python爬虫——使用requests库和xpath爬取猎聘网职位详情
文章目录
- 前言
- 一、页面分析
- 1.职位列表页面分析
- 2.职位详情页面URL获取
- 3.职位详情页面分析
- 至此,所有页面解析完毕,开始写代码。
- 二、代码编写
- 1.导入相应库
- 2.设置代理和随机请求头
- 3.获取职位详情页面URL
- 4.解析职位详情页面
- 5.将爬取的信息保存为csv格式的文件
- 三、requests.exceptions.ConnectionError: ('Connection aborted.', LineTooLong('got more than 65536 bytes when reading header line',))异常处理
- 四、完整代码
前言
最近闲来无事,使用python的requests库和xpath库爬取了猎聘网的招聘信息。因为只是为了练习,并没有限定职位、地域等信息。
一、页面分析
1.职位列表页面分析
点击进入猎聘网页面如下图所示:上面是职位筛选条件,下面是相应页码
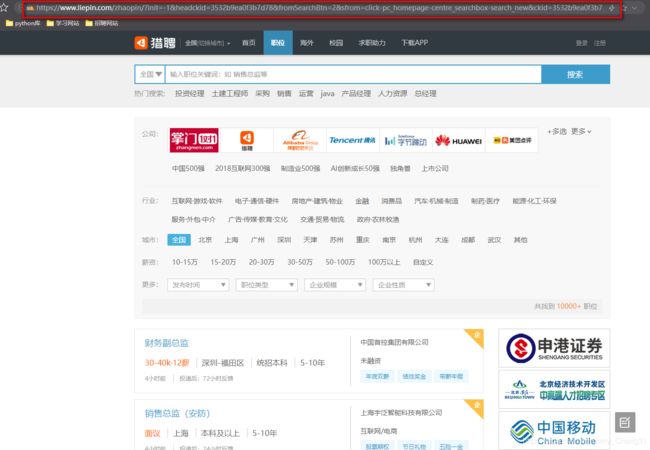
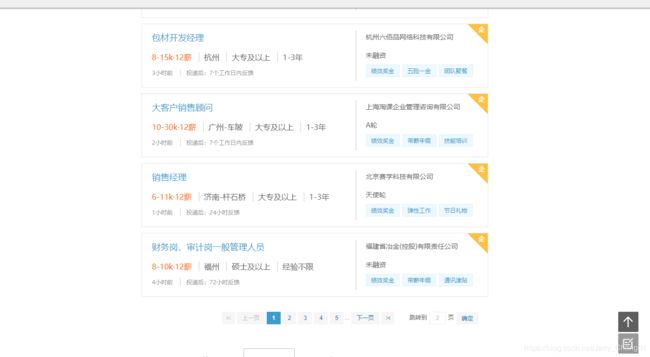
点击不同的页码,查看其URL:
第一页URL:
https://www.liepin.com/zhaopin/?init=-1&headckid=3532b9ea0f3b7d78&fromSearchBtn=2&ckid=3532b9ea0f3b7d78°radeFlag=0&sfrom=click-pc_homepage-centre_searchbox-search_new&key=&siTag=1B2M2Y8AsgTpgAmY7PhCfg%7EfA9rXquZc5IkJpXC-Ycixw&d_sfrom=search_fp&d_ckId=5c45d39e4043f9abb7a6f0d46a73b85f&d_curPage=1&d_pageSize=40&d_headId=5c45d39e4043f9abb7a6f0d46a73b85f&curPage=0
第二页URL:
https://www.liepin.com/zhaopin/?init=-1&headckid=3532b9ea0f3b7d78&fromSearchBtn=2&sfrom=click-pc_homepage-centre_searchbox-search_new&ckid=3532b9ea0f3b7d78°radeFlag=0&key=&siTag=1B2M2Y8AsgTpgAmY7PhCfg~fA9rXquZc5IkJpXC-Ycixw&d_sfrom=search_fp&d_ckId=5c45d39e4043f9abb7a6f0d46a73b85f&d_curPage=0&d_pageSize=40&d_headId=5c45d39e4043f9abb7a6f0d46a73b85f&curPage=1
通过对比,不难发现,不同页面的RUL的区别在于最后的curPage的值。
不断点击下面的下一页,发现在未登陆的情况下,最多可以查看10页的数据。
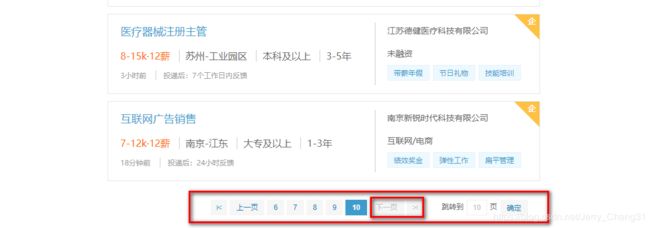
因此,构建爬取要爬取的URL:
for x in range(100):
start_url = 'https://www.liepin.com/zhaopin/?isAnalysis=&dqs=&pubTime=&jobTitles=N000075%2CN000082%2CN000077&salary=&subIndustry=&industryType=&compscale=&key=&init=-1&searchType=1&headckid=5331cc6c28c3b7cf&compkind=&fromSearchBtn=2&sortFlag=15&ckid=5331cc6c28c3b7cf°radeFlag=0&jobKind=&industries=&clean_condition=&siTag=1B2M2Y8AsgTpgAmY7PhCfg%7EfA9rXquZc5IkJpXC-Ycixw&d_sfrom=search_prime&d_ckId=4a035a6b6d76db17ef8aca969d0a892a&d_curPage=2&d_pageSize=40&d_headId=4a035a6b6d76db17ef8aca969d0a892a&curPage={}'.format(x)
2.职位详情页面URL获取
进入到职位列表的审查元素
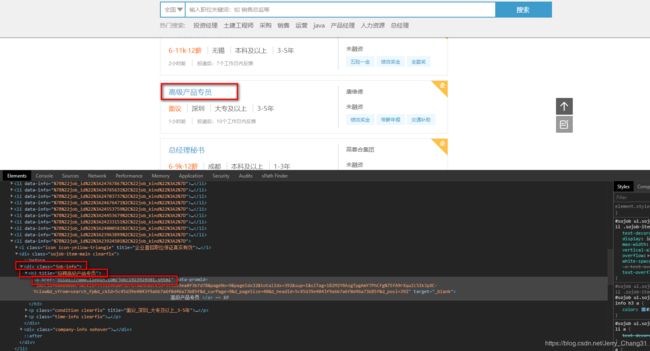
通过定位我们发现,每个职位都在 class=job-info 的 div 标签下的 h3 标签下面的 a 标签,而职位详情的URL即为 a 标签的 href 属性。因此,我们只要获取了所有符合条件的 href 属性,也就获取到了该页所有的职位详情页面的URL。
detil_urls = tree.xpath("//div[@class='job-info']//a[@target='_blank']/@href")
3.职位详情页面分析
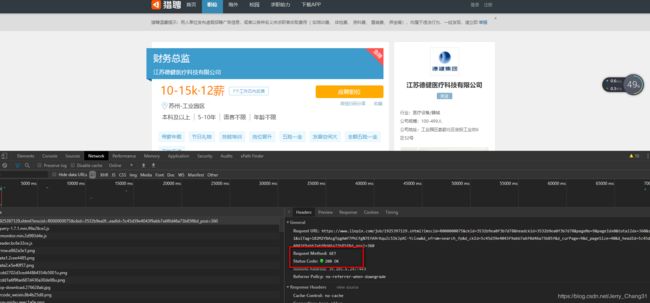
首先,我们可以看到,职位详情页面的请求方式和职位列表页面的请求方式一样,都是通过 get 方法请求。
定位每一个我们要获取的信息,并通过xpath方式获取,如下:
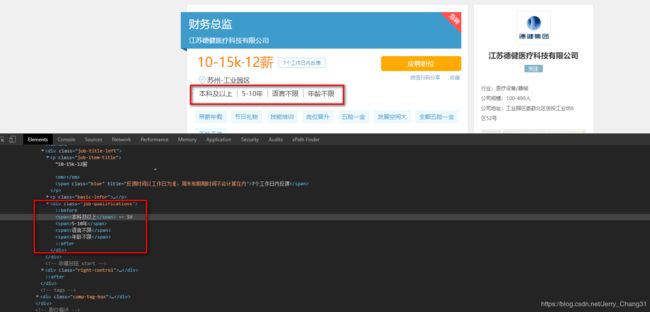
title = tree.xpath("//div[@class='title-info']/h1/text()")[0].strip()
company = tree.xpath("//div[@class='title-info']/h3/a/text()")[0].strip()
