LVS 负载均衡器理论基础及抓包分析
LVS 是 Linux Virtual Server 的简写,即 Linux 虚拟服务器,是一个虚拟的服务器集群系统。本项目在1998年5月由章文嵩博士成立,是中国国内最早出现的自由软件项目之一。(百科)
kube-proxy 的ipvs模式是 2015年由k8s社区大佬thockin提出的(https://github.com/kubernetes/kubernetes/issues/17470),在2017年由华为云团队实现的(https://github.com/kubernetes/kubernetes/issues/44063),在kubernetes v1.8中已经引入了ipvs模式。
ipvs模式的实现也是实现了ipvsadm这个核心组件,由于我们都使用LVS,对这个组件都有所了解,这里简单做下总结。
LVS 基础
LVS 核心组件
ipvsadm:用户空间的命令行工具,用于管理集群服务及集群服务上的RS等;(管理工具)
ipvs:工作于内核上的程序,可根据用户定义的集群实现请求转发;(内核模块)
LVS 专业术语
VS:Virtual Server (虚拟服务)
DS:Director Server(负载均衡器)
RS:Real Server (后端真实处理请求的服务器)
CIP: Client IP (用户端IP)
VIP:Director Virtual IP (负载均衡器虚拟 IP)
DIP:Director IP (负载均衡器 IP)
RIP:Real Server IP (后端请求处理服务器 IP)
工作原理
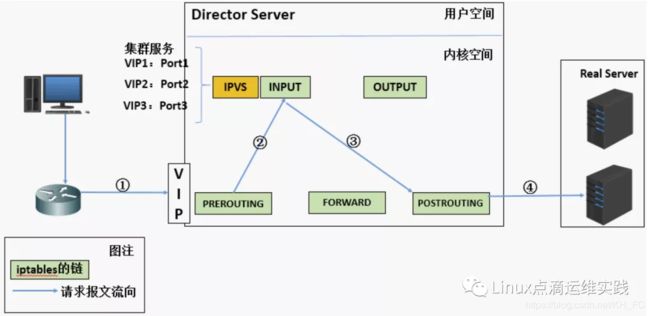
IPVS 是工作在 INPUT 链上的,当用户请求到达 INPUT 链时,IPVS 会将用户请求与自己已定义好规则进行比对,如果用户请求的就是定义的集群服务,那么此时 IPVS 会强行修改数据包里的目标 IP 地址及端口,并将新的数据包发往 POSTROUTING 链;
ipvs (IP Virtual Server) 实现了4层负载均衡,ipvs 运行在主机上,在Real Server 集群前充当LB(负载均衡器),ipvs 将基于 TCP 和 UDP 的服务请求转发到真实服务器上,并使真实服务器上面的服务,能够在前面 Director Server上、通过提供的 VIP 对外提供服务。
LVS 常用算法
RR(Round Robin):轮询调度,在不考虑每台服务器处理能力的情况下,轮询调度算法是把来自用户的请求轮流分配给内部中的服务器,从1开始,直到N(内部服务器个数),然后重新开始循环;
WRR(Weight Round Robin):加权轮询,由于每台服务器的配置、跑业务类型不同,其处理能力也会不同,所以我们根据服务器的不同处理能力,给每个服务器分配不同的权值,使其能够接受相应权值数据的服务请求;
DH(Destination hashing):目标地址散列,根据请求的目标IP地址,作为散列键(Hash Key)从静态分配的散列表找出对应的服务器,若该服务器是可用的且未超载,将请求发送到该服务器,否则返回空;
SH(Source Hashing):源地址散列,主要实现会话绑定,能够将此前建立的session信息保留了,根据请求的源IP地址,作为散列键(Hash Key)从静态分配的散列表找出对应的服务器,若该服务器是可用的且未超载,将请求发送到该服务器,否则返回空;
LC(Least Connections):最少链接,将网络请求调度到已建立的链接数最少的服务器上。如果集群系统的真实服务器具有相近的系统性能,采用“最小连接”调度算法可以较好地均衡负载;
WLC(Weighted Least Connections):加权最少链接,在集群系统中的服务器性能差异较大的情况下,调度器采用“加权最少链接”调度算法优化负载均衡性能,具有较高权值的服务器将承受较大比例的活动连接负载,调度器可以自动问询真实服务器的负载情况,并动态地调整其权值;
除上面一些常用调度算法外,还有一些几个,如下:LBLC(Locality-Based Least Connections)基于局部性的最少链接、LBLCR(Locality-Based Least Connections with Replication)带复制的基于局部性最少链接、SED(Shortest Expected Delay Scheduling)最短的期望的延迟、NQ(Never Queue Scheduling NQ)最少队列调度;
