Kafka学习之五 Kafka架构以及设计原理
1、架构图
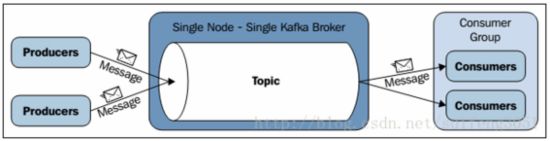
Producers、Kafka broker、consumers,它们分别运行在不同的节点
2、设计思想
consumer group: 各个consumer可以组成一个组,每个消息只能被组中的一个consumer消费,如果一个消息可以被多个consumer消费的话,那么这些consumer必须在不同的组。
消息状态: 在Kafka中,消息的状态被保存在consumer中,broker不会关心哪个消息被消费了被谁消费了,只记录一个offset值(指向partition中下一个要被消费的消息位置),这就意味着如果consumer处理不好的话,broker上的一个消息可能会被消费多次。
消息持久化: Kafka中会把消息持久化到本地文件系统中,并且保持极高的效率。
消息有效期: Kafka会长久保留其中的消息,以便consumer可以多次消费,当然其中很多细节是可配置的。
批量发送: Kafka支持以消息集合为单位进行批量发送,以提高push效率。
push-and-pull: Kafka中的Producer和consumer采用的是push-and-pull模式,即Producer只管向broker push消息,consumer只管从broker pull消息,两者对消息的生产和消费是异步的。
Kafka集群中broker之间的关系: 不是主从关系,各个broker在集群中地位一样,我们可以随意的增加或删除任何一个broker节点。
负载均衡方面: Kafka提供了一个 metadata API来管理broker之间的负载(对Kafka0.8.x而言,对于0.7.x主要靠zookeeper来实现负载均衡)。
同步异步: Producer采用异步push方式,极大提高Kafka系统的吞吐率(可以通过参数控制是采用同步还是异步方式)。
分区机制partition: Kafka的broker端支持消息分区,Producer可以决定把消息发到哪个分区,在一个分区中消息的顺序就是Producer发送消息的顺序,一个主题中可以有多个分区,具体分区的数量是可配置的。分区的意义很重大,后面的内容会逐渐体现。
离线数据装载: Kafka由于对可拓展的数据持久化的支持,它也非常适合向Hadoop或者数据仓库中进行数据装载
Kafka消息的可靠性问题:
关于消息投递可靠性,一个消息如何算投递成功,Kafka提供了三种模式
At most once—this handles the first case described. Messages are immediately marked as consumed, so they can't be given out twice, but many failure scenarios may lead to losing messages.
At least once—this is the second case where we guarantee each message will be delivered at least once, but in failure cases may be delivered twice.
Exactly once—this is what people actually want, each message is delivered once and only once.
第一种是啥都不管,发送出去就当作成功,这种情况当然不能保证消息成功投递到broker;第二种是对于Master Slave模型,只有当Master和所有Slave都接收到消息时,才算投递成功,这种模型提供了最高的投递可靠性,但是损伤了性能;第三种模型,即只要Master确认收到消息就算投递成功;实际使用时,根据应用特性选择,绝大多数情况下都会中和可靠性和性能选择第三种模型。
对于消息在broker上的可靠性,因为消息会持久化到磁盘上,所以如果正常stop一个broker,其上的数据不会丢失;但是如果不正常stop,可能会使存在页面缓存来不及写入磁盘的消息丢失,这可以通过配置flush页面缓存的周期、阈值缓解,但是同样会频繁的写磁盘会影响性能,又是一个选择题,根据实际情况配置。
接着,我们再看消息消费的可靠性,Kafka提供的是“At least once”模型,因为消息的读取进度由offset提供,offset可以由消费者自己维护也可以维护在zookeeper里,但是当消息消费后consumer挂掉,offset没有即时写回,就有可能发生重复读的情况,这种情况同样可以通过调整commit offset周期、阈值缓解,甚至消费者自己把消费和commit offset做成一个事务解决,但是如果你的应用不在乎重复消费,那就干脆不要解决,以换取最大的性
学习参考:
http://www.infoq.com/cn/articles/kafka-analysis-part-1
http://flychao88.iteye.com/category/350737
http://shift-alt-ctrl.iteye.com/blog/1930791
http://www.tuicool.com/articles/mErEZn