salary = tree.xpath("//p[@class='job-item-title']/text()")[0].strip()
location = tree.xpath("//p[@class='basic-infor']/span/text()")[0].strip()
times = tree.xpath("//p[@class='basic-infor']/time/@title")[0].strip()
education = tree.xpath("//div[@class='job-qualifications']//text()")[1].strip()
experience = tree.xpath("//div[@class='job-qualifications']//text()")[3].strip()
language = tree.xpath("//div[@class='job-qualifications']//text()")[5].strip()
age = tree.xpath("//div[@class='job-qualifications']//text()")[7].strip()
contents = tree.xpath("//div[@class='content content-word']/text()")
contents = list(map(lambda content: content.strip(), contents))
contents = "".join(contents)
至此,所有页面解析完毕,开始写代码。
二、代码编写
1.导入相应库
import requests #请求页面
from lxml import etree #解析页面
import time #代码沉睡,防止被发现爬虫,也避免给爬取网站服务器带来压力
import random #后续设置随机请求头会使用
import csv #后续将爬取下来的信息保存为csv文件时使用
from random import choice #设置随机请求头和随机代理时使用
2.设置代理和随机请求头
在爬取时,发现当返回超过一定数据的时候,会返回空数据,猜测可能是网站通过ip或者请求头判断出了此请求可能为爬虫请求,因此设置了代理和随机请求头。
设置代理时,我将可用的代理保存到一个名为 “https_ips_pool.csv” 文件中了。获得代理的代码如下:
def get_proxies(ip_pool_name='https_ips_pool.csv'):
with open(ip_pool_name, 'r') as f:
datas = f.readlines()
ran_num = random.choice(datas)
ip = ran_num.strip().split(',')
proxies = {ip[0]: ip[1] + ':' + ip[2]}
return proxies
设置随机请求头时,我对UA进行了设置,将相应的UA保存到 “user_agent.txt” 文件中,获取请求头的代码如下:
def get_headers():
file = open('user_agent.txt', 'r')
user_agent_list = file.readlines()
user_agent = str(choice(user_agent_list)).replace('\n', '')
user_agent = "Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/78.0.3904.108 Safari/537.36" if len(user_agent) < 20 else user_agent
headers = {
"Accept": "text/html,application/xhtml+xml,application/xml;q=0.9,image/webp,image/apng,*/*;q=0.8,application/signed-exchange;v=b3",
"Accept-Encoding": "gzip, deflate, br",
"Accept-Language": "zh-CN,zh;q=0.9",
"Cache-Control": "max-age=0",
"Connection": "keep-alive",
"Cookie": "__uuid=1576743949178.08; need_bind_tel=false; new_user=false; c_flag=a99aaaa31f739e3b04d3fa768574cabd; gr_user_id=bdb451db-1bc4-4899-a3b3-410b19c06161; bad1b2d9162fab1f80dde1897f7a2972_gr_last_sent_cs1=3872aec89444b8931a667e00ad0d9493; grwng_uid=6c0a08dc-d2e4-407b-b227-89fe9281943e; fe_work_exp_add=true; gr_session_id_bad1b2d9162fab1f80dde1897f7a2972=39311f19-2c25-419e-9a69-64940ae15c78; gr_cs1_39311f19-2c25-419e-9a69-64940ae15c78=UniqueKey%3A3872aec89444b8931a667e00ad0d9493; AGL_USER_ID=15f1f78f-e535-4ccc-8da0-ec0728eb9fb7; abtest=0; __s_bid=5ec9f0f87b044308fb05861763266522a1d4; access_system=C; _fecdn_=1; bad1b2d9162fab1f80dde1897f7a2972_gr_session_id=b500cb67-657d-4f10-9211-7e69d7e319c4; user_roles=0; user_photo=5e7c0e2937483e328d66574804u.jpg; user_name=%E5%B8%B8%E4%BF%8A%E6%9D%B0; fe_se=-1587405434042; Hm_lvt_a2647413544f5a04f00da7eee0d5e200=1586223102,1586753746,1587356899,1587405434; __tlog=1587405434243.54%7C00000000%7CR000000075%7C00000000%7C00000000; UniqueKey=3872aec89444b8931a667e00ad0d9493; lt_auth=7bsJaSdWzg%2Bv4iTRiTBf7fpI3Yr5VmTL%2FX0Mh0gJh4W6W%2FWw4PzqRQiDrbIPxAMhwUxzf8ULNLj5Men%2FznJL7UYQwGmulICyv%2F2k03sEUeVhIsW2vezHg%2FXSQp4ilEAC8nJbpEIL%2BQ%3D%3D; bad1b2d9162fab1f80dde1897f7a2972_gr_last_sent_sid_with_cs1=b500cb67-657d-4f10-9211-7e69d7e319c4; imClientId=deef7ae9f2746887611c3686cabc4d86; imId=deef7ae9f2746887f5aceb762480da5b; imClientId_0=deef7ae9f2746887611c3686cabc4d86; imId_0=deef7ae9f2746887f5aceb762480da5b; bad1b2d9162fab1f80dde1897f7a2972_gr_session_id_b500cb67-657d-4f10-9211-7e69d7e319c4=true; JSESSIONID=8801E5B4E379482E21B82766ACE7C16F; __uv_seq=38; __session_seq=22; bad1b2d9162fab1f80dde1897f7a2972_gr_cs1=3872aec89444b8931a667e00ad0d9493; Hm_lpvt_a2647413544f5a04f00da7eee0d5e200=1587411721; fe_im_socketSequence_0=11_11_11",
"Sec-Fetch-Mode": "navigate",
"Sec-Fetch-Site": "same-origin",
"Sec-Fetch-User": "?1",
"Upgrade-Insecure-Requests": "1",
"User-Agent": user_agent
}
return headers
3.获取职位详情页面URL
每一次请求时,使用随机代理和随机请求头。
def get_detail_url():
for x in range(10):
start_url = 'https://www.liepin.com/zhaopin/?isAnalysis=&dqs=&pubTime=&jobTitles=N000075%2CN000082%2CN000077&salary=&subIndustry=&industryType=&compscale=&key=&init=-1&searchType=1&headckid=5331cc6c28c3b7cf&compkind=&fromSearchBtn=2&sortFlag=15&ckid=5331cc6c28c3b7cf°radeFlag=0&jobKind=&industries=&clean_condition=&siTag=1B2M2Y8AsgTpgAmY7PhCfg%7EfA9rXquZc5IkJpXC-Ycixw&d_sfrom=search_prime&d_ckId=4a035a6b6d76db17ef8aca969d0a892a&d_curPage=2&d_pageSize=40&d_headId=4a035a6b6d76db17ef8aca969d0a892a&curPage={}'.format(x)
while True:
proxies = get_proxies()
response = requests.get(start_url,headers=get_headers(),proxies = proxies)
if response.status_code == 200:
response = response.text
tree = etree.HTML(response)
detil_urls = tree.xpath("//div[@class='job-info']//a[@target='_blank']/@href")
parse_url(detil_urls) #解析函数,在下面定义
time.sleep(1)
break
4.解析职位详情页面
在进行职位详情页面解析时,发现几个问题:
- 公司发布职位和猎头发布职位的 href 属性值不同,公司发布的职位的 href 属性值是完整的URL,而猎头发布的职位的 href 属性值得URL不完整。
- 公司发布职位和猎头发布职位,相同字段(如薪资)所在标签不同,因此需要针对不同的职位进行不同的解析。
- 公司发布的职位中,location 信息有些在
"//p[@class='basic-infor']/span/text()"下索引为0的位置,而有些在索引为1的位置。
因此,针对这些问题,进行判别,分别按照不同的解析方法解析:
def parse_url(detil_urls):
base_url = 'https://www.liepin.com'