LVS 模式
DR、NAT、隧道模式;(后面重点讲解)
LVS 组件安装
yum -y install ipvsadm
ipvsadm 常用配置参数
-A 添加虚拟服务VIP
-D 删除虚拟服务VIP
-L 查看虚拟服务VIP
-C 清除所有虚拟服务VIP
-t 指定虚拟服务及端口 VIP:Port
-r 指定真实服务及端口 RS:Port
-s 指定算法,rr(轮询)、wrr(加权轮询)、lc(最少连接)、sh(源地址散列)、dh(目标地址散列) 等等
-w 指定权重
-m 指定转发模式为NAT
-g 指定转发模式为DR
-i 指定转发模式为IPIP隧道
NAT 模式
报文请求过程图
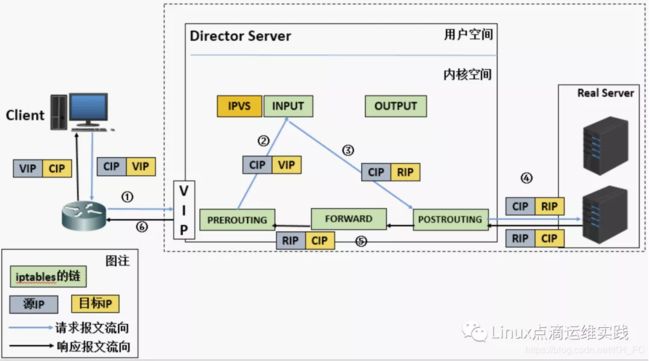
报文请求过程分析
- 当用户请求到达 DS 时,请求报文会先经过内核空间中的 PREROUTING 链,此时源 IP 为CIP,目的 IP 为 VIP;
- 在 PREROUTING 规则链上进行检查目的IP是否为本机,如果是的话将数据包送至 INPUT 链;
- 数据包到达INPUT链后,IPVS 会比对数据包请求的服务是否为集群服务,若是,修改数据包的目标 IP 地址为后端服务器 IP(这里需要根据各种算法计算,哪台 RS 更合适),再将数据包发至 POSTROUTING 链,此时报文的源 IP 为 CIP,目标 IP 为 RIP;
- POSTROUTING 链的作用就是选路,根据 INPUT 链中目标 IP,将数据包发送给 RS;
- RS 发现数据包中的目标 IP 是自己的 IP,此时它会开始构建响应报文发并回给 DS, 此时报文的源IP为RIP,目标IP为 CIP;
- DS 收到 RS 响应后,但在响应客户端,会将源 IP 地址修改为自己的 VIP 地址,然后发送给客户端,此时报文的源 IP 为 VIP,目标 IP 为 CIP;
NAT 实验
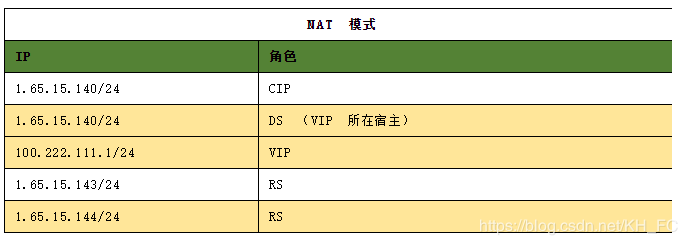
NAT 模式时,LB 节点IP与RS节点IP可以不在同一个网络内,现为了模拟我们在 LB 节点添加一虚拟IP 如下,并测试连通性。
[root@master02 ~]# ip addr add 100.222.111.1/24 dev ens32
[root@master02 ~]# ip a
1: lo: <LOOPBACK,UP,LOWER_UP> mtu 65536 qdisc noqueue state UNKNOWN group default qlen 1000
link/loopback 00:00:00:00:00:00 brd 00:00:00:00:00:00
inet 127.0.0.1/8 scope host lo
valid_lft forever preferred_lft forever
2: ens32: <BROADCAST,MULTICAST,UP,LOWER_UP> mtu 1500 qdisc pfifo_fast state UP group default qlen 1000
link/ether 00:50:56:8e:53:c1 brd ff:ff:ff:ff:ff:ff
inet 1.65.15.141/24 brd 1.65.15.255 scope global ens32
valid_lft forever preferred_lft forever
inet 100.222.111.1/24 scope global ens32
valid_lft forever preferred_lft forever
3: docker0: <NO-CARRIER,BROADCAST,MULTICAST,UP> mtu 1500 qdisc noqueue state DOWN group default
link/ether 02:42:46:24:ae:8c brd ff:ff:ff:ff:ff:ff
inet 172.17.0.1/16 brd 172.17.255.255 scope global docker0
valid_lft forever preferred_lft forever
[root@master02 ~]# ping -c 1 100.222.111.1
PING 100.222.111.1 (100.222.111.1) 56(84) bytes of data.
