【6Dof位姿估计】DenseFusion: 6D Object Pose Estimation by Iterative Dense Fusion论文理解
DenseFusion: 6D Object Pose Estimation by Iterative Dense Fusion论文理解
- 本文创新点\贡献
- 本文IDEA来源
- 方法
- 方法概述
- 特征提取
- Dense color image feature embedding
- Dense 3D point cloud feature embedding
- Pixel-wise Dense Fusion
- 预测Pose
- 6D Object Pose Estimation
- Iterative Refinement
- 实验结果
- 总结
本文创新点\贡献
RGB-D对于少纹理和暗光条件不错,使用RGBD生成了点云信息
- 提出了能结合颜色和深度信息的方法
- 不需要ICP的端到端的微调网络
论文代码
本文IDEA来源
RGB和深度信息各有特点,而想解决一些复杂环境非融合不行,所以就想融合做
- 保持原本数据结构的情况下融合特征
- 通过探索不同数据间的本质映射来稠密的逐像素混合
方法
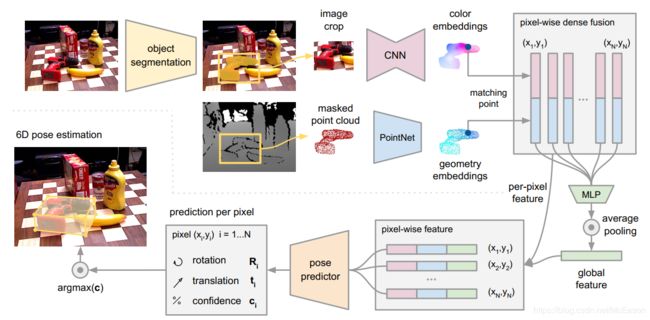
方法概述
两阶段,第一阶段生成语义分割,然后,对于每个分割的对象,将masked深度像素(转换为3D点云)和一个被mask的边界框裁剪的图像patch提供给第二阶段。
第二阶段包括四个部分:
- 一个全卷积网络,将crop的图像颜色信息映射成颜色特征嵌入
- 用PointNet处理masked3D点云,将每个点加工成一个几何特征嵌入
- 逐像素的融合,合并两个嵌入,输出基于无监督置信度评分的物体6D姿态估计
- 迭代的自微调方法,循环训练网络
特征提取
Semantic Segmentation:
预测 N + 1 N+1 N+1个通道,每个通道都是二值化的Mask,使用的现成的分割框架[ posecnn 2017]
分开提取的原因:
虽然在RGB帧和depth帧的形式相似,但是信息存在的空间不同,所以分开生成嵌入信息,来保证本质信息不变
Dense color image feature embedding
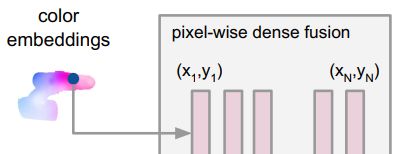
目标:
提取能在3D点特征和图像特征建立稠密对应的每个像素点特征的网络
作用:
这个网络是一个编码-解码结构,将 H × W × 3 H \times W \times 3 H×W×3映射到 H × W × d r g b H \times W \times d_{rgb} H×W×drgb的特征空间,每个位置的特征向量都代表对应位置的输入信息的表面特征
结构:
由Resnet-18和4个上采样层组成,输出通道是128
Dense 3D point cloud feature embedding
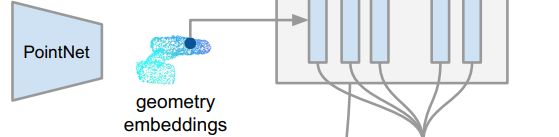
输入:
利用相机内参转换成了点云,使用PointNet相似的机构来提取几何特征
改动:
PointNet提出使用对称结构(max-pooling)在处理无序点集时实现排列不变性。原始体系结构将原始点云作为输入,并学习对每个点附近的信息和点云作为一个整体进行编码,作者提出几何嵌入网络,通过映射每个 P P P点到一个 d g e o d_{geo} dgeo 维度的特征空间来生成稠密的每个点特征,但是做了改动,使用average-pooling而不是max-pooling
结构:
MLP + 平均池化reduction函数,输出通道是128
Pixel-wise Dense Fusion

提出动机:
从分割的地方生成稠密的颜色和深度特征,但是遮挡和分割错误会让前面包含一些其他物体的像素特征,还有可能有一些背景的特征,所以这个网络能解决这个问题
操作:
局部全像素融合,而不是全局融合,仔细的选择物体看的见的部分,并且最小化遮挡和分割的噪声
为什么局部融合能有这样的效果,是怎么做的呢?