positions_list = []
for url in detil_urls:
if url.startswith('http'):
print(url)
while True:
proxies = get_proxies()
try:
text = requests.get(url, headers=get_headers(), proxies=proxies)
if text.status_code == 200:
text = text.text
tree = etree.HTML(text)
title = tree.xpath("//div[@class='title-info']/h1/text()")[0].strip()
company = tree.xpath("//div[@class='title-info']/h3/a/text()")[0].strip()
salary = tree.xpath("//p[@class='job-item-title']/text()")[0].strip()
location = tree.xpath("//p[@class='basic-infor']/span/text()")
if location[0].strip() == '':
location = location[1].strip()
else:
location = location[0].strip()
times = tree.xpath("//p[@class='basic-infor']/time/@title")[0].strip()
education = tree.xpath("//div[@class='job-qualifications']//text()")[1].strip()
experience = tree.xpath("//div[@class='job-qualifications']//text()")[3].strip()
language = tree.xpath("//div[@class='job-qualifications']//text()")[5].strip()
age = tree.xpath("//div[@class='job-qualifications']//text()")[7].strip()
contents = tree.xpath("//div[@class='content content-word']/text()")
contents = list(map(lambda content: content.strip(), contents))
contents = "".join(contents)
positions = {
"title": title,
"company": company,
"salary": salary,
"location":location,
"times":times,
"education": education,
"experience": experience,
"language": language,
"age": age,
"contents": contents
}
positions_list.append(positions)
break
except Exception as t:
print("exception:", t)
else:
url = base_url + url
print(url)
while True:
proxies = get_proxies()
try:
text = requests.get(url,headers=get_headers(),proxies = proxies)
if text.status_code == 200:
text = text.text
tree = etree.HTML(text)
title = tree.xpath("//div[@class='title-info ']/h1/text()")[0].strip()
company = tree.xpath("//div[@class='title-info ']/h3//text()")[0].strip()
salary = tree.xpath("//p[@class='job-main-title']/text()")[0].strip()
location = tree.xpath("//p[@class='basic-infor']/span//text()")[0].strip()
times = tree.xpath("//p[@class='basic-infor']/time/@title")[0].strip()
education = tree.xpath("//div[@class='resume clearfix']//text()")[1].strip()
experience = tree.xpath("//div[@class='resume clearfix']//text()")[3].strip()
language = tree.xpath("//div[@class='resume clearfix']//text()")[5].strip()
age = tree.xpath("//div[@class='resume clearfix']//text()")[7].strip()
contents = tree.xpath("//div[@class='content content-word']/text()")
contents = list(map(lambda content: content.strip(), contents))
contents = "".join(contents)
positions = {
"title": title,
"company": company,
"salary": salary,
