第一篇Blog——详解Faster RCNN网络全部细节
第一次写技术Blog,准备走上computer vision的道路,那就必不可少的需要求助,由于在CSDN也得到了太多的帮助,于是决定把自己学到的东西都放在公开平台上,希望也能帮助到你,也欢迎广大网友发现问题,及时指正。废话不多说,开始这篇对在cv领域产生革命性影响的RCNN的进化版Faster RCNN的究极详解。
1.把总结写在前面,先说一说Faster RCNN包含那些重点且它们都是干嘛的,如何进行训练的?测试的?
先放图:
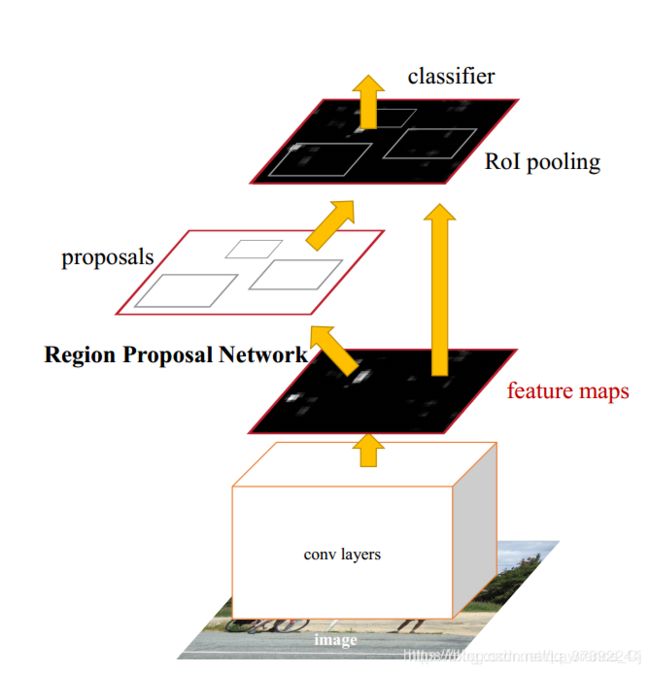
1.1基本CNN【例如‘VGG’,'RESnet‘等】
首先由于输入的图片可能会存在尺寸不同的问题,例如 900X600 的图片和 800X500 的图片无法输入到同一个基础CNN中,因此需要将输入图片统一,此处为设置为 900X600。
最初的图片在经过尺寸统一处理后,要放入卷积网络中,并产生Faster RCNN最初的输入feature map【512X37X50】(由于Conv中有四次pooling导致原图尺寸变为原来的1/feat_stride, feat_stride = 16。
1.2RPN卷积网络层
RPN (Region of proposal network), RPN层是需要进行训练产生Loss,并进行参数学习的层。要产生所谓的Loss并进行梯度下降更新参数,预测值和真值是必须所在。
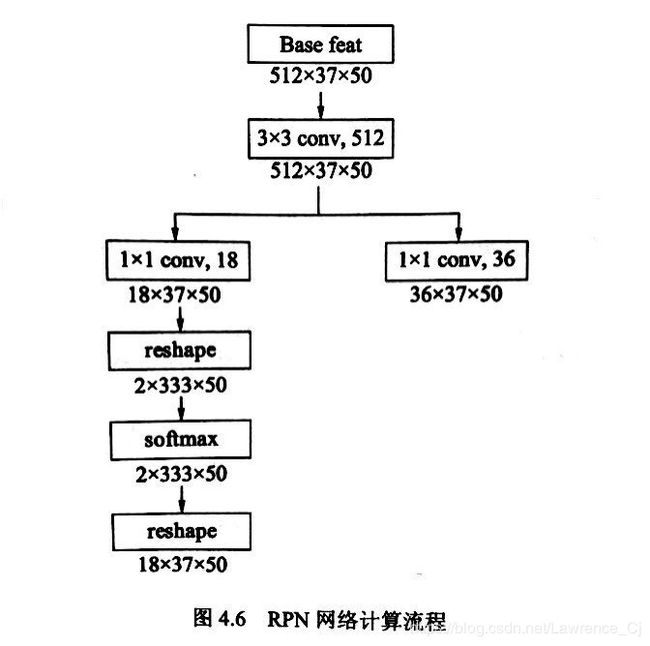
1).首先我们将对1.1中产生的feature_map进行卷积操作【3X3,512】,此处3X3的kernel整合以feature_map为中心的周围9个像素点的特征,为了使得每个特征点包含更多信息。接着进行【1X1conv,18】产生18X37X50的特征,每个点默认有9个anchors,每个anchor包含两个预测值(foreground和background的可能性) 因此每个特征点(共37X50)有18个预测值(此处不关心具体类别,只用于区分是否包含物体,foreground有物体,background没有)。
reshape应用于将每个anchor的预测值单独出一个维度,方便softmax计算和后续制作标签
softmax将预测值进行归一化,得到最终预测值
再次reshape返回最初特征图的尺寸方便用于Loss计算。
2). 另一个分支进行【1X1,36】的卷积,得到36X37X36的特征,每个特征点拥有36维的数据用于表示9(个anchors)X 4(中心点坐标和宽高值)=36维。
RPN部分的部分代码如下(源代码:)
此处包含两个网络,1.分类网络:得到每个anchor前背景得分和概率;2.回归网络:得到每个anchor的坐标预测偏移值(此偏移值为相对于后面会讲的真值anchors的偏移值,并不是相对于ground truth的)
def forward(self, base_feat, im_info, gt_boxes, num_boxes):
#输入数据的第一维是batch尺寸
batch_size = base_feat.size(0)
#先利用3 X 3卷积进一步融合特征
rpn_conv1 = F.relu(self.RPN_Conv(base_feat), inplace=True)
# get rpn classification score(1 X 1得到分类网络,每个点代表anchor的前背景得分)
rpn_cls_score = self.RPN_cls_score(rpn_conv1)
#利用reshape和softmax得到前背景概率
rpn_cls_score_reshape = self.reshape(rpn_cls_score, 2)
rpn_cls_prob_reshape = F.softmax(rpn_cls_score_reshape, 1)
