PifPaf: Composite Fields for Human Pose Estimation
发表于arxiv, 一个bottom-up的方法, 用来预测单张图片中多个人体的关节点位置, 已开源
arxiv地址: https://arxiv.org/abs/1903.06593
github地址: https://github.com/vita-epfl/openpifpaf
contribution
- bottom-up, box-free, end-to-end cnn architecture
- 提出
Part Intensity Field (PIF)用来定位人体关节点位置 - 提出
Part Association Field (PAF)用来确定关节点之间的连接
主要内容
通过预测图片中每个位置的Pif信息, 来确定图片上的位置是否是人体关节点位置; 并通过paf信息把同属于同一个人的人体关节点连接起来, 这样就可以 1) 预测出图片上所有人的关节点 2) 把属于同一个人的人体关节点连接起来. 在 COCO keypoint task 上达到了state-of-the-art, 打败了目前所有的bottom-up方法, 按照文章的说法, 比openpose提高了大约AP/AR12个点左右.
Pif label
Pif label是confidence map和regression map的结合, 最早出现在Google发表在CVPR 2017的"Towards Accurate Multi-person Pose Estimation in the Wild". 在Google的这篇文章中, Piflabel只有三个值: confidence score, x offset, y offset. PifPaf文章对这个Pif label进行了扩充, 增加了额外的两个选项: spread b, scale. 具体来说, 就是对于输出的PIF label,是一个(b, h, w, 17, 5)的输出, 17代表需要预测的关键点个数, 5表示: { p c i , j , p x i , j , p y i , j , p b i , j , p σ i , j } \{p^{i,j}_{c}, p^{i,j}_{x}, p^{i,j}_{y}, p^{i,j}_{b}, p^{i,j}_{\sigma} \} {pci,j,pxi,j,pyi,j,pbi,j,pσi,j}. 也即是, PIF会预测出每个输出channel上每个位置的 { p c i , j , p x i , j , p y i , j , p b i , j , p σ i , j } \{p^{i,j}_{c}, p^{i,j}_{x}, p^{i,j}_{y}, p^{i,j}_{b}, p^{i,j}_{\sigma} \} {pci,j,pxi,j,pyi,j,pbi,j,pσi,j}, 其中 p c i , j p^{i,j}_{c} pci,j表示该点的confidence, p x i , j p^{i,j}_{x} pxi,j和 p y i , j p^{i,j}_{y} pyi,j表示该点的x_offset和y_offset, p b i , j p^{i,j}_{b} pbi,j是用来参与loss计算的参数, p σ i , j p^{i,j}_{\sigma} pσi,j用来表示该点的尺度信息, 在生成pif label的过程中, 人越大, p σ i , j p^{i,j}_{\sigma} pσi,j越大.
有个这个Pif label, 就可以根据 p c i , j p^{i,j}_{c} pci,j和 p x i , j p^{i,j}_{x} pxi,j, p y i , j p^{i,j}_{y} pyi,j得到位置精度更高的confidence map. 下图展示了这个过程, (a)是Pif label里的 p c i , j p^{i,j}_{c} pci,j, (b)是 p x i , j p^{i,j}_{x} pxi,j和 p y i , j p^{i,j}_{y} pyi,j, © 是三者融合之后的结果. 可以看出来点的位置更精确, 中心处的响应值更高, 边缘处更低.
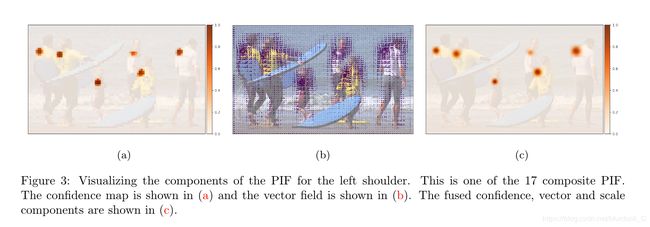
得到©的的结果, 通过一个unnormalized Gaussian kernel N N N 和 p σ i , j p^{i,j}_{\sigma} pσi,j来确定新的confidence map: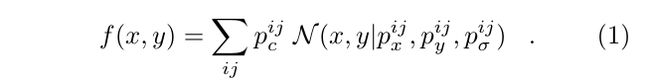
这个kernel和Google CVPR 2017那篇文章采用的bilinear interpolation kernel一直搞不清楚是啥. 看源码中这个unnormalized Gaussian kernel就是对pif label做functional.pyx 里的 scalar_suare_add_gauss操作, 这个操作是把pif里面的值都返回到原图输入大小来做的. 具体步骤大概就是针对原来位置上的点, 以这个点为中心取一定的范围, 然后求得范围内的点的offset, 然后做一个高斯核的操作, 最后把这个值和原来的值相加得到最后的 f ( x , y ) f(x,y) f(x,y).
# for minxx, minyy, maxxx, maxyy, vv in zip(minx, miny, maxx, maxy, v):
for i in range(l):
# x[i], y[i]就是 pif_fields的offset, l是长度, 这个长度应该就是究竟有多少个点需要参与运算
for xx in range(minx[i], maxx[i]):
deltax = xx - x[i]
for yy in range(miny[i], maxy[i]):
deltay = yy - y[i]
vv = v[i] * exp(-0.5 * (deltax**2 + deltay**2) / sigma[i]**2)
field[yy, xx] += vv
Pif label的生成过程是首先划定好每个groundtruth point的表示范围. 源码中是默认设置为4, 即已groundtruth point为中心左右上下各2个像素, 这个范围内的 p c i , j p^{i,j}_{c} pci,j全为1, 其余地方为0. 同样是在这个范围内, 计算每个位置到groundtruth point的x_offset, y_offset.
Paf label
类似于Pif label, Paf label部分的输出是(b, h, w, 17, 7), 17是需要预测的关键点个数, 7代表{ a c i j a^{ij}_{c} acij, a x 1 i j a^{ij}_{x1} ax1ij, a y 1 i j a^{ij}_{y1} ay1ij, a b 1 i j a^{ij}_{b1} ab1ij, a x 2 i j a^{ij}_{x2} ax2ij, a y 2 i j a^{ij}_{y2} ay2ij, a b 2 i j a^{ij}_{b2} ab2ij}. a c i j a^{ij}_{c} acij代表位置(i,j)的confidence, ( a x 1 i j a^{ij}_{x1} ax1ij, a y 1 i j a^{ij}_{y1} ay1ij), ( a x 2 i j a^{ij}_{x2} ax2ij, a y 2 i j a^{ij}_{y2} ay2ij)分别表示该点到真正的两个groundtruth point 的(x_offset, y_offset). a b 1 i j a^{ij}_{b1} ab1ij, a b 2 i j a^{ij}_{b2} ab2ij是相对应的两个用来计算loss的值.
生成featuremap某个位置上的PAF components步骤需要两步: 1) 找到离该位置最近的一个点. 2) 一旦一个点确定, 根据groundtruth, 我们就能确定另外一个点的位置从而确定PAF值. 例如我们需要生成头-脖子这个连接, 那么对于某个位置(i,j), 首先找到离它最近的头部点或者脖子点, 假设我们找到了一个离它最近的头部点, 那么根据groundtruth, 我们知道和这个头部点应该相连的脖子点是哪个, 就可以确定 ( a x 1 i j a^{ij}_{x1} ax1ij, a y 1 i j a^{ij}_{y1} ay1ij), ( a x 2 i j a^{ij}_{x2} ax2ij, a y 2 i j a^{ij}_{y2} ay2ij)了. a b 1 i j a^{ij}_{b1} ab1ij, a b 2 i j a^{ij}_{b2} ab2ij并不在Paf label中, 而是网络预测出来的, 通过参与loss计算自动的修改这个值.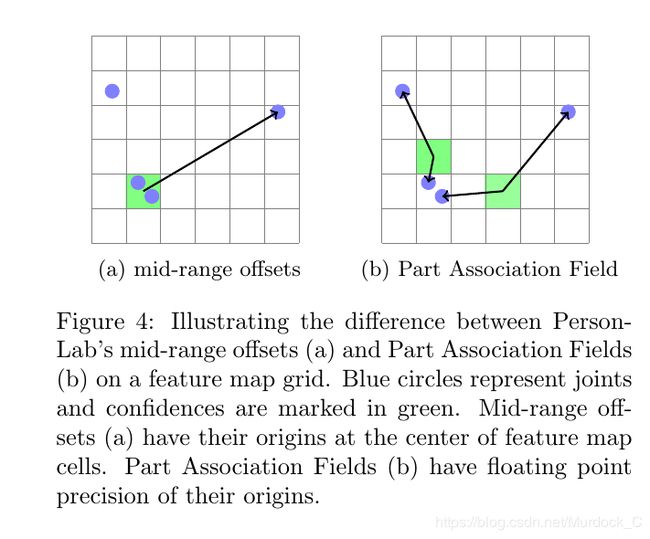
Loss 计算
文章使用的Loss计算分为三类:
- 二分类loss, 使用
binary_cross_entropy_with_logits计算该点是不是有可能是Pif上的关键点或者Paf上的连接处, 就是计算 p c i , j p^{i,j}_{c} pci,j和 a c i , j a^{i,j}_{c} aci,j. - 回归loss, 使用
laplace_loss计算pif, paf里的offset. 其中用到了pif paf预测出来的 p b i j p^{ij}_{b} pbij, a b i j a^{ij}_{b} abij, 计算公式: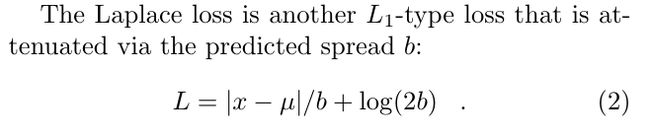
- scale loss. 使用
torch.nn.functional.l1_loss计算pif的 p σ i j p^{ij}_{\sigma} pσij.
三种loss加在一起就是整个网络的总Loss.
Greedy Decoding
找到了点, 也找到了合适的连接线段, 那么需要把同属于同一个人的线段都连起来. 文章使用了PersonLab: Person Pose Estimation and Instance Segmentation with a Bottom-Up, Part-Based, Geometric Embedding Model使用的Greedy decoding方法来做. 具体来说, 首先根据输出的Paf信息重新计算每个连接线段的score值, 计算方式为: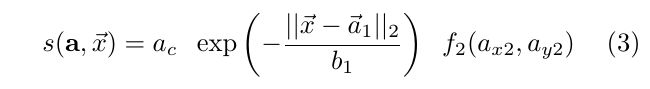
a c a_{c} