你真的懂Mysql吗?一条SQL的执行到底经历了些什么?
你真的懂Mysql吗?一条SQL的执行到底经历了些什么?
我之前花了三两天对Mysql进行了一段时间的学习,当时就觉得Mysql也挺好学的阿,事实上,现在回过头,发现只是学会了一些基本的增删改查而已。
其实想要写出高质量的SQL,还需要对Mysql继续进行深入的学习,下面我将会花上至少一周的时间,深入学习Mysql的底层机制,这样我才能写出高质量的SQL
MySQL的深入学习包括以下几个方面
- Mysql架构原理
- 高性能SQL语句
- 索引及其优化
- 查询的截取分析
- Mysql的锁机制
本篇博客将对Mysql的架构做一个总结,并简单介绍一下两个存储引擎,这也是Mysql调优工作的必备知识
文章目录
- 你真的懂Mysql吗?一条SQL的执行到底经历了些什么?
- Mysql架构分析
- 连接层(Connectors)
- 服务层(Server)
- 引擎层(Pluggable Storage Engines)
- 存储层
- 一条SQL是如何被执行的
- InnoDB与MylSAM
Mysql架构分析
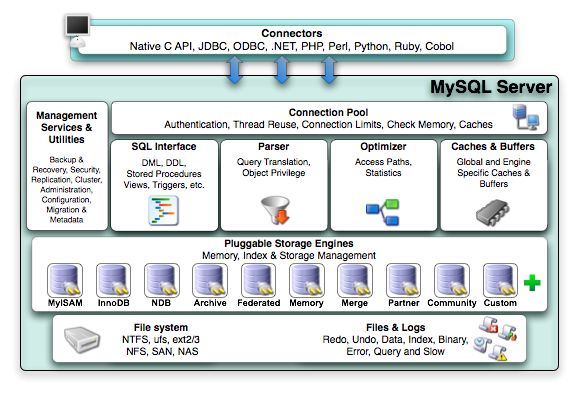
和其他数据库相比,Mysql的特点在于它是一个热插拔式的数据库,在存储引擎上,你可用随时更换你的Mysql存储引擎(主流的存储引擎为MyISAM和InnoDB)
一条SQL下来,所经历的顺序大致如下
连接器-->分析器->优化器->执行器->存储引擎
接下来逐层说明Mysql的架构
连接层(Connectors)
观察上图,你可以看到JDBC,这个东西我们是不是很熟悉,在我之前的博客详细介绍了JDBC
这里有一张图可以直观表达JDBC是个啥玩意
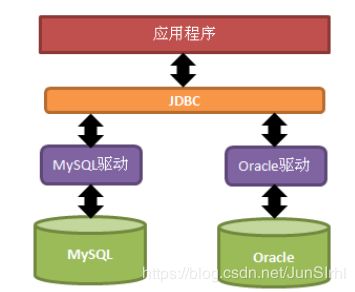
有了JDBC我们就能通过Mysql提供的驱动,连接到Mysql的数据库连接池Connetiontools
我们在使用JDBC时,是不是需要填写数据库的账号密码端口以及要连接的哪个库?那么在Mysql的连接层Connector上,对应用程序发送的连接请求,Mysql会进行验证,包括校验账户密码,权限等操作,如果用户账户密码已通过,连接器会到权限表中查询该用户的所有权限,之后在这个连接里的权限逻辑判断都是会依赖此时读取到的权限数据,也就是说,后续只要这个连接不断开,即时管理员修改了该用户的权限,该用户也是不受影响的
服务层(Server)
里面有以下几个组件
-
Management Services &Ultities : 系统管理和控制工具
-
SQL inteface : SQL接口,接受用户的SQL命令,返回用户查询的结果
-
Cache和Buffer:查询缓存,如果查询缓存中存在你要查询的结果,那么Mysql将会去查询缓存中直接取数据,这个机制包括表缓存、记录缓存、key缓存、权限缓存,需要说明的是,MySQL 查询不建议使用缓存,因为查询缓存失效在实际业务场景中可能会非常频繁,假如你对一个表更新的话,这个表上的所有的查询缓存都会被清空。对于不经常更新的数据来说,使用缓存还是可以的,该组件在Mysql8.0后被移除了
-
Parser:解析器,负责对SQL的解析,解析器主要是用来分析 SQL 语句是来干嘛的,分析分为以下几步:
-
词法分析:提取关键字(select,table,字段…)
-
语法分析:检验sql是否符合语法
mysql会对一条sql语句生成解析树,然后利用mysql语法规则验证
-
-
Optimizer:优化器,要知道你的SQL语句,Mysql不一定会按你的理解来进行查询,而会通过优化器进行一些指令重排,例如你的SQL有where时,优化器会决定先投影还算先过滤,优化器会确定一条SQL语句的执行计划
引擎层(Pluggable Storage Engines)
引擎是什么?