rpn_cls_prob = self.reshape(rpn_cls_prob_reshape, self.nc_score_out)
# get rpn offsets to the anchor boxes 得到回归网络
rpn_bbox_pred = self.RPN_bbox_pred(rpn_conv1至此我们的预测值已经就位,待我们补全真值,便可以进行RPN的Loss的计算和梯度更新参数。
需要注意的事(理解误区):
这里两条分支所产生的分别是anchor类别和坐标预测值,这里的anchor都是假想出来的,在图像中并不真实存在,是人为说的这18和36个数分别属于9个不同尺寸的anchor,但后续会制作真实的anchor,假想的anchor和真实的anchor进行Loss的值计算时,用于para(参数)的更新的同时,也就进行了假想和真实anchor的一一对应。这里很容易导致误解,笔者在思考过程中也困惑于为何这个卷积的输出即分别属于9个anchor?这9个anchors哪来的这些问题。
1.3RPN真值的求取
本阶段,我们进行所有anchor的真值制作,与anchor的预测值(1.2中)进行Loss计算,并用于参数学习。
上图:
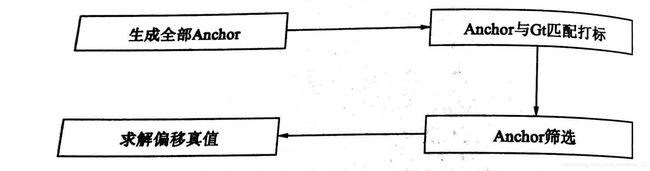
1.全部anchor生成
anchor生成部分代码解释整体可参照此链接,博主觉得这篇代码解读对我的帮助最大,希望对你亦是如此
附上链接:Anchor_target_layer.py
下面从代码角度简单讲解一下生成过程:
——————————————————
def generate_anchors(base_size=16, ratios=[0.5, 1, 2], scales=2**np.arange(3, 6)):
""" Generate anchor (reference) windows by enumerating aspect ratios X scales wrt a reference (0, 0, 15, 15) window. """
#首先创建一个基本anchor【0,0,15,15】
base_anchor = np.array([1, 1, base_size, base_size]) - 1
#将基本anchor进行宽高变化,生成三种宽高比的anchors
ratio_anchors = _ratio_enum(base_anchor, ratios)
#将上述anchors再进行尺度scale的变化,最终得到9种anchors
anchors = np.vstack([_scale_enum(ratio_anchors[i, :], scales) for i in xrange(ratio_anchors.shape[0])])
return anchors
————————————————————————————————在自行阅读代码之前,解释一下anchor生成机制,可能会帮助理解:
1).generate_anchors(base_size=16, ratio = 【0.5, 1, 2】, scale = 2**np.arange(3,6))
generate_anchors代码理解
三个参数含义:
a).base_size表示从原图到特征图的缩放尺寸(16倍)
b).ratio表示三种边长比例,注意:三种边长比例是在在相同面积下(例如:面积同样为256,三种边长比的anchor尺寸分别为:22 X 11(2:1), 16 X 16(1:1), 12 X 23(1:2), 他们面积都为256,但边长比例不同,故原文中设置的ratio用于相同面积下,不同比例边长的anchor的产生。
c).scale = 【8,16,32】,用于产生不同面积的anchor,面积分别为16X8 X 16X8 = 128 X128, 16X16 X 16X16 = 256 X 256, 16X32 X 16X32 = 512 X 512.