64 bytes from 100.222.111.1: icmp_seq=1 ttl=64 time=0.033 ms
--- 100.222.111.1 ping statistics ---
1 packets transmitted, 1 received, 0% packet loss, time 0ms
rtt min/avg/max/mdev = 0.033/0.033/0.033/0.000 ms
[root@master02 ~]#
创建负载均衡service
[root@master02 ~]# ipvsadm -A -t 100.222.111.1:8000 -s rr
[root@master02 ~]#
添加 RS 到指定的负载均衡器下
[root@master02 ~]# ipvsadm -a -t 100.222.111.1:8000 -r 1.65.15.143:80 -m
[root@master02 ~]# ipvsadm -a -t 100.222.111.1:8000 -r 1.65.15.144:80 -m
[root@master02 ~]#
在client上面访问VIP
[root@master01 ~]# ping -c 1 100.222.111.1
PING 100.222.111.1 (100.222.111.1) 56(84) bytes of data.
--- 100.222.111.1 ping statistics ---
1 packets transmitted, 0 received, 100% packet loss, time 0ms
[root@master01 ~]#
我们发现并不通,由于这个VIP是虚拟的,需要添加路由,添加静态路由如下。
[root@master01 ~]# ip route add 100.222.111.1 via 1.65.15.141 dev ens32
[root@master01 ~]#
继续测试连通性
[root@master01 ~]# ping -c 1 100.222.111.1
PING 100.222.111.1 (100.222.111.1) 56(84) bytes of data.
64 bytes from 100.222.111.1: icmp_seq=1 ttl=64 time=0.088 ms
--- 100.222.111.1 ping statistics ---
1 packets transmitted, 1 received, 0% packet loss, time 0ms
rtt min/avg/max/mdev = 0.088/0.088/0.088/0.000 ms
[root@master01 ~]#
发现可以ping通了,我们接下来验证service
[root@master01 ~]# curl -m 15 --retry 1 -sSL 100.222.111.1:8000
curl: (28) Connection timed out after 15001 milliseconds
[root@master01 ~]#
LB抓包

RS 抓包如下

数据包的源IP为CIP,目标IP为RIP,LB节点 IPVS 只做了 DNAT,只是把目标IP改成RS IP了,而没有修改源IP。此时虽然RS和CIP(client)在同一个子网,链路连通性没有问题,但是由于 CIP 节点发出去的包的目标IP和收到的包源IP不一致,因此会被直接丢弃,所以需要在iptables 上做地址伪装。
[root@master02 ~]# iptables -t nat -A POSTROUTING -m ipvs --vaddr 100.222.111.1 --vport 8000 -j MASQUERADE
[root@master02 ~]# iptables -t mangle -A POSTROUTING -m ipvs --vaddr 100.222.111.1 --vport 8000 -j LOG --log-prefix '[k8svip ipvs]'
[root@master02 ~]#
上面我们在LB节点做地址伪装,并且把经过iptables的转发日志记录下来,这里需要注意,只能在mangle表才能记录,在nat表时,无法记录转发日志,再次测试,发现依然不通;
[root@master01 ~]# curl -m 15 --retry 1 -sSL 100.222.111.1:8000
curl: (28) Connection timed out after 15001 milliseconds
[root@master01 ~]#
哪问题出在什么地方呢?由于PROC文件系统的/proc/sys/net/ipv4/vs/conntrack可控制IPVS是否对其连接启用Netfilter系统的conntrack功能,默认情况下是关闭状态,这里需要打开,如下。
[root@master02 ~]# sysctl net.ipv4.vs.conntrack=1
net.ipv4.vs.conntrack = 1
[root@master02 ~]#
下面这个图是是否开启conntrack功能的iptables日志对比,上面只是SYN,根本无法完成三次握手,缺少链路追踪,这里需要再开启conntrack功能。
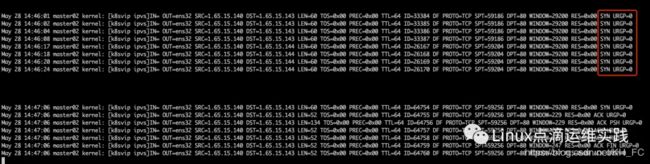
再次测试,成功。
[root@master01 ~]# curl -m 15 --retry 1 -sSL 100.222.111.1:8000
Welcome to nginx!
