关于《后浪》的B站弹幕分析总结(一)——爬取B站视频的上万条弹幕的方法
目录
- 一、先尝试爬取1000条
- 1 .1 查找弹幕所在地址
- 1.2 代码实现
- 二、1000条不够我想要更多怎么办?
- 三、B站弹幕文件里的其他信息有用吗?
注意:这是一篇技术类文章
前几天我做了B站《后浪》视频的弹幕分析,感兴趣的朋友可以看一下《[数说弹幕]我不小心看了后浪弹幕》
现在我将在制作这个视频背后用到的文本分析相关的关键技术点做一个总结,因为涉及知识点太多,有些点会一笔带过,着重讲一些主要的点。
我把每一个知识点都分为理论介绍和代码实现,如果对理论非常熟悉的可以跳过介绍部分直接看代码。
一、先尝试爬取1000条
为什么只有1000条,因为B站视频限制了弹幕显示数量,也就是一个视频一天最多显示弹幕数量是1000条。就拿《后浪》举例吧:
1 .1 查找弹幕所在地址
首先我们使用Google Chrome打开哔哩哔哩网页并选择要爬取弹幕的视频

如果要爬取弹幕就要先看看弹幕在哪里,所以按F12打开开发者工具。
如果你找了半天没找到那就对了,因为视频没有播放的情况下你是不会看到弹幕的,所以要先播放视频。你会发现在Network—XHR下多了好多条记录,弹幕一定在里面了。
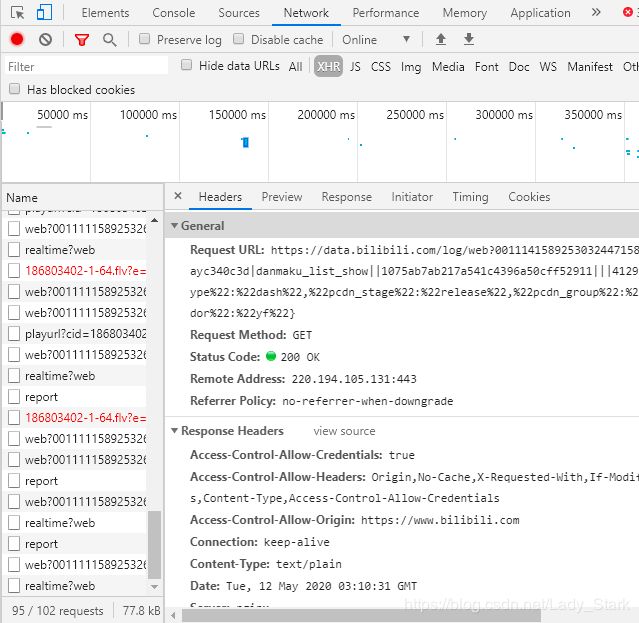
观察可以发现出现次数最多的是一个一长串的数字,在这个列表里面是186803402,这就是视频的cid。输入包含这个cid的网址:
https://comment.bilibili.com/186803402.xml
你会发现弹幕就在里。
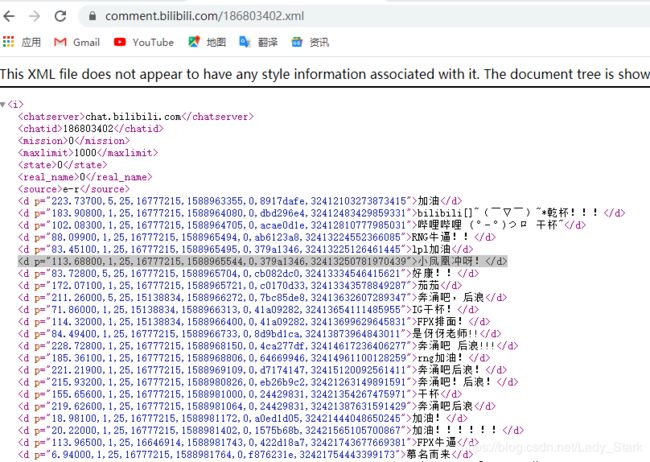
但是可要注意了其中maxlimit说明了最多1000条。
当然对于数据量要求不多的情况能够爬下来1000条也是不错的。
1.2 代码实现
#导入库
from bs4 import BeautifulSoup #网页数据解析和格式化处理工具
import pandas as pd
import requests #网络请求库
url='https://comment.bilibili.com/186803402.xml' #定义要获取的网页地址
html=requests.get(url) #返回文本信息
html.encoding='utf8'
soup=BeautifulSoup(html.text,'lxml') #建立soup对象
results=soup.find_all('d') #所有弹幕都是存在于d标签下,所以这里获取d标签下的内容
comments=[comment.text for comment in results] #获取文本信息
comments_dict={'comments':comments} #生成字典
df=pd.DataFrame(comments_dict)
df.to_csv('danmu_houlang.csv',encoding='utf-8-sig') #存储弹幕信息
这样这1000条弹幕就存储好了,如下表样式。
| Unnamed:0 | comments |
|---|---|
| 0 | 奔涌吧!后浪! |
| 1 | 奔涌吧 后浪 |
| 2 | 加油啊少年 |
| 3 | 00后跟上!90后为你们开路!一定做到更好!加油年轻人! |
| 4 | 老师推荐 |
二、1000条不够我想要更多怎么办?
看看历史弹幕吧
细心的你一定会发现在视频窗口右侧有弹幕列表,展开后发现有一个查看历史弹幕按钮。点击后我们发现有日历可以选择日期
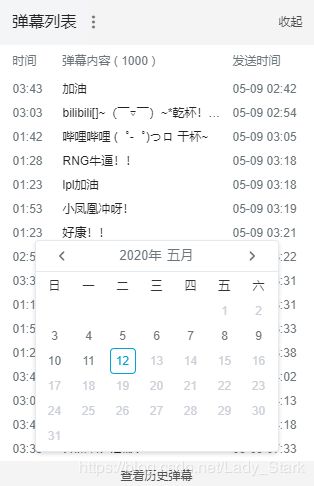
同样按F12,然后随便选择一天比如说2020年5月5日吧,可以看到列表中有多了几条。其中有一条名称中包含history,点击看一下发现这就是我们要找的5月5日的历史弹幕。
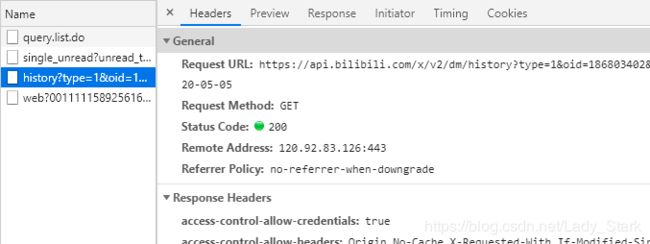
Request URL就是历史弹幕所在地址。
https://api.bilibili.com/x/v2/dm/history?type=1&oid=186803402&date=2020-05-05
可以看到这个地址同样包含前面提到的cid,同时还有一个日期date,
如果我们简单的替换日期就可以看到其他日期的弹幕了。
但是如果我们直接把这个URL替换前面代码里的URL就会出现问题,因为这个要链接API,所以需要你自己的登录信息,也就是你的cookie,这个也不难找,下拉Hearders页签就可以找到了。只需要再添加你的cookie信息同样可以爬取这些日期下的弹幕了。
三、B站弹幕文件里的其他信息有用吗?
答案是肯定的,那么下面我就来解析一下B站弹幕文件的其他信息。

可以看到P后面不同的信息是使用逗号分隔的,其中每一项都有特殊的含义。
第一个参数代表弹幕出现的时间 以秒数为单位。这个时间就是视频播放的时间,也就是弹幕是在视频播放的第几秒发出的,下面还有一个时间,注意区分清楚。
第二个参数代表弹幕的模式1…3 滚动弹幕 4底端弹幕 5顶端弹幕 6.逆向弹幕 7精准定位 8高级弹幕
第三个参数代表字号, 12非常小,16特小,18小,25中,36大,45很大,64特别大
第四个参数代表字体的颜色 以HTML颜色的十位数为准
第五个参数代表Unix格式的时间戳。基准时间为 1970-1-1 08:00:00。也就是你发出弹幕的实时日期时间。
第六个参数代表弹幕池 0普通池 1字幕池 2特殊池 【目前特殊池为高级弹幕专用】
第七个参数代表发送者的ID,用于“屏蔽此弹幕的发送者”功能
第八个参数代表弹幕在弹幕数据库中rowID 用于“历史弹幕”功能。
在接下来文章我将介绍如何使用这些弹幕作分析,敬请期待。