图像检索入门:CVPR2015《Deep Learning of Binary Hash Codes for Fast Image Retrieval》
原文代码:https://github.com/kevinlin311tw/caffe-cvprw15
研究背景
在基于内容的图像检索(CBIR)中,使用深度学习的最为简单的方式是使用神经网络特征层的输出用于计算空间距离来判断相似度,但这样会导致浮点型数据储存消耗和维度灾难。
实际策略是使用近似最近邻(ANN)技术或基于Hash的方法来进行加速。这些方法将高维特征投影到较低维度空间,然后生成紧凑二进制代码。所产生的二进制代码,可以通过二进制模式匹配或汉明距离测量来执行快速图像搜索,这显着降低了计算成本并进一步优化了搜索效率。
研究方法
本文引入了一种简单有效的监督学习框架适用于图像检索;通过网络模型的微调,能够同时学习区域特定的图像表示和一系列Hash值;提出的方法超过了现有的baseline;本文方法通过“点对”的方式学习hashing编码,相比于传统的“成对”策略更易于扩展。具体研究方案如下:
- 在ImageNet数据集上使用Alexnet模型进行有监督的预训练;
- 在Alexnet模型上添加隐藏层,并利用上一步得到的权重在自己的数据集上进行微调;
- 得到图像的特征矩阵,Hash值和标签后,通过分层深度搜索进行图片检索。
如下图所示:
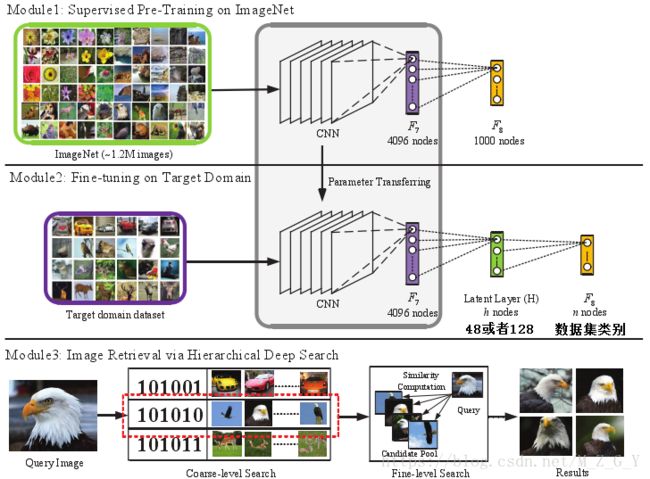
1.网络设置
由于输入的图像经过网络F6层−F8层得到的信息在图像分类,检索中有很大作用。但是这些信息又是高维(上千维)的特征,这些特征直接用于检索,将会非常耗时。直观的想法就是把这些有效的特征用来压缩变成二进制特征,来进行计算海明距离。所以,作者修改了网络结构,在F7和F8之间加入了一层隐藏层(全连接层),该层主要是用于学习48/128位的Hash值。
2.模型训练
使用在ImageNet数据集上学习的参数来初始化模型的前7层参数,对隐藏层和F8层的参数进行随机初始化,在自己的数据集上训练模型。
3.图像检索
由于浅层学习了图像的局部特征,深层学习了语义信息,所以作者提出了一个粗粒度到细粒度的检索策略,首先检索语义信息(Hash值),得到相似的候选集,然后再从候选集中利用局部特征进行检测。
粗粒度检索
粗糙检索是用H层的二分哈希码,相似性用hamming距离衡量。对于给定的图像 ,通过模型学习到局部特征(F7层)
,通过模型学习到局部特征(F7层) ,Hash值(隐藏层)和标签,其中Hash值记为
,Hash值(隐藏层)和标签,其中Hash值记为![]() ,隐藏层有
,隐藏层有 个节点,即Hash值共有位,通过设定阈值对隐藏层的输出进行二值化:
个节点,即Hash值共有位,通过设定阈值对隐藏层的输出进行二值化:
![]()
将待检索图像和所有的图像的对应Hash层编码进行比对后,选择出hamming距离小于一个阈值的m个构成一个池,其中包含了这m个比较相似的图像。
细粒度检索
细致检索则用到的是F7层的特征,相似性用欧氏距离衡量。从粗粒度检索得到的m个图像池中选出最相似的前 个图像作为最后的检索结果。对于待检测图像
个图像作为最后的检索结果。对于待检测图像![]() 和该个图像的欧氏距离如下图所示:
和该个图像的欧氏距离如下图所示:
![]()
其中![]() 表示待检测图像的F7层特征,
表示待检测图像的F7层特征,![]() 表示个图像的F7曾特征。每两张图128维的H层哈希码距离计算速度是0.113ms,4096维的fc7层特征的距离计算需要109.767ms,因此可见二值化哈希码检索的速度优势。
表示个图像的F7曾特征。每两张图128维的H层哈希码距离计算速度是0.113ms,4096维的fc7层特征的距离计算需要109.767ms,因此可见二值化哈希码检索的速度优势。
实验结果
作者在MINIST,CIFAR-10,YAHOO-1M三个数据集上做了实验,并且在分类和检索上都做了实验,结果都很不错,特别是在CIFAR-10上图像检索的精度有30%的提升。
1.MINIST(分类:0.47%的错误率,检索:98.2 0.3%的准确率)
0.3%的准确率)


左边第一列是待检索图像,右边是48和128位H层节点分别得到的结果。可以看到检索出的数字都是正确的,并且在这个数据集上48位的效果更好,128位的太高,容易引起过拟合。
2.CIFAR-10(分类:89%,检索:89%)


在这个数据集上128位的H层节点比48位的效果更好,比如128检索出更多的马头,而48位的更多的全身的马。
3.Yahoo-1M(分类:83.75%,检索:不到80%)

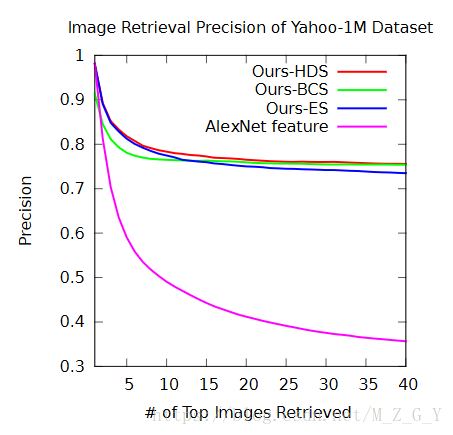
其中Ours-HDS是F7+Hash,Ours-BCS是Hash,Our-ES是F7。
作者在这个数据集上比较了只用fc7,只用H和同时用两者(粗糙到细致)的结果,实验结果表明是两者都用的效果更好。可以看到如果只用alexnet而不进行fine-tune的话,检索出的结果精度很低。(在实现代码过程中,会发现在cifar10数据集中,粗粒度检索中同一类的Hash值大致都相同)