它负责Mysql数据的存储和提取,Mysql服务器通过API与存储引擎通信,不同存储引擎的机制不同,我们可以根据自己的需求选取
Mysql的引擎层是热拔插式的,你可以随便替换引擎,这个点让我感觉非常炫酷
存储层
主要是将数据存储在硬盘之上,并完成与存储引擎的交互
一条SQL是如何被执行的
我们平常构建一条SQL语句,一般通过以下思路构思
select (distinct)
查询字段/'*'
from
<left_table> <join_type> join <right_table> on <join_condition>
where
<where_condition>
group by
<group by_list>
having
<having_conditon>
order by
<order by_condition>
limit
<limit_number>
如果看不懂这段通用伪代码,证明你的SQL不过关,请看我的另一篇博客
SQL-增删改查一锅端
那么,优化器是如何确定SQL的执行计划的?一般来说,优化器会这么去理解
from <left_table> 确定表
on <join_conditon> 连接条件
<join_type> join <right_table> 确定左右外连接类型及连接的表
where <where condition> where之后的条件
group by <group by_list> 按什么字段分组
having <having_conditon> 分组条件
select 确定查询操作
distinct 是否去重
order by<order by_condition>
limit <limit_number>
对应的解析图如下

当然,这知识优化器觉得是最优的执行顺序,根据优化器的版本不同,顺序也会发生改变
知道了以上这些架构知识,接下来让我们来看看,我们平常一条SQL,Mysql是如何处理的吧
先来一条具体的查询SQL
select * from user u where u.age='18' and age='张三' ;
-
连接器检查权限,无权限返回,有权限的查询缓存,有缓存返回结果,无则下一步
-
Server中的分析器进行分析,提取select,表名user,字段age,name
-
Server中优化器确定执行方案
1.先查询学生表中姓名为“张三”的学生,然后判断是否年龄是 18 2.先找出学生中年龄 18 岁的学生,然后再查询姓名为“张三”的学生 -
权限校验,无权限返回错误信息,否则调用SQL inteface
总结如下:
权限校验—>(查询缓存)—>分析器—>优化器—>权限校验—>执行器—>引擎
我们知道SQL的不止select语句,还有其他语句,除了查询之外的语句,我们称更新语句,它们的执行其实也是大同小异的,不再具体说明
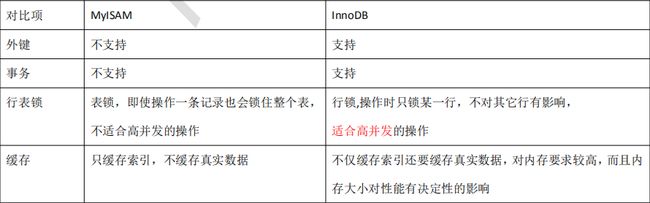
InnoDB与MylSAM
这两个存储引擎是目前Mysql最主流的存储引擎,Mysql默认安装的是InnoDB,比较一下这两个存储引擎:

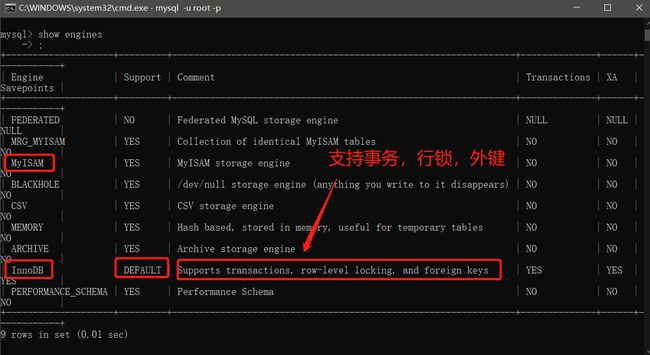
我们可以查看mysql有哪些存储引擎
- 打开命令行
- 输入
mysql -u root -p - 输入密码
- 使用命令:
show engines;
先介绍到这里,本文梳理了Mysql的架构体系,以及一条SQL的执行经历了什么,最后介绍了两个搜索引擎,万丈高楼平地起,有了这个底子,再过渡到后面的各种调优,就顺理成章了!后面的内容请关注我后续博客哈