描
NOTE: 在Python3.0中取消了xrange函数,只留range,不管这个range其实就是xrange,只不过名字变了。
++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++
【内置函数>列表推导>for循环>while循环】
http://blog.csdn.net/jerry_1126/article/details/41773277
++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++
【局部变量>全局变量】
import profile
A = 5
def param_test():
B = 5
res = 0
for i in range(100000000):
res = B + i
return res
if __name__=='__main__':
profile.run('param_test()')
>>> ===================================== RESTART =====================================
>>>
5 function calls in 37.012 seconds #全局变量测试结果:37 s
Ordered by: standard name
ncalls tottime percall cumtime percall filename:lineno(function)
1 19.586 19.586 19.586 19.586 :0(range)
1 1.358 1.358 1.358 1.358 :0(setprofile)
1 0.004 0.004 35.448 35.448 :1()
1 15.857 15.857 35.443 35.443 Learn.py:5(param_test)
1 0.206 0.206 37.012 37.012 profile:0(param_test())
0 0.000 0.000 profile:0(profiler)
>>> ===================================== RESTART =====================================
>>>
5 function calls in 11.504 seconds #局部变量测试结果: 11s
Ordered by: standard name
ncalls tottime percall cumtime percall filename:lineno(function)
1 3.135 3.135 3.135 3.135 :0(range)
1 0.006 0.006 0.006 0.006 :0(setprofile)
1 0.000 0.000 11.497 11.497 :1()
1 8.362 8.362 11.497 11.497 Learn.py:5(param_test)
1 0.000 0.000 11.504 11.504 profile:0(param_test())
0 0.000 0.000 profile:0(profiler)
【while 1 > while True】
while 1执行结果:
import cProfile
def while_1():
tag = 0
while 1:
tag += 1
if tag > 100000000:
break
if __name__=='__main__':
cProfile.run('while_1()')
>>> ===================================== RESTART =====================================
>>>
4 function calls in 5.366 seconds
Ordered by: standard name
ncalls tottime percall cumtime percall filename:lineno(function)
1 0.006 0.006 0.006 0.006 :0(setprofile)
1 0.000 0.000 5.360 5.360 :1()
1 5.360 5.360 5.360 5.360 Learn.py:3(while_1)
0 0.000 0.000 profile:0(profiler)
1 0.000 0.000 5.366 5.366 profile:0(while_1()) import cProfile
def while_true():
tag = 0
while True:
tag += 1
if tag > 100000000:
break
if __name__=='__main__':
cProfile.run('while_true()')
>>> ===================================== RESTART =====================================
>>>
4 function calls in 8.236 seconds
Ordered by: standard name
ncalls tottime percall cumtime percall filename:lineno(function)
1 0.012 0.012 0.012 0.012 :0(setprofile)
1 0.000 0.000 8.224 8.224 :1()
1 8.224 8.224 8.224 8.224 Learn.py:10(while_true)
0 0.000 0.000 profile:0(profiler)
1 0.000 0.000 8.236 8.236 profile:0(while_true()) 虽然前者比后者快些,但后者可读性无疑更好些.
++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++
【求交集集合比列表快】
列表测试结果:
from time import time
t1 = time()
list_1 = [32,78,65,99,19,43,18,22,7,1,9,2,4,8,56]
list_2 = [3,4,8,56,99,100]
temp = []
for x in range(1000000):
for i in list_2:
for j in list_1:
if i == j:
temp.append(i)
t2 = time()
print "Total time:", t2 - t1
#测试结果:
>>>
Total time: 13.6879999638from time import time
t1 = time()
set_1 = set([32,78,65,99,19,43,18,22,7,1,9,2,4,8,56])
set_2 = set([3,4,8,56,99,100])
for x in range(1000000):
set_same = set_1 & set_2
t2 = time()
print "Total time:", t2 - t1
#测试结果:
>>>
Total time: 0.611000061035>>> set1 = set([2,3,4,8,9]) #集合1
>>> set2 = set([1,3,4,5,6]) #集合2
>>> set1 & set2 #求交集
set([3, 4])
>>> set1 | set2 #求合集
set([1, 2, 3, 4, 5, 6, 8, 9])
>>> set1 - set2 #求差集
set([8, 9, 2])
>>> set1 ^ set2 #求异或:即排除共同部分
set([1, 2, 5, 6, 8, 9])【直接交换两变量 > 借助中间变量】
要交换X,Y的值,有两种方法:
1. 直接交换: X, Y = Y, X
>>> X,Y = 1,2
>>> X,Y
(1, 2)
>>> X, Y = Y, X
>>> X,Y
(2, 1)>>> X,Y = 1,2
>>> X,Y
(1, 2)
>>> T = X; X = Y; Y = T
>>> X,Y
(2, 1)
++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++
【is not速度快于!=】
在if条件判断中,可以用 if a is not None:或者 if a != None 前者运行速度快于后者.
测试结果:

++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++
【''.join(list)速度快于+或+=】
+测试结果:
''.join(list)测试结果:

