分布式事务解决方案:2PC,TCC以及基于消息的最终一致性
各种形态的分布式事务
分布式事务有多种主流形态,包括:
基于消息实现的分布式事务
基于补偿实现的分布式事务
基于TCC实现的分布式事务
基于SAGA实现的分布式事务
基于2PC实现的分布式事务
这些形态的原理已经在很多文章中进行了剖析,用“分布式事务”关键字就能搜到对应的文章,本文不再赘述这些形态的原理,并将重点放在如何根据业务选择对应的分布式事务形态上。
分布式事务解决方案汇总
接下来,以一个典型的分布式事务问题——“转账”为例,详细探讨分布式事务的各种解决方案。
以支付宝为例,要把一笔钱从支付宝的余额转账到余额宝,支付宝的余额在系统A,背后有对应的DB1;余额宝在系统B,背后有对应的DB2;蚂蚁借呗在系统C,背后有对应的DB3,这些系统之间都要支持相关转账。所谓“转账”,就是转出方的系统里面账号要扣钱,转入方的系统里面账号要加钱,如何保证两个操作在两个系统中同时成功呢?
2PC
(1)2PC理论。在讲MySQL Binlog和Redo Log的一致性问题时,已经用到了2PC。当然,那个场景只是内部的分布式事务问题,只涉及单机的两个日志文件之间的数据一致性;2PC是应用在两个数据库或两个系统之间。
2PC有两个角色:事务协调者和事务参与者。具体到数据库的实现来说,每一个数据库就是一个参与者,调用方也就是协调者。2PC是指事务的提交分为两个阶段,如图10-1所示。
阶段1:准备阶段。协调者向各个参与者发起询问,说要执行一个事务,各参与者可能回复YES、NO或超时。
阶段2:提交阶段。如果所有参与者都回复的是YES,则事务协调者向所有参与者发起事务提交操作,即Commit操作,所有参与者各自执行事务,然后发送ACK。
如果有一个参与者回复的是NO,或者超时了,则事务协调者向所有参与者发起事务回滚操作,所有参与者各自回滚事务,然后发送ACK,如图10-2所示。
图10-1 2PC事务提交示意图
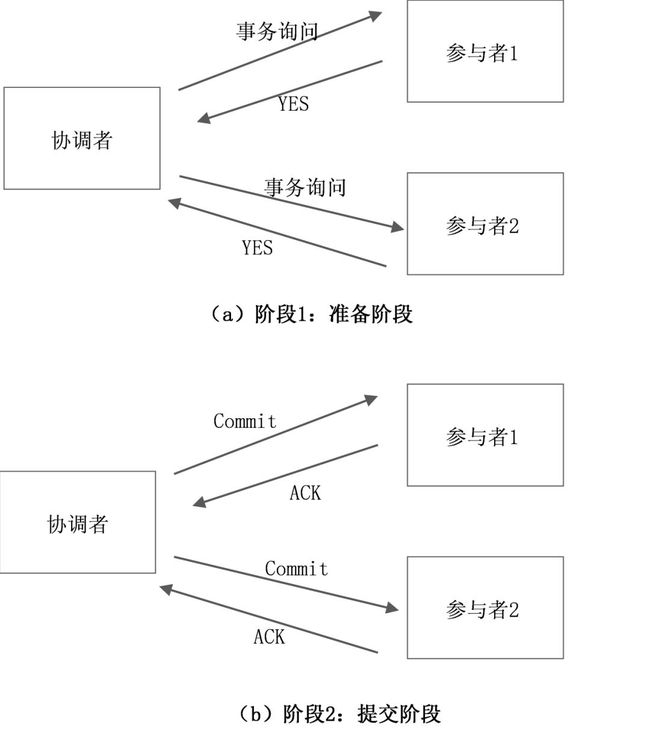
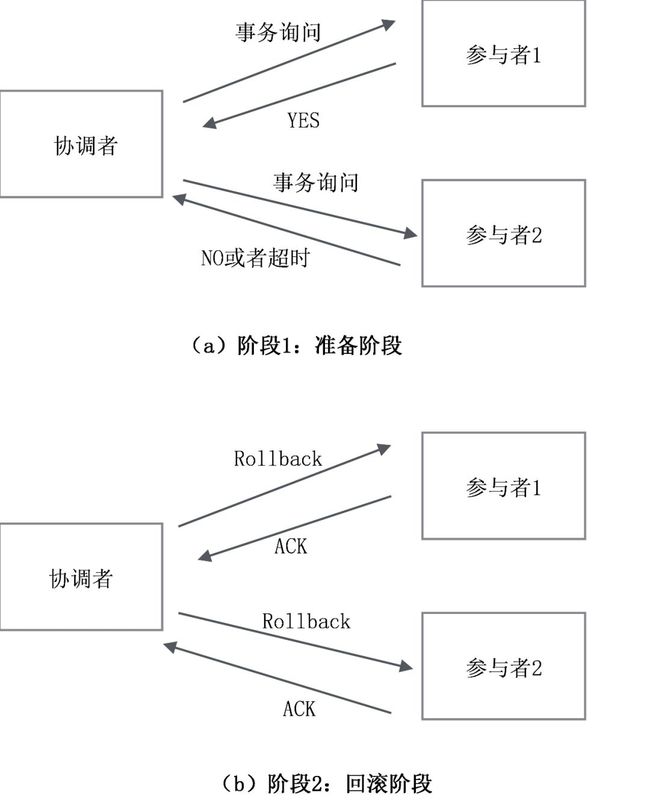
图10-2 事务回滚示意图
所以,无论事务提交,还是事务回滚,都是两个阶段。
(2)2PC的实现。通过分析可以发现,要实现2PC,所有参与者都要实现三个接口:Prepare、Commit、Rollback,这也就是XA协议,在Java中对应的接口是javax.transaction.xa.XAResource,通常的数据库也都实现了这个协议。开源的Atomikos也基于该协议提供了2PC的解决方案,有兴趣的读者可以进一步研究。
(3)2PC的问题。2PC在数据库领域非常常见,但它存在几个问题:
问题1:性能问题。在阶段1,锁定资源之后,要等所有节点返回,然后才能一起进入阶段2,不能很好地应对高并发场景。
问题2:阶段1完成之后,如果在阶段2事务协调者宕机,则所有的参与者接收不到Commit或Rollback指令,将处于“悬而不决”状态。
问题3:阶段1完成之后,在阶段2,事务协调者向所有的参与者发送了Commit指令,但其中一个参与者超时或出错了(没有正确返回ACK),则其他参与者提交还是回滚呢? 也不能确定。
为了解决2PC的问题,又引入了3PC。3PC存在类似宕机如何解决的问题,因此还是没能彻底解决问题,此处不再详述。
2PC除本身的算法局限外,还有一个使用上的限制,就是它主要用在两个数据库之间(数据库实现了XA协议)。但以支付宝的转账为例,是两个系统之间的转账,而不是底层两个数据库之间直接交互,所以没有办法使用2PC。
不仅支付宝,其他业务场景基本都采用了微服务架构,不会直接在底层的两个业务数据库之间做一致性,而是在两个服务上面实现一致性。
正因为2PC有诸多问题和不便,在实践中一般很少使用,而是采用下面要讲的各种方案。
- 最终一致性(消息中间件)
一般的思路是通过消息中间件来实现“最终一致性”,如图10-3所示。
系统A收到用户的转账请求,系统A先自己扣钱,也就是更新DB1;然后通过消息中间件给系统B发送一条加钱的消息,系统B收到此消息,对自己的账号进行加钱,也就是更新DB2。
这里面有一个关键的技术问题:
系统A给消息中间件发消息,是一次网络交互;更新DB1,也是一次网络交互。系统A是先更新DB1,后发送消息,还是先发送消息,后更新DB1?
假设先更新DB1成功,发送消息网络失败,重发又失败,怎么办?又假设先发送消息成功,更新DB1失败。消息已经发出去了,又不能撤回,怎么办?或者消息中间件提供了消息撤回的接口,但是又调用失败怎么办?
因为这是两次网络调用,两个操作不是原子的,无论谁先谁后,都是有问题的。
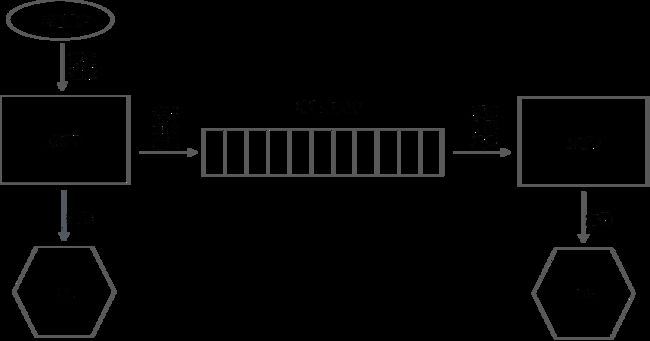
图10-3 消息中间件实现最终一致性
下面来看最终一致性的几种具体实现思路:
a.最终一致性:错误的方案0
有人可能会想,可以把“发送加钱消息”这个网络调用和更新DB1放在同一个事务里面,如果发送消息失败,更新DB自动回滚。这样不就可以保证两个操作的原子性了吗?
这个方案看似正确,其实是错误的,原因有两点:
(1)网络的2将军问题:发送消息失败,发送方并不知道是消息中间件没有收到消息,还是消息已经收到了,只是返回response的时候失败了?
如果已经收到消息了,而发送端认为没有收到,执行update DB的回滚操作,则会导致账户A的钱没有扣,账户B的钱却被加了。
(2)把网络调用放在数据库事务里面,可能会因为网络的延时导致数据库长事务。严重的会阻塞整个数据库,风险很大。
b.最终一致性:第1种实现方式(业务方自己实现)
假设消息中间件没有提供“事务消息”功能,比如用的是Kafka。该如何解决这个问题呢?
消息中间件实现最终一致性示意图如图10-4所示。
(1)系统A增加一张消息表,系统A不再直接给消息中间件发送消息,而是把消息写入到这张消息表中。把DB1的扣钱操作(表1)和写入消息表(表2)这两个操作放在一个数据库事务里,保证两者的原子性。
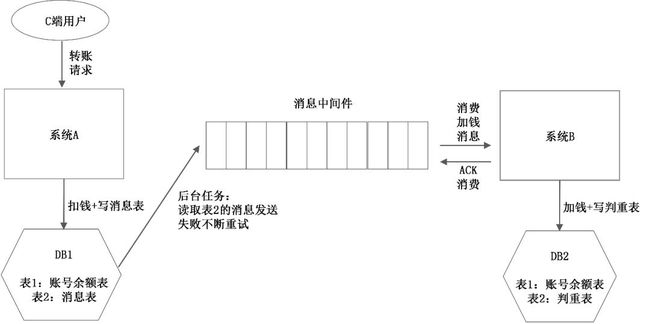
图10-4 消息中间件实现最终一致性示意图
(2)系统A准备一个后台程序,源源不断地把消息表中的消息传送给消息中间件。如果失败了,也不断尝试重传。因为网络的2将军问题,系统A发送给消息中间件的消息网络超时了,消息中间件可能已经收到了消息,也可能没有收到。系统A会再次发送该消息,直到消息中间件返回成功。所以,系统A允许消息重复,但消息不会丢失,顺序也不会打乱。
(3)通过上面的两个步骤,系统A保证了消息不丢失,但消息可能重复。系统B对消息的消费要解决下面两个问题:
问题1:丢失消费。系统B从消息中间件取出消息(此时还在内存里面),如果处理了一半,系统B宕机并再次重启,此时这条消息未处理成功,怎么办?
答案是通过消息中间件的ACK机制,凡是发送ACK的消息,系统B重启之后消息中间件不会再次推送;凡是没有发送ACK的消息,系统B重启之后消息中间件会再次推送。
但这又会引发一个新问题,就是下面问题2的重复消费:即使系统B把消息处理成功了,但是正要发送ACK的时候宕机了,消息中间件以为这条消息没有处理成功,系统B再次重启的时候又会收到这条消息,系统B就会重复消费这条消息(对应加钱类的场景,账号里面的钱就会加两次)
问题2:重复消费。除了ACK机制,可能会引起重复消费;系统A的后台任务也可能给消息中间件重复发送消息。
为了解决重复消息的问题,系统B增加一个判重表。判重表记录了处理成功的消息ID和消息中间件对应的offset(以Kafka为例),系统B宕机重启,可以定位到offset位置,从这之后开始继续消费。
每次接收到新消息,先通过判重表进行判重,实现业务的幂等。同样,对DB2的加钱操作和消息写入判重表两个操作,要在一个DB的事务里面完成。