"location":location,
"times":times,
"education": education,
"experience": experience,
"language": language,
"age": age,
"contents": contents
}
positions_list.append(positions)
break
except Exception as t:
print("exception:",t)
save_files(positions_list) #存储为csv文件的函数,在后面定义
time.sleep(random.uniform(1, 2))
5.将爬取的信息保存为csv格式的文件
def save_files(positions_list):
headers = ['title','company','salary','location','times','education','experience','language','age','contents']
with open("liepin_spider.csv",'w',encoding='utf-8',newline='') as f:
writer = csv.DictWriter(f,headers)
writer.writeheader()
for positions in positions_list:
writer.writerow(positions)
f.close()
三、requests.exceptions.ConnectionError: (‘Connection aborted.’, LineTooLong(‘got more than 65536 bytes when reading header line’,))异常处理
在进行爬虫的时候,一直有一个报错信息,很久才解决掉,报错信息如下:
raise ConnectionError(err, request=request)
requests.exceptions.ConnectionError: ('Connection aborted.', LineTooLong('got more than 65536 bytes when reading header line',))
这个报错困扰我很久,不知道什么原因,虽然最终解决掉了,但是还是没弄明白,会的人希望可以教我一下。
解决办法:
import http.client
http.client._MAXLINE = 524288 #这个值以前是65536,把它设置大一点就好了
四、完整代码
import requests
from lxml import etree
import time
import random
import csv
from random import choice
import http.client
http.client._MAXLINE = 524288
base_url = 'https://www.liepin.com'
positions_list = []
i = 0
z = 0
def get_proxies(ip_pool_name='https_ips_pool.csv'):
with open(ip_pool_name, 'r') as f:
datas = f.readlines()
ran_num = random.choice(datas)
ip = ran_num.strip().split(',')
proxies = {ip[0]: ip[1] + ':' + ip[2]}
return proxies
def get_headers():
file = open('user_agent.txt', 'r')
user_agent_list = file.readlines()
user_agent = str(choice(user_agent_list)).replace('\n', '')
user_agent = "Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/78.0.3904.108 Safari/537.36" if len(user_agent) < 20 else user_agent
headers = {
"Accept": "text/html,application/xhtml+xml,application/xml;q=0.9,image/webp,image/apng,*/*;q=0.8,application/signed-exchange;v=b3",
"Accept-Encoding": "gzip, deflate, br",
"Accept-Language": "zh-CN,zh;q=0.9",
"Connection": "keep-alive",
"Cookie": "__uuid=1576743949178.08; need_bind_tel=false; new_user=false; c_flag=a99aaaa31f739e3b04d3fa768574cabd; gr_user_id=bdb451db-1bc4-4899-a3b3-410b19c06161; bad1b2d9162fab1f80dde1897f7a2972_gr_last_sent_cs1=3872aec89444b8931a667e00ad0d9493; grwng_uid=6c0a08dc-d2e4-407b-b227-89fe9281943e; fe_work_exp_add=true; gr_session_id_bad1b2d9162fab1f80dde1897f7a2972=39311f19-2c25-419e-9a69-64940ae15c78; gr_cs1_39311f19-2c25-419e-9a69-64940ae15c78=UniqueKey%3A3872aec89444b8931a667e00ad0d9493; AGL_USER_ID=15f1f78f-e535-4ccc-8da0-ec0728eb9fb7; __s_bid=5ec9f0f87b044308fb05861763266522a1d4; imClientId=deef7ae9f2746887611c3686cabc4d86; imId=deef7ae9f2746887f5aceb762480da5b; imClientId_0=deef7ae9f2746887611c3686cabc4d86; imId_0=deef7ae9f2746887f5aceb762480da5b; abtest=0; fe_se=-1588144304556; Hm_lvt_a2647413544f5a04f00da7eee0d5e200=1587405434,1587440994,1587693344,1588144305; UniqueKey=3872aec89444b8931a667e00ad0d9493; lt_auth=vukLOidWzg%2Bv4iTRiTBf7fpI3Yr5VmTL%2FX0Mh0gJh4W6W%2FWw4PzqRQiDrbIPxAMhxxMmI8ULNLj2NOz3wHVI70IQwGmulICyv%2F2k03sEUeVkI8W2vezHg%2FXSQp4ilEAC8nJbpEIL%2BQ%3D%3D; access_system=C; user_roles=0; user_photo=5e7c0e2937483e328d66574804u.jpg; user_name=%E5%B8%B8%E4%BF%8A%E6%9D%B0; bad1b2d9162fab1f80dde1897f7a2972_gr_session_id=01e3d74e-99ae-4fbf-af09-101908fa9115; bad1b2d9162fab1f80dde1897f7a2972_gr_last_sent_sid_with_cs1=01e3d74e-99ae-4fbf-af09-101908fa9115; bad1b2d9162fab1f80dde1897f7a2972_gr_session_id_01e3d74e-99ae-4fbf-af09-101908fa9115=true; __tlog=1588144304624.83%7C00000000%7CR000000058%7Cs_00_t00%7Cs_00_t00; JSESSIONID=A6BB05126EF05E24DC5F8E80F0D3FFFE; __uv_seq=23; __session_seq=23; bad1b2d9162fab1f80dde1897f7a2972_gr_cs1=3872aec89444b8931a667e00ad0d9493; Hm_lpvt_a2647413544f5a04f00da7eee0d5e200=1588151024; fe_im_socketSequence_0=6_6_6",
"Host": "www.liepin.com",
"Referer": "https://www.liepin.com/zhaopin/?industries=&subIndustry=&dqs=&salary=&jobKind=&pubTime=&compkind=&compscale=&industryType=&searchType=1&clean_condition=&isAnalysis=&init=1&sortFlag=15&flushckid=0&fromSearchBtn=1&headckid=b8fa977dd1f04136&d_headId=83d82171062d54a659301a2193fa9e67&d_ckId=83d82171062d54a659301a2193fa9e67&d_sfrom=search_fp_bar&d_curPage=0&d_pageSize=40&siTag=bbL6aoW_xGX8iD8Yj4vLYw%7EfA9rXquZc5IkJpXC-Ycixw&key=",
"Sec-Fetch-Mode": "navigate",
"Sec-Fetch-Site": "same-origin",
"Sec-Fetch-User": "?1",
"Upgrade-Insecure-Requests": "1",
"User-Agent": user_agent
}
return headers
def get_detail_url():
for x in range(100):
start_url = 'https://www.liepin.com/zhaopin/?isAnalysis=&dqs=&pubTime=&jobTitles=N000075%2CN000082%2CN000077&salary=&subIndustry=&industryType=&compscale=&key=&init=-1&searchType=1&headckid=5331cc6c28c3b7cf&compkind=&fromSearchBtn=2&sortFlag=15&ckid=5331cc6c28c3b7cf°radeFlag=0&jobKind=&industries=&clean_condition=&siTag=1B2M2Y8AsgTpgAmY7PhCfg%7EfA9rXquZc5IkJpXC-Ycixw&d_sfrom=search_prime&d_ckId=4a035a6b6d76db17ef8aca969d0a892a&d_curPage=2&d_pageSize=40&d_headId=4a035a6b6d76db17ef8aca969d0a892a&curPage={}'.format(x)
print(start_url)
global z
z += 1
print("现在是第"+str(z)+"页!")
while True:
proxies = get_proxies()
response = requests.get(start_url,headers=get_headers(),proxies = proxies)
if response.status_code == 200:
response = response.text
tree = etree.HTML(response)
detil_urls = tree.xpath("//div[@class='job-info']//a[@target='_blank']/@href")
parse_url(detil_urls)
time.sleep(1)
break
def parse_url(detil_urls):
j = 0
global z
global base_url
global positions_list
for url in detil_urls:
if url.startswith('http'):
print(url)
while True:
proxies = get_proxies()
try:
text = requests.get(url, headers=get_headers(), proxies=proxies)
if text.status_code == 200:
text = text.text
tree = etree.HTML(text)
title = tree.xpath("//div[@class='title-info']/h1/text()")[0].strip()
company = tree.xpath("//div[@class='title-info']/h3/a/text()")[0].strip()
salary = tree.xpath("//p[@class='job-item-title']/text()")[0].strip()
location = tree.xpath("//p[@class='basic-infor']/span/a/text()")
if location[0].strip() == '':
location = location[1].strip()
else:
location = location[0].strip()
# times = tree.xpath("//p[@class='basic-infor']/time/@title")[0].strip()
education = tree.xpath("//div[@class='job-qualifications']//text()")[1].strip()
experience = tree.xpath("//div[@class='job-qualifications']//text()")[3].strip()
language = tree.xpath("//div[@class='job-qualifications']//text()")[5].strip()
age = tree.xpath("//div[@class='job-qualifications']//text()")[7].strip()
contents = tree.xpath("//div[@class='content content-word']/text()")
contents = list(map(lambda content: content.strip(), contents))
contents = "".join(contents)
positions = {
"title": title,
"company": company,
"salary": salary,
"location":location,
# "times":times,
"education": education,
"experience": experience,
"language": language,
"age": age,
"contents": contents
}
positions_list.append(positions)
break
except Exception as t:
print("exception:", t)
else:
url = base_url + url
print(url)
while True:
proxies = get_proxies()
try:
text = requests.get(url,headers=get_headers(),proxies = proxies)
if text.status_code == 200:
text = text.text
tree = etree.HTML(text)
title = tree.xpath("//div[@class='title-info ']/h1/text()")[0].strip()
company = tree.xpath("//div[@class='title-info ']/h3//text()")[0].strip()
salary = tree.xpath("//p[@class='job-main-title']/text()")[0].strip()
location = tree.xpath("//p[@class='basic-infor']/span//text()")[0].strip()
# times = tree.xpath("//p[@class='basic-infor']/time/@title")[0].strip()
education = tree.xpath("//div[@class='resume clearfix']//text()")[1].strip()
experience = tree.xpath("//div[@class='resume clearfix']//text()")[3].strip()
language = tree.xpath("//div[@class='resume clearfix']//text()")[5].strip()
age = tree.xpath("//div[@class='resume clearfix']//text()")[7].strip()
contents = tree.xpath("//div[@class='content content-word']/text()")
contents = list(map(lambda content: content.strip(), contents))
contents = "".join(contents)
positions = {
"title": title,
"company": company,
"salary": salary,
"location":location,
# "times":times,
"education": education,
"experience": experience,
"language": language,
"age": age,
"contents": contents
}
positions_list.append(positions)
break
except Exception as t:
print("exception:",t)
j += 1
print("添加第" + str(z) + "页,第" + str(j) + "条数据!")
global i
i += 1
print("总共" + str(i) + "条数据!")
save_files(positions_list)
time.sleep(random.uniform(1, 2))
def save_files(positions_list):
headers = ['title','company','salary','location','education','experience','language','age','contents']
with open("liepin_spider.csv",'w',encoding='utf-8',newline='') as f:
writer = csv.DictWriter(f,headers)
writer.writeheader()
for positions in positions_list:
writer.writerow(positions)
f.close()
if __name__ == '__main__':
get_detail_url()