2).文中从feature_map中的第一个点(0,0)点进行初始化,特征图上的(0,0)点对应原图上左上(0,0),右下(15,15)的范围
在经过三组面积scale和边长ratio处理后结果如图:

3)在得到初始的anchor如上图,下一步进行平移变换,得到所有特征点对应的总37 X 50 X 9个anchors,代码中的shift变量存有全部0~特征图尺寸的数据,用于将初始化的anchor平移得到全部anchors
4)在得到全部anchors后要将超出边界范围的anchor删掉,即那些左上角坐标<0,右上角坐标>原图尺寸的anchors。
这样我们得到【M,4】尺寸的数据,M表示全部内部anchors的数量,4是每个anchor的坐标。
2.anchor真值的求取
基础原理上图:
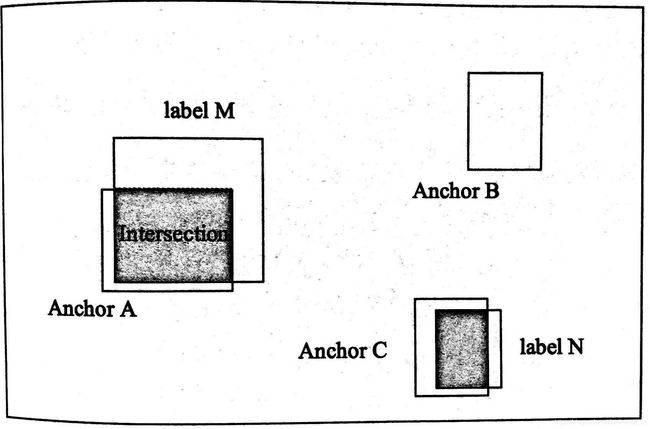
1)标签原则:
对于真值的获取,采用bbox_overlaps_batch()函数,用于计算每个anchor与所有ground truth的IoU值(intersection of Union)上图阴影面积。如图,anchor A 和anchor C与真值重合满足要求,则标签为1(前景);anchor C不满足,标签为0(背景)。
具体要求:
与gt_box有IoU最大的anchor标记1,每个anchor若与某个gt_box IoU值大于threshold,标记为1;小于某个设定值时,标记为0;在区间的anchor为无效anchor。标记-1。
结果:
上述过程产生的overlap是【1,M,N】的数据,1表示batch_size = 1(一个批次一张图片),M表示anchor数量,N表示gt_box数量。每个数据表示此anchor与此gt_box的IoU值。
最后返回anchors和Label,尺寸为【M有效,4】,【M有效,1】,‘M有效’ 表示经过筛选后的anchor数量。
2)降采样:
对于这些样本,仍然数目太多,并且绝代部分都是负样本(背景),所以我们需要筛选部分有效的正样品和负样品。
具体代码解释见: 文中 6.降采样
简单代码帮助理解:
————————————————————————
def forward(self, input):
......
for i in range(batch_size):
# subsample positive labels if we have too many
#进行下采样选取
if sum_fg[i] > 128:
fg_inds = torch.nonzero(labels[i] == 1).view(-1)
rand_num = torch.from_numpy(np.random.permutation
(fg_inds.size(0))).type_as(gt_boxes).long()
disable_inds = fg_inds[rand_num[:fg_inds.size(0)-num_fg]]
labels[i][disable_inds] = -1 #-1代表无效值
#负样本同上
......—————————————————————————
3)最后输出我们根据ground truth制作的anchor真值(包括:标签,anchor相对gt_box的坐标偏移值,bbox_inside_weight, bbox_outside_weight)
下面要说的很重要!!
思想误区:这里有笔者在学习过程中遇到的思想误区,一定要分清网上解析和书中所说的anchor真值和ground truth下面缩写成gt的区别,两者都是真值,那他们是一样的吗?