这里要补充的是,消息的判重不止判重表一种方法。如果业务本身就有业务数据,可以判断出消息是否重复了,就不需要判重表了。
通过上面三步,实现了消息在发送方的不丢失、在接收方的不重复,联合起来就是消息的不漏不重,严格实现了系统A和系统B的最终一致性。
但这种方案有一个缺点:系统A需要增加消息表,同时还需要一个后台任务,不断扫描此消息表,会导致消息的处理和业务逻辑耦合,额外增加业务方的开发负担。
c.最终一致性:第二种实现方式(基于RocketMQ事务消息)
为了能通过消息中间件解决该问题,同时又不和业务耦合,RocketMQ提出了“事务消息”的概念,如图10-5所示。
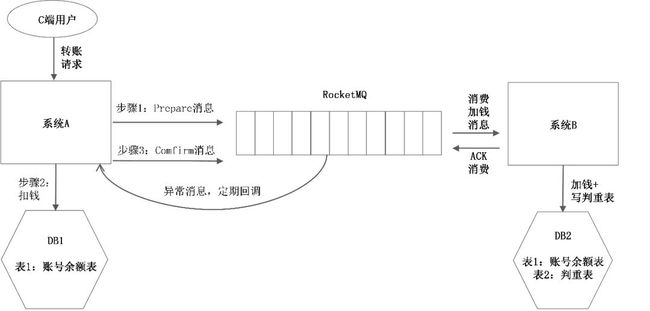
图10-5 RocketMQ事务消息示意图
RocketMQ不是提供一个单一的“发送”接口,而是把消息的发送拆成了两个阶段,Prepare阶段(消息预发送)和Confirm阶段(确认发送)。具体使用方法如下:
步骤1:系统A调用Prepare接口,预发送消息。此时消息保存在消息中间件里,但消息中间件不会把消息给消费方消费,消息只是暂存在那。
步骤2:系统A更新数据库,进行扣钱操作。
步骤3:系统A调用Comfirm接口,确认发送消息。此时消息中间件才会把消息给消费方进行消费。
显然,这里有两种异常场景:
场景1:步骤1成功,步骤2成功,步骤3失败或超时,怎么处理?
场景2:步骤1成功,步骤2失败或超时,步骤3不会执行。怎么处理?
这就涉及RocketMQ的关键点:RocketMQ会定期(默认是1min)扫描所有的预发送但还没有确认的消息,回调给发送方,询问这条消息是要发出去,还是取消。发送方根据自己的业务数据,知道这条消息是应该发出去(DB更新成功了),还是应该取消(DB更新失败)。
对比最终一致性的两种实现方案会发现,RocketMQ最大的改变其实是把“扫描消息表”这件事不让业务方做,而是让消息中间件完成。
至于消息表,其实还是没有省掉。因为消息中间件要询问发送方事物是否执行成功,还需要一个“变相的本地消息表”,记录事务执行状态和消息发送状态。
同时对于消费方,还是没有解决系统重启可能导致的重复消费问题,这只能由消费方解决。需要设计判重机制,实现消息消费的幂等。
d.人工介入
无论方案1,还是方案2,发送端把消息成功放入了队列中,但如果消费端消费失败怎么办?
如果消费失败了,则可以重试,但还一直失败怎么办?是否要自动回滚整个流程?
答案是人工介入。从工程实践角度来讲,这种整个流程自动回滚的代价是非常巨大的,不但实现起来很复杂,还会引入新的问题。比如自动回滚失败,又如何处理?
