DeepLearning | 图卷积神经网络(GCN)解析(论文、算法、代码)
本篇博客主要讲述三种图卷积网络(Graph Convolutional Network, GCN)的算法原理及python实现,全文阅读时间约10分钟。
目录
- 一、图卷积网络原理
- 1.0 预备知识
- 1.1 第一代图卷积网络
- 1.2 第二代图卷积网络
- 1.3 第三代图卷积网络
- 1.4 图卷积网络的优缺点
- 二、图卷积网络python实现
- 三、图卷积网络论文、代码、数据集资源下载!
一、图卷积网络原理
图模型早期的研究被称为图信号处理(Graph Signal Processing, GSP),在12年深度学习爆发以后,学术圈开始研究图模型与神经网络的结合。主要经过三代模型的发展后,相对成熟的图卷积网络开始发展起来,本文主要介绍的也是这三代图卷积模型的原理和变化。
1.0 预备知识
在介绍图卷积之前,需要先普及一些基本的理论知识:
- 图结构数据
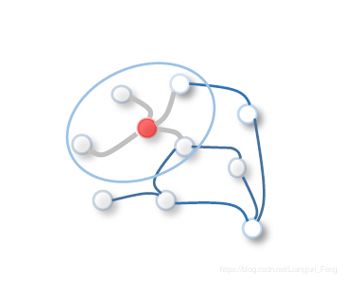
一张图由节点和边组成,节点代表成员或者对象,而边表示节点间的关系,我们往往使用 A ∈ R n × n A \in \mathbb{R}^{n \times n} A∈Rn×n表示一张图的结构特性, A A A称为图的邻接矩阵,其中 n n n表示节点数量, a i , j a_{i,j} ai,j的数值则表示节点 i i i和节点 j j j之间的关系。 - 拉普拉斯图矩阵
基于图的邻接矩阵,我们可以方便的定义拉普拉斯图矩阵
L = D − A L=D-A L=D−A 上式中 A A A是邻接矩阵, D D D称为度矩阵,是一个对角矩阵, d i i = ∑ j = 1 n a i j d_{ii}=\sum^{n}_{j=1}a_{ij} dii=∑j=1naij描述了每一个样本近邻的总和信息。 - 卷积定理:函数卷积的傅利叶变换是函数傅利叶变换的乘积。
- 傅立叶变换在图上的推广
拉普拉斯图矩阵 L L L的特征向量 U U U可以作为傅立叶变换的基,L = U d i a g ( λ 1 , . . . , λ n ) U − 1 L=Udiag(\lambda_{1},...,\lambda_{n})U^{-1} L=Udiag(λ1,...,λn)U−1 这里的特征值则可以理解为不同频率分量的系数,越小的特征值表明对应基的分量信息越少。 - 图卷积的分类
图卷积主要可以分为基于谱域(谱分解/特征根分解)的卷积以及基于空域的卷积,今天介绍的三代卷积网络都是基于谱域的卷积,但其在空域上也有很好的解释性。关于空域图卷积会在以后的文章中专门介绍
1.1 第一代图卷积网络
第一代图卷积定义为
这里的 σ \sigma σ表示激活函数, θ \theta θ表示可训练的网络参数,使用反向传播进行训练, x x x是输入的特征矩阵。
根据预备知识的第4点, 上式可以解释为, U T U^{T} UT将 x x x变换到频域当中,在频域中与训练得到的 θ \theta θ加权结合进行特征提取,继而又通过 U U U反变换到原来的空域当中。
第一代图卷积模型由LeCun组在14年提出,论文可见 Spectral networks and locally connected networks on graphs. In International Conference on Learning Representations。该模型作为早期的图卷积网络,缺点在于
- 每一次前向传播都需要计算 U U U, θ \theta θ, U T UT UT 的乘积,计算代价高
- 在空域内的解释性不好,没法很好利用图的近邻性质
- 卷积核需要 n n n个参数
1.2 第二代图卷积网络
第二代图卷积模型定义为
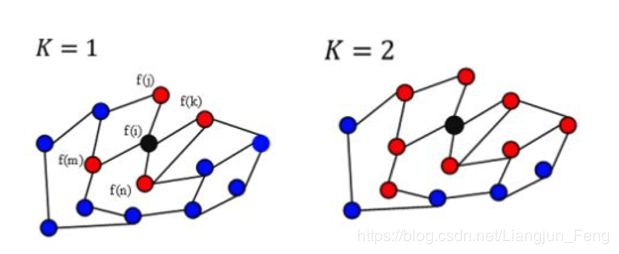
通过定义不同的近邻,来提取更多的信息。
第二代图卷积网络在论文 Convolutional Neural Networks on Graphs with Fast Localized Spectral Filtering中被提出,相比与第一代图卷积模型,其优点在于
- 卷积核只有 K K K个参数,一般 K K K远小于 N N N
- 不需要做特征根分解,直接用 L L L
- 空间域内的解释性较好
1.3 第三代图卷积网络
第三代图卷积模型,也是当前最流行的版本,由第一代卷积简化推导而来。第一代卷积模型可以表示为
使用切比雪夫多项式 K K K阶近似 g θ ( Λ ) g_{\theta}(\Lambda) gθ(Λ),
进一步近似,约束 λ m a x = 2 \lambda_{max}=2 λmax=2, 取 K = 1 K=1 K=1, 则有
据上,第三代图卷积模型为定义为
第三代图卷积模型在论文 Semi-Supervised Classification with Graph Convolutional Networks中被提出,由于其较好空域解释性和精简的模型结构,受到广泛应用。
1.4 图卷积网络的优缺点
特点:
- 训练的输入为 X X X和 A A A,以整张数据图为输入,而不是以batch训练
- 训练阶段会用到无标签的测试数据,因而是直推式半监督学习
优点:
- 显式的利用节点间的关系进行特征的提取
- 实现相对简单、计算并不复杂
缺点:
- 图卷积网络一般只有1-4层,无法深层堆叠,会出现梯度消失的问题
- . 一般的图卷积网络以整张图作为输入,所以在普通机器上无法训练大规模的图数据
二、图卷积网络python实现
下面是图卷积网络的核心代码
#卷积层代码
import torch
from torch import nn
from torch.nn import functional as F
from utils import sparse_dropout, dot
class GraphConvolution(nn.Module):
def __init__(self, input_dim, output_dim, num_features_nonzero,
dropout=0.,
is_sparse_inputs=False,
bias=False,
activation = F.relu,
featureless=False):
super(GraphConvolution, self).__init__()
self.dropout = dropout
self.bias = bias
self.activation = activation
self.is_sparse_inputs = is_sparse_inputs
self.featureless = featureless
self.num_features_nonzero = num_features_nonzero
self.weight = nn.Parameter(torch.randn(input_dim, output_dim))
self.bias = None
if bias:
self.bias = nn.Parameter(torch.zeros(output_dim))
def forward(self, inputs):
# print('inputs:', inputs)
x, support = inputs
if self.training and self.is_sparse_inputs:
x = sparse_dropout(x, self.dropout, self.num_features_nonzero)
elif self.training:
x = F.dropout(x, self.dropout)
# convolve
if not self.featureless: # if it has features x
if self.is_sparse_inputs:
xw = torch.sparse.mm(x, self.weight)
else:
xw = torch.mm(x, self.weight)
else:
xw = self.weight
out = torch.sparse.mm(support, xw)
if self.bias is not None:
out += self.bias
return self.activation(out), support
#模型代码
import torch
from torch import nn
from torch.nn import functional as F
from layer import GraphConvolution
from config import args
class GCN(nn.Module):
def __init__(self, input_dim, output_dim, num_features_nonzero):
super(GCN, self).__init__()
self.input_dim = input_dim # 1433
self.output_dim = output_dim
print('input dim:', input_dim)
print('output dim:', output_dim)
print('num_features_nonzero:', num_features_nonzero)
self.layers = nn.Sequential(GraphConvolution(self.input_dim, args.hidden, num_features_nonzero,
activation=F.relu,
dropout=args.dropout,
is_sparse_inputs=True),
GraphConvolution(args.hidden, output_dim, num_features_nonzero,
activation=F.relu,
dropout=args.dropout,
is_sparse_inputs=False),
)
def forward(self, inputs):
x, support = inputs
x = self.layers((x, support))
return x
def l2_loss(self):
layer = self.layers.children()
layer = next(iter(layer))
loss = None
for p in layer.parameters():
if loss is None:
loss = p.pow(2).sum()
else:
loss += p.pow(2).sum()
return loss
三、图卷积网络论文、代码、数据集资源下载!

有问题可以私信博主,点赞关注的一般都会回复,一起努力,谢谢支持。
微信搜索“老和山算法指南”获取下载链接与技术交流群