。。。。。
nginx.com.
Thank you for using nginx.
[root@master01 ~]#
RS 抓包

LB抓包

到这里nat实验就完成了,可以看下数据包,源IP已经变成了LB的IP。
NAT 特性总结
- RS 的 RIP 与 DS 的 DIP 必须使用相同网段的私网地址,并且 RS 的网关要指向 DS 的 DIP;
- 客户端的请求和响应报文都要经由 DS 转发,在大并发、大流量的场景中,DS有可能会成为系统瓶颈;
- 支持端口映射;
DR 模式
报文请求过程图
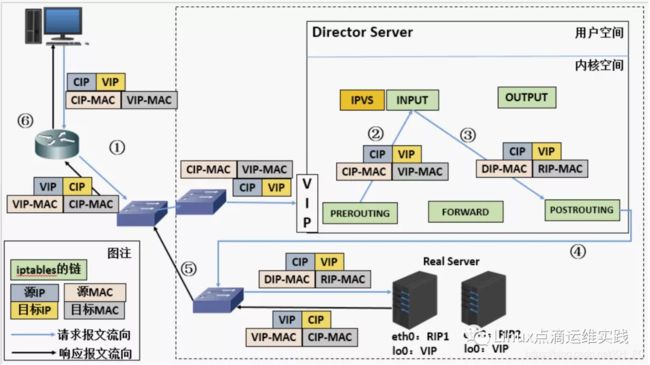
报文请求过程分析
- 当用户请求到达 DS 时,请求报文会先经过内核空间中的 PREROUTING 链,此时源IP为CIP,目的 IP 为 VIP;
- 在 PREROUTING 规则链上进行检查目的IP是否为本机,如果是的话将数据包送至 INPUT 链;
- 数据包到达INPUT链后,IPVS 会比对数据包请求的服务是否为集群服务,若是,将请求报文中的源 MAC 地址修改为 DIP 的 MAC 地址,将目标 MAC 地址修改 RIP 的 MAC 地址(这里需要IPVS根据策略算法选择一台合适的 RS 的 MAC 地址),然后再将数据包发至 POSTROUTING 链, 此时的源 IP 和目标 IP 均未修改,仅修改了源和目的的MAC地址(DR 模式要求 DS 与 RS 也必须是同一个物理网络中,可公、可私);
- POSTROUTING链检查目标 MAC 地址为 哪一个 RIP 的 MAC 地址,选择后,再把数据包将会发给 RS;
- RS 发现请求报文的 MAC 地址是自己的 MAC 地址,就接收此报文并处理,将响应报文通过 lo 接口传送给 eth0 网卡然后向外发出,此时的源IP地址为VIP,目标IP为CIP;
- 响应报文最终到客户端;
DR 实验

从DR模式原理可知,调度器只是修改请求报文的目的mac(二层转发),这就要求调度器和RS需要在同一个网段,并且也无需要开启ip_forward,所以需要分配一个同网段的IP 做为VIP;
[root@master02 ~]# ping -c 1 1.65.15.145
PING 1.65.15.145 (1.65.15.145) 56(84) bytes of data.