对应这种发生概率极低的事件,采取人工处理会比实现一个高复杂的自动化回滚系统更加可靠,也更加简单。
- TCC
2PC通常用来解决两个数据库之间的分布式事务问题,比较局限。现在企业采用的是各式各样的SOA服务,更需要解决两个服务之间的分布式事务问题。
为了解决SOA系统中的分布式事务问题,支付宝提出了TCC。TCC是Try、Confirm、Cancel三个单词的缩写,其实是一个应用层面的2PC协议,Confirm对应2PC中的事务提交操作,Cancel对应2PC中的事务回滚操作,如图10-6所示。
(1)准备阶段:调用方调用所有服务方提供的Try接口,该阶段各调用方做资源检查和资源锁定,为接下来的阶段2做准备。
(2)提交阶段:如果所有服务方都返回YES,则进入提交阶段,调用方调用各服务方的Confirm接口,各服务方进行事务提交。如果有一个服务方在阶段1返回NO或者超时了,则调用方调用各服务方的Cancel接口,如图10-7所示。
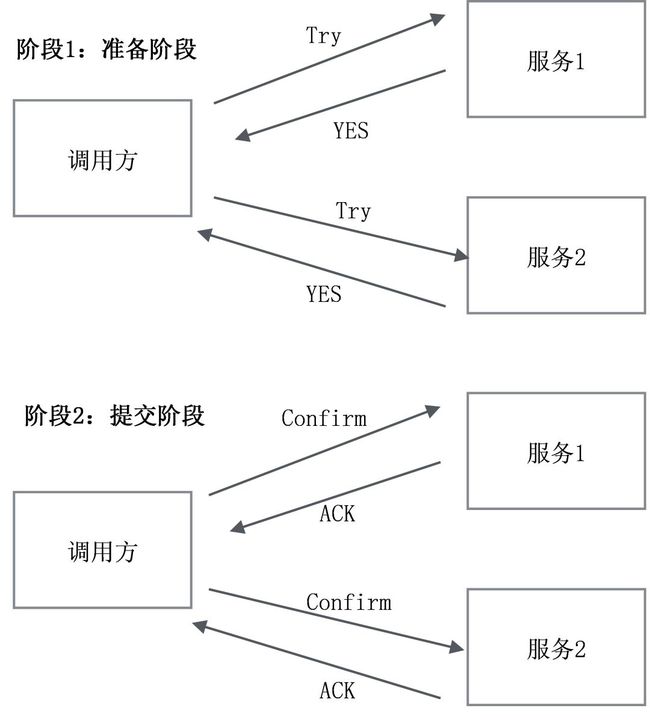
图10-6 TCC事务提交示意图
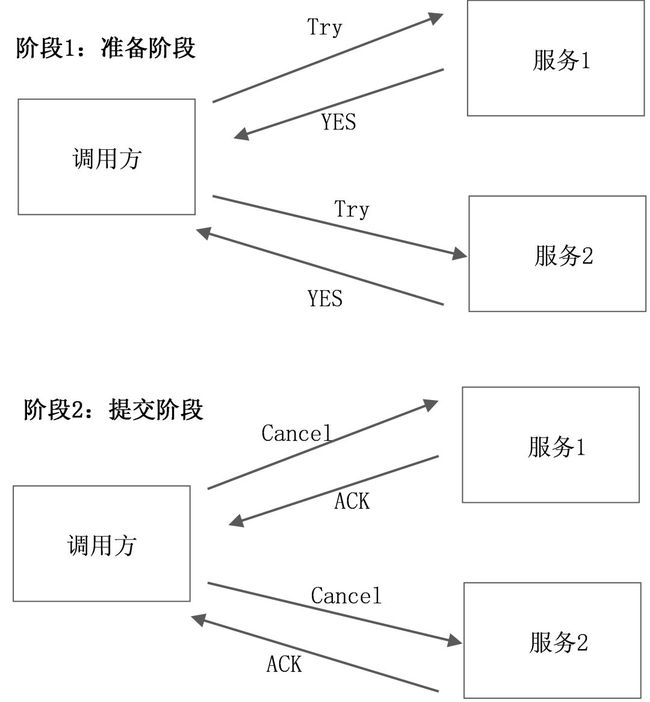
图10-7 TCC事务回滚示意图
这里有一个关键问题:TCC既然也借鉴2PC的思路,那么它是如何解决2PC的问题的呢?也就是说,在阶段2,调用方发生宕机,或者某个服务超时了,如何处理呢?
答案是:不断重试!不管是Confirm失败了,还是Cancel失败了,都不断重试。这就要求Confirm和Cancel都必须是幂等操作。注意,这里的重试是由TCC的框架来执行的,而不是让业务方自己去做。
下面以一个转账的事件为例,来说明TCC的过程。假设有三个账号A、B、C,通过SOA提供的转账服务操作。A、B同时分别要向C转30元、50元,最后C的账号+80元,A、B各减30元、50元。
阶段1:分别对账号A、B、C执行Try操作,A、B、C三个账号在三个不同的SOA服务里面,也就是分别调用三个服务的Try接口。具体来说,就是账号A锁定30元,账号B锁定50元,检查账号C的合法性,比如账号C是否违法被冻结,账号C是否已注销。
所以,在这个场景里面,对应的“扣钱”的Try操作就是“锁定”,对应的“加钱”的Try操作就是检查账号合法性,为的是保证接下来的阶段2扣钱可扣、加钱可加!
阶段2:A、B、C的Try操作都成功,执行Confirm操作,即分别调用三个SOA服务的Confirm接口。A、B扣钱,C加钱。如果任意一个失败,则不断重试,直到成功为止。
从案例可以看出,Try操作主要是为了“保证业务操作的前置条件都得到满足”,然后在Confirm阶段,因为前置条件都满足了,所以可以不断重试保证成功。