++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++
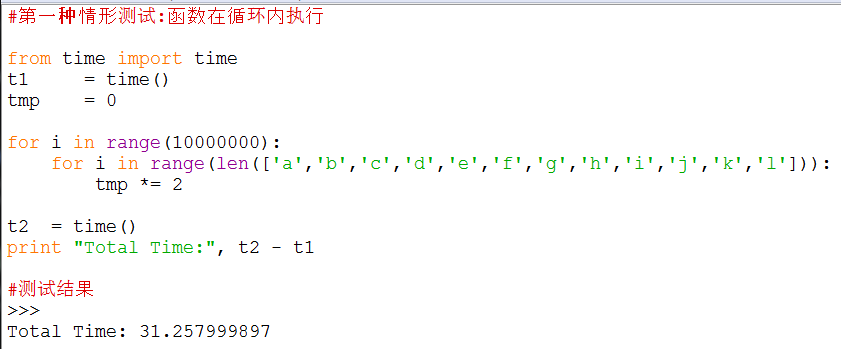
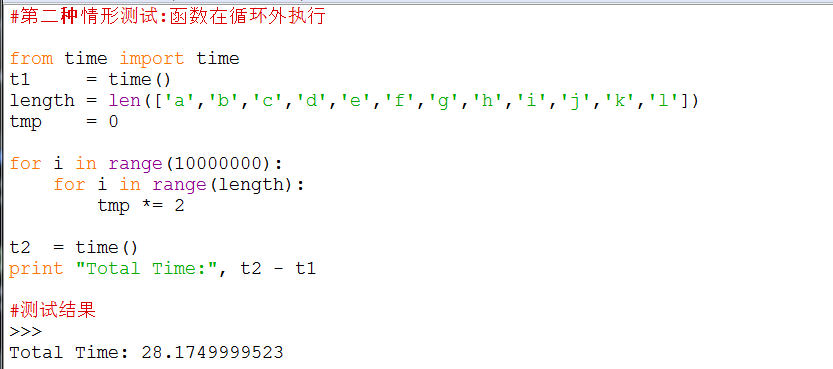
【在循环体外执行函数比在循环中快】
所以要减少函数的调用次数
++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++
【**比pow()速度快】
测试结果:

**其速度是pow()函数的几十倍,而且数据越大,越明显!
**相当于Python的移位操作: 右移(>>) 和 左移(<<)比如说 2**2 = 4相当于 2 << 1 其速度相当!

++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++
【生成器速度比列表快】

前者是列表解析对象,后者是generate对象,所需的内存空间与列表大小无关,所以速度快些.
在实际应用中,比如说创建一个集合,用生成器对象明显比列表对象要快些。

++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++
【浅拷贝的速度比深拷贝速度快】

++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++
【cPickle比pickle速度快】
pickle模块和cPickle模块都可以将Python对象永久存储在系统文件中。
但cPickle是Python的C语言实现,因而速度更快些。请看下面对比:

存储一个百万级别大小的列表,用cPickle模块几乎10倍于pickle模块。
++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++
【int()比int(math.floor())快】
比如对浮点数取整,32.9,如果要取年龄的话,只能是32。可以有两种方式
一种: int(math.floor(32.9)) # floor先取32.0再转为整数
一种: int(32.9) # 直接向下取整,math.floor()下多余的

可以看出,第二种方式要比第一种快的多。
++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++
【读取文件操作for循环比while高效】
测试项目: test.txt 3M的文件


测试结果: 182.62s
for line in open('filename'):
process(line)
上面这种方式应该读取文件的最佳方式:原因有三
1.写法最简单
2. 运行最快速
3. 从内存使用角度来看,也是最好的
NOTE:
1. readlines()是一次性加载所有的行,而xreadlines()是按需要加载,可避免大文件导致内存泄露
2. readline()是迭代逐行读取,从内存角度来说,在大文件处理中,效率要比readlines()高
3. 超大文件的话,用readlines()方式可以会导致内存崩溃。
++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++
【字典的迭代取值比直接取值高效】
>>> Timer('for v in d.values(): pass',"d={'a':1,'b':2,'c':3,'d':4,'e':5}").timeit(100000000)
43.297132594847085
>>> Timer('for v in d.itervalues(): pass',"d={'a':1,'b':2,'c':3,'d':4,'e':5}").timeit(100000000)
36.16957129734047# d.itervalues() 比d.values()要快些
# d.iteritems() 比d.items()要快些
# d.iterkeys() 比d.keys()要快些【创建字典常规方法比工厂方法要快】
常规方法:
d={'x':1, 'y':2, 'z':3}
工厂方法:如以下几种
1. dict((['x',1], ['y',2], ['z',3]))
2. dict(zip(('x', 'y', 'z'), (1, 2, 3)))
3. dict(x=1, y=2, z=3)
>>> Timer("d={'x':1, 'y':2, 'z':3}").timeit()
0.19084989859678103
>>> Timer("dict((['x',1], ['y',2], ['z',3]))")
>>> Timer("dict((['x',1], ['y',2], ['z',3]))").timeit()
1.5503493690009975 >>> Timer("D2=copy.copy({'x':1, 'y':2, 'z':3})","import copy").timeit()
1.074277245445046
>>> Timer("D3=dict((['x',1], ['y',2], ['z',3]))").timeit()
1.5830155758635556