From 1.65.15.141 icmp_seq=1 Destination Host Unreachable
--- 1.65.15.145 ping statistics ---
1 packets transmitted, 0 received, +1 errors, 100% packet loss, time 0ms
[root@master02 ~]#
添加 VIP 网卡信息
[root@master02 ~]# ifconfig ens32:0 1.65.15.145/24 up
[root@master02 ~]#
创建 service 负载均衡
[root@master02 ~]# ipvsadm -A -t 1.65.15.145:80 -s rr
[root@master02 ~]#
把 RS 添加到负载均衡
[root@master02 ~]# ipvsadm -a -t 1.65.15.145:80 -r 1.65.15.143:80 -g
[root@master02 ~]# ipvsadm -a -t 1.65.15.145:80 -r 1.65.15.144:80 -g
[root@master02 ~]#
客户端连通性测试
[root@master01 ~]# ping -c 1 1.65.15.145
PING 1.65.15.145 (1.65.15.145) 56(84) bytes of data.
64 bytes from 1.65.15.145: icmp_seq=1 ttl=64 time=0.078 ms
--- 1.65.15.145 ping statistics ---
1 packets transmitted, 1 received, 0% packet loss, time 0ms
rtt min/avg/max/mdev = 0.078/0.078/0.078/0.000 ms
[root@master01 ~]#
负载测试
[root@master01 ~]# curl -m 15 --retry 1 -sSL 1.65.15.145:80
curl: (7) Failed connect to 1.65.15.145:80; 没有到主机的路由
[root@master01 ~]#
发现负载服务不通,进行抓包分析
dr模式LB抓包

dr模式RS抓包

根据 DR 模式路由转发原理,LB上面源MAC地址修改为LB的MAC地址,而目标MAC地址修改为RS MAC地址,上图中已经发现MAC正常修改了,但为什么不通呢?在RS数据包中发现源IP和目标IP也都未修改,那么问题来了,我们Client期望访问的是RS(通过 mac 二次互访),但RS收到的目标IP却是LB上面的VIP,发现这个目标IP并不是自己的IP,因此不会通过 INPUT 链转发到用户空间,这时要不直接丢弃这个包,要不根据路由再次转发到其他地方,总之两种情况都不是我们期望的结果。那怎么办呢?如果想让RS接收这个包,必须得让RS有这个目标IP才行,不妨在lo上添加个虚拟IP,IP地址伪装成LB IP 1.65.15.145。所以需要在RS上面添加虚拟IP,并且添加一条路由如下。
[root@master03 ~]# ifconfig lo:0 1.65.15.145/32 up
[root@master03 ~]# route add -host 1.65.15.145 dev lo
[root@master03 ~]#
此时问题又来了,这就相当于在一个局域网内有两个相同的IP,IP重复了怎么办?办法就是隐藏这个虚拟网卡,不让它回复ARP,其他主机的neigh也就不可能知道有这么个网卡的存在了。
[root@node01 ~]# echo 1 > /proc/sys/net/ipv4/conf/lo/arp_ignore
[root@node01 ~]# echo 2 > /proc/sys/net/ipv4/conf/lo/arp_announce
[root@node01 ~]#
arp_ignore=1,只响应目的IP地址为接收网卡上的本地地址的arp请求。
因为我们在RS上都配置了VIP,因此此时是存在IP冲突的,当外部客户端向VIP发起请求时,会先发送arp请求,此时调度器和RS都会响应这个请求。如果某个RS响应了这个请求,则之后该客户端的请求就都发往该RS,并没有经过LVS,因此也就没有真正的负载均衡,LVS也就没有存在的意义。因此我们需要设置RS不响应对VIP的arp请求,这样外部客户端的所有对VIP的arp请求才会都解析到调度器上,然后经由LVS的调度器发往各个RS。
系统默认arp_ignore=0,表示响应任意网卡上接收到的对本机IP地址的arp请求(包括环回网卡上的地址),而不管该目的IP是否在接收网卡上。也就是说,如果机器上有两个网卡设备A和B,即使在A网卡上收到对B IP的arp请求,也会回应。而arp_ignore设置成1,则不会对B IP的arp请求进行回应。由于lo肯定不会对外通信,所以如果只有一个对外网口,其实只要设置这个对外网口即可,不过为了保险,很多时候都对all也进行设置。
arp_announce=2,网卡在发送arp请求时使用出口网卡IP作为源IP。
当RS处理完请求,想要将响应发回给客户端,此时想要获取目的IP对应的目的MAC地址,那么就要发送arp请求。arp请求的目的IP就是想要获取MAC地址的IP,那arp请求的源IP呢?自然而然想到的是响应报文的源IP地址,但也不是一定是这样,arp请求的源IP是可以选择的,而arp_announce的作用正是控制这个地址如何选择。系统默认arp_announce=0,也就是源ip可以随意选择。这就会导致一个问题,如果发送arp请求时使用的是其他网口的IP,达到网络后,其他机器接收到这个请求就会更新这个IP的mac地址,而实际上并不该更新,因此为了避免arp表的混乱,我们需要将arp请求的源ip限制为出口网卡ip,因此需要设置arp_announce=2。(解释来源于网络)
测试连通性
[root@master01 ~]# curl 1.65.15.145:80
<!DOCTYPE html>
<html>
<head>
<title>Welcome to nginx!</title>
<style>
。。。。
<p><em>Thank you for using nginx.</em></p>
</body>
</html>
[root@master01 ~]#
RS抓包如下
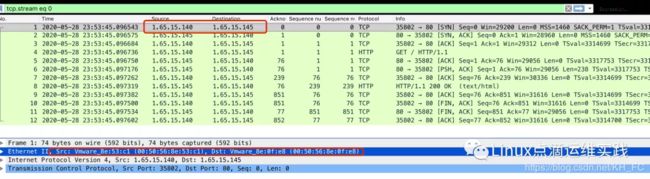
LB抓包如下

通过数据包分析可以发现MAC地址的转换,及源目标IP的转换关系,到此这个DR实验完成。
DR 模式特性总结
- 前端路由器将目标 IP 为 VIP 时的请求报文,发往DS,需要在前端网关做静态绑定,RS上使用 arptables,并且在RS上修改内核参数以限制 arp 通告及应答级别;
- 修改 RS 上内核参数(arp_ignore和arp_announce)将 RS 上的 VIP 配置在 lo 接口的别名上,并限制其不能响应对 VIP 地址解析请求;
- RS 的 RIP 可以使用私网地址,也可以是公网地址,但 RIP 与 DIP 必须在同网络内,RIP 的网关不需要也不能指向 DIP,以确保响应报文不会经由 DS;
- 请求报文要经由 DS,但响应时不经过 DS,而是由 RS 直接发往 客户端;
- DR 模式不支持端口映射;
IPIP 模式
报文请求过程图
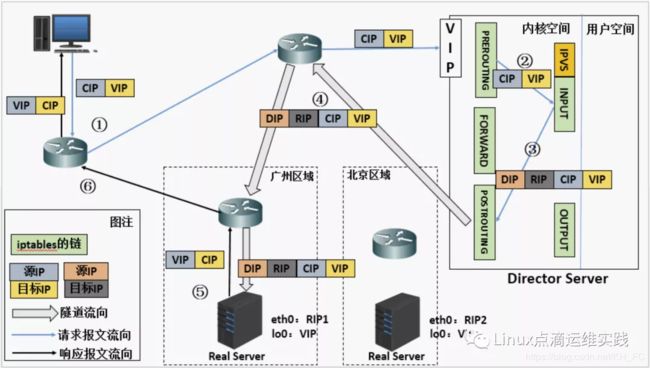
报文请求过程分析
- 当用户请求到达 DS 时,请求报文会先经过内核空间中的 PREROUTING 链,此时源IP为CIP,目的 IP 为 VIP;
- 在 PREROUTING 规则链上进行检查目的IP是否为本机,如果是的话将数据包送至 INPUT 链;
- 数据包到达INPUT链后,IPVS 会比对数据包请求的服务是否为集群服务,若是,在请求报文的首部再次封装一层 IP 报文,封装源 IP 为 DIP,目标 IP 为 RIP,然后发至POSTROUTING链,此时源 IP 为 DIP,目标 IP 为 RIP;
- POSTROUTING 链根据最新封装的 IP 报文,将数据包发至 RS(因为在外层封装多了一层IP首部,所以可以理解为此时通过隧道传输);此时源 IP 为 DIP,目标 IP 为 RIP;
- RS 接收到报文后发现是自己的 IP 地址,就将报文接收下来,拆除掉最外层的 IP 后,会发现里面还有一层 IP 首部,而且目标是自己的 lo 接口 VIP,那么此时 RS 开始处理此请求,处理完成之后,通过 lo 接口送给 eth0 网卡,然后向外传递,此时的源 IP 地址为 VIP,目标 IP 为 CIP;
- 响应报文最终送达至客户端;
IPIP 实验
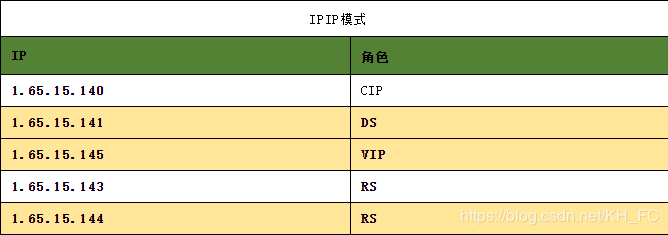
DR 模式是通过MAC地址进行交换,只能限制在一个局域网内,而TUN隧道方式 ,是通过给数据包加上新的IP头部来实现,这个可以跨机房(可以实现异地容灾)、跨公网、主要是解决不能跨网的问题;
添加 VIP 网卡信息
# 配置 VIP
[root@master02 ~]# ifconfig ens32:1 1.65.15.145 netmask 255.255.255.0 up
# 测试连通性
[root@master02 ~]# ping -c 1 1.65.15.145
PING 1.65.15.145 (1.65.15.145) 56(84) bytes of data.
64 bytes from 1.65.15.145: icmp_seq=1 ttl=64 time=0.026 ms
--- 1.65.15.145 ping statistics ---
1 packets transmitted, 1 received, 0% packet loss, time 0ms
rtt min/avg/max/mdev = 0.026/0.026/0.026/0.000 ms
[root@master02 ~]#
创建负载均衡
[root@master02 ~]# ipvsadm -A -t 1.65.15.145:80 -s rr
[root@master02 ~]#
添加RS到LB
# 添加 RealServer 作为 VIP 的后端
[root@master02 ~]# ipvsadm -a -t 1.65.15.145:80 -r 1.65.15.143:80 -i
[root@master02 ~]# ipvsadm -a -t 1.65.15.145:80 -r 1.65.15.144:80 -i
[root@master02 ~]#
负载均衡器(LB)要开启转发功能
[root@master02 ~]# echo 1 >/proc/sys/net/ipv4/ip_forward
[root@master02 ~]#
查看负载情况
[root@master02 ~]# ipvsadm -L -n
IP Virtual Server version 1.2.1 (size=4096)
Prot LocalAddress:Port Scheduler Flags
-> RemoteAddress:Port Forward Weight ActiveConn InActConn
TCP 1.65.15.145:80 rr
-> 1.65.15.143:80 Tunnel 1 0 0
-> 1.65.15.144:80 Tunnel 1 0 0
[root@master02 ~]#
RealServer 配置tunl0 (所有RS服务器)
# 加载下 tunl 模式
[root@node01 ~]# modprobe ipip
# 为 tunl0 网口配置 IP(即VIP)
[root@node01 ~]# ifconfig tunl0 1.65.15.145 netmask 255.255.255.255 up
[root@node01 ~]#
修改内核参数(所有RS服务器)
[root@node01 ~]# echo 0 > /proc/sys/net/ipv4/ip_forward
[root@node01 ~]# echo 1 > /proc/sys/net/ipv4/conf/tunl0/arp_ignore
[root@node01 ~]# echo 2 > /proc/sys/net/ipv4/conf/tunl0/arp_announce
[root@node01 ~]# echo 1 > /proc/sys/net/ipv4/conf/all/arp_ignore
[root@node01 ~]# echo 2 > /proc/sys/net/ipv4/conf/all/arp_announce
[root@node01 ~]# echo 0 > /proc/sys/net/ipv4/conf/tunl0/rp_filter
[root@node01 ~]# echo 0 > /proc/sys/net/ipv4/conf/all/rp_filter
arp_ignore 与 arp_announce上面已经有详细说明,这里说下rp_filter,官方说明 https://www.kernel.org/doc/Documentation/networking/ip-sysctl.txt
rp_filter 参数主要是用于控制系统是否开启对数据包源地址的校验,它有3个值,0、1、2。
0:不开启源地址检验;
1:开启严格的反向路径校验,对每个入访的数据包,通过指定网卡,校验其出访路径是否为最佳路径,如果不是最佳路径,则直接丢弃;(Linux 服务器默认是1)
2:开启松散的反向路径校验,对每个进来的数据包,通过任意网口,校验其源地址是否可达,即反向路径是否能通,如果不通,则丢弃;
其实这个参数和安全也息息相关:
- Distribute Deny of Service 即 分布式拒绝服务攻击,原理就是通过构造大量的无用数据包向目标服务发起请求,占用目标服务主机大量的资源,还可能造成链路上面网络拥塞,进而影响到正常用户的访问,我们把这个参数设为1,严格校验数据包的反向路径,如果出访路径不合适,就直接丢弃数据包,这样避免过多的无效连接消耗Linux系统资源;
- IP Spoofing 即 IP 欺骗,是指客户端通过伪造源IP,冒充另外一个客户端与目标服务进行通信,从而达到劫持的目的,如果我们把参数设为1,严格校验数据包的反向路径,如果客户端伪造的源IP地址对应的反向路径不在路由表中,或者反向路径不是最佳路径,则直接丢弃数据包,不会向伪造IP的客户端回复响应。
测试访问
[root@master01 ~]# curl -m 15 --retry 1 -sSL http://1.65.15.145
<!DOCTYPE html>
<html>
<head>
。。。
<p><em>Thank you for using nginx.</em></p>
</body>
</html>
[root@master01 ~]#
RS 抓包
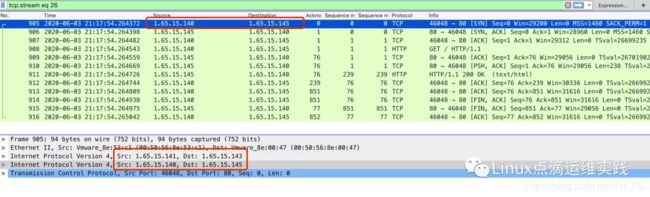
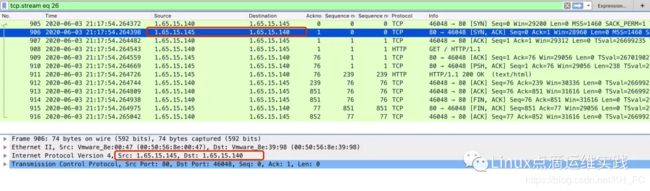
通过RS抓包,可以清楚看出IPIP隧道数据包封装的格式,但回包的时候,直接就回了;
DS抓包(转发server)
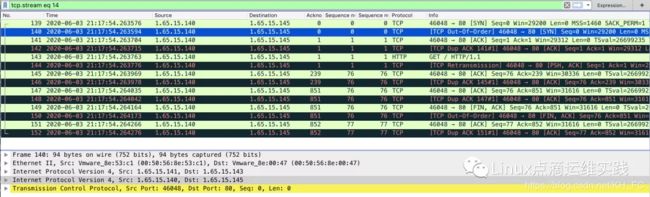
这个数据包,感觉有问题,后面我再查下,分析下原因,如果有人知道,也可交流;
IPIP 特性总结
- DIP, VIP, RIP 都应该是公网地址;
- RS 的网关不能、也不可能指向DIP;
- 请求报文要经由 DS,但响应不经过 DS;
- 不支持端口映射;
- RS 的 OS 得支持隧道功能;
总结
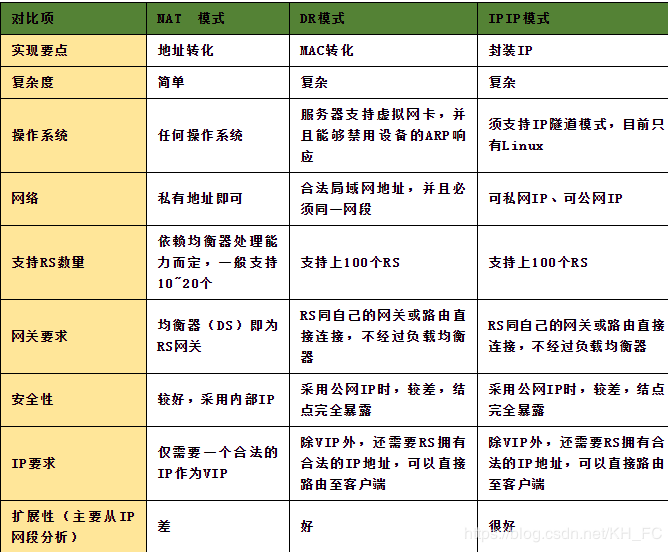
由于各个公司实际情况不同、业务类型不同、容灾策略、基础架构不同,需要结合自己公司的情况进行分析,然后选择合适的解决方案。
本文摘自Linux云计算网络
8小时Python零基础轻松入门