当然不一样!!! 假设一张图片中,我们人为制作标签时框选出的目标框为gt,一张图片可能就那么两三个物体和他们的框,即一张图片2,3个gt。相反,每张图片的anchor真值,是我们根据我们产生的10000+个anchor与ground truth的IoU值大小的判定以及对于距离gt近的anchor进行偏移后得到的。最后经过筛选,我们选出256个anchor真值(128正,128负),即每张图片相应有256个anchor真值,作为新的标签,输入RPN网络中的Loss计算中,目的学习参数,使得我们预测的anchor与我们制作的anchor能够尽可能接近。
下面从代码的角度,讲解一些代码内容中不好理解的部分:
先列出帮助理解的数据和操作:
- offset参数: 由于batch的存在,导致index会出现混乱,例如argmax_overlaps数据为【B,M】,第一维是各个batch,第二维,它的意义是每个anchors的最大IoU对应的gt的index(M可能为【0,2,1,3,2,…】,我们的输入argmax_overlaps.view(-1),是一个【BXM,1】的数据,如果我们不进行offset的坐标变换操作,会导致所有除了第一批次的anchors,都仅仅使用第一批次的gt,导致错误。原因在于,我们对gt_box进行了view操作,把它变成了【BXK,1】的数据结构,前K个数据是第一批次的gt数据,K到2K的数据属于batch2,以此类推。
offset进行扩维以前为:【0,0,0,…(K个),K,K,K,…(K个),2K,2K,2K,…(K个),…】,由此,我们将第二批次的数据平移K个单位,是其anchor于gt保证正确的对应关系。 - box_target: 存于anchors与gt_box一一对应后的偏移值(dx,dy,dw,dh)
- bbox_inside_weights: 是正负样本在计算Loss时会用到的系数。正样本为1,负为0,相当于Loss公式中的Pi*。它其实起到一个mask的作用,当我们在计算回归随时的时候,我们是不需要考虑负样本的回归损失的,但由于我们使用矩阵相乘的方式,矢量化来求取我们的Loss实际上我们将负样本的回归损失也是进行计算了的,因此我们在进行相加之前用一个mask来将所有的负样本的回归损失全部过滤掉。
- bbox_outside_weights: 与3同理,它相当于式中的λ/Nreg系数。
损失函数计算公式如下: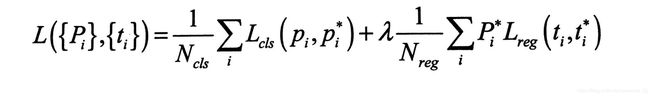
——————————————————
# gt_boxes (B,K,5)
offset = torch.arange(0, batch_size)*gt_boxes.size(1)#offset(batch_size,)
# argmax_overlaps(B,M) + (B,1) !!索引需要
argmax_overlaps = argmax_overlaps + offset.view(batch_size, 1).type_as(argmax_overlaps)
# gt_boxes.view(-1,5) (B*K,5)所以需要offset
# bbox_targets (batch_size, -1, 5)
bbox_targets = _compute_targets_batch(anchors, gt_boxes.view(-1,5)[argmax_overlaps.view(-1), :].view(batch_size, -1, 5))
# use a single value instead of 4 values for easy index.
#求出的偏移,是要看这个anchor离哪一个gt最近【那如果都不近呢,返回的应该是第一个gt的偏移】
bbox_inside_weights[labels==1] = cfg.TRAIN.RPN_BBOX_INSIDE_WEIGHTS[0]
#默认RPN_POSITIVE_WEIGHT=-1
if cfg.TRAIN.RPN_POSITIVE_WEIGHT < 0:
#num_examples = torch.sum(labels[i] >= 0)
# #样本权重归一化
num_examples = torch.sum(labels[i] >= 0).item()#正负的样本总数目
positive_weights = 1.0 / num_examples#正样本权重 1/总样本,感觉可以直接256上啊
negative_weights = 1.0 / num_examples
else:
assert ((cfg.TRAIN.RPN_POSITIVE_WEIGHT > 0) & (cfg.TRAIN.RPN_POSITIVE_WEIGHT < 1))
bbox_outside_weights[labels == 1] = positive_weights
bbox_outside_weights[labels == 0] = negative_weights
好处:
用256个anchor真值作为学习对象比用滑窗和RCNN中的2000个窗口,节省了太多空间和时间,这也是anchor的创新所在。
终:由此基于三种面积尺寸,三种边长比,可产生共3X3 = 9个anchor,故每个特征点有9个真实存在的anchor,到此9个真实的anchor和9个虚构anchor都已经产生,下面就是Loss计算,使得假想的anchor通过学习与anchor的真值更加接近,最好的结果是两者重合(不太可能),到此我们的RPN训练可以开始了。