答:局部应该就是使用crop的意思,每次把crop放入网络的
为什么对之前做的分类的实验没有用呢?
密集融合程序首先将每个点的几何特征与对应的图像特征像素关联起来,这些特征像素是基于已知摄像机固有参数在图像平面上的投影的
就是3D点和对应的外形特征咯,就是上面的两个嵌入向量咯,关联是什么意思?如何关联?
答:关联就是按照3D点和3D点投影的2D点一一对应的关系,feature map连接到一起,特征像素就是图像上的点
前面获得的特征对连起来,送到另一个网络使用对称的减函数来生成固定大小的全局特征向量
对称减函数就是平均池化
然后使用全局稠密融合特征(就是这一步生成的,绿色)来自充实每个稠密像素特征(前面的红色和蓝色),以此来提供全局上下文
就是利用这个信息提取了全局特征后,有把提取的全局特征结合回去了,这样添加了一个全局的上下文信息
然后把最后的全像素的特征送到一个神经网络里,每个生成一个位姿预测,所以就是一系列位姿 P P P,然后用自监督的方法选一个最好的,思想来自[ Pointfusion: Deep sensor fusion for 3d bounding box estimation 2017]
或许跟那个M的生成差不多?比较下二者选择的差异,那个是选中位数
nice兄弟
预测Pose
Per-pixel self-supervised confidence:
使用网络对每个预测输出置信度 c i c_i ci
6D Object Pose Estimation
不对称情况,计算用pose变换之后的距离:
L i p = 1 M ∑ j ∣ ∣ ( R x j + t ) − ( R ^ i x j + t ^ i ) ∣ ∣ L^p_i = \frac{1}{M}\sum_j||(Rx_j + t) - (\hat{R}_ix_j + \hat{t}_i)|| Lip=M1j∑∣∣(Rxj+t)−(R^ixj+t^i)∣∣
其中 x j x_j xj表示 M M M的第 j j j 个点,这些点是随即从该3D模型里选择的, i i i表示在所有的稠密像素中第 i i i个混合特征生成的位姿
这个意思就是所有的预测都挺准的,才算好吗?然后从中算最优还是生成最优呢?我觉得生成比较好
对称情况,最小化最近的那个距离:
L i p = 1 M ∑ j min 0 < k < M ∣ ∣ ( R x j + t ) − ( R ^ i x k + t ^ i ) ∣ ∣ L^p_i = \frac{1}{M}\sum_j\min_{0
这个意思是对于每个挑出来的3D点,都要和所有的点算一下距离,取最小的那个,计算量加了很多,这样就能学好吗?感觉这块处理的并不好
答:其实是用的knn找点的对应,然后算distance
所有的loss就是:
L = 1 N ∑ i L i p L = \frac{1}{N}\sum_iL^p_i L=N1i∑Lip
加上置信度做正则化后:
L = 1 N ∑ i ( L i p c i − w log ( c i ) ) L = \frac{1}{N}\sum_i(L^p_ic_i - w\log(c_i)) L=N1i∑(Lipci−wlog(ci))
其中 N N N是从所有的预测 P P P中随机采样的, w w w是用来平衡的超参,设为0.01
为什么是这样的,而不是之前常见的除法呢?
这样的话,置信度高的就比较平滑,大家都差不多,而置信度低的,差距就很大,而前面的置信度越低loss越低是不合理的,所以第二项就蛮有效果
不过感觉还是不太科学,还要引入这种超参
选择置信度最高的作为最后的结果
Iterative Refinement
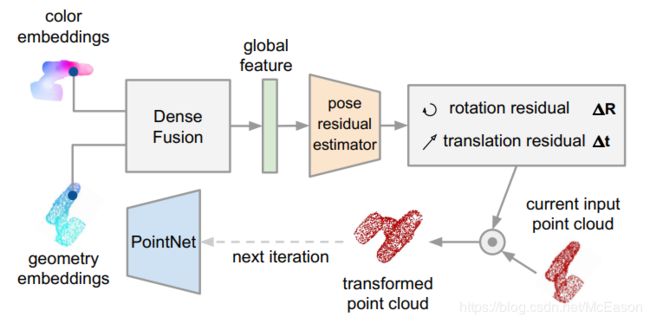
输入准备:
将点云按照预测出来的pose做对应变换,得到变换后的点云
操作:
使用单独的一个新的网络,但是还是用到了之前的嵌入特征,不过输入的是全局特征(绿色)而不是三合一特征,经历 K K K次迭代获得最后最好的pose:
p ^ = [ R K ∣ t K ] ⋅ [ R K − 1 ∣ t K − 1 ] ⋅ ⋅ ⋅ [ R 0 ∣ t 0 ] \hat{p} = [R_K|t_K] \cdot [R_{K-1}|t_{K-1}] \cdot \cdot \cdot [R_0|t_0] p^=[RK∣tK]⋅[RK−1∣tK−1]⋅⋅⋅[R0∣t0]
然而在代码中微调网络的输入只有新生成的点云和图像的嵌入坐标,并没有涉及最初的点云特征
结构:
四个卷积层组成,这里设 K = 2 K=2 K=2,后期才用,一开始的时候初始位姿太垃圾,微调也学不到啥
通过点云来微调可能确实不错,全局特征那里有正确的点云信息,点云之间微调必然是比投影到RGB再微调好吧
实验结果
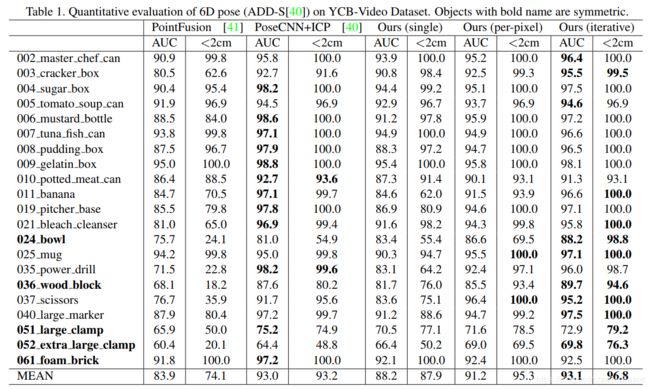
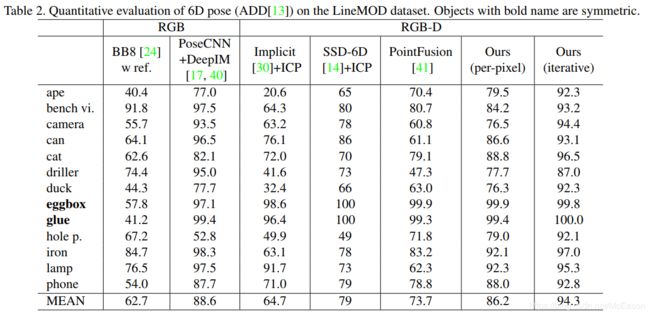
感觉分都很高了呀,但是实际预测的时候感觉不是那么理想:



总结
感觉对点云的利用还不是很充分?应该能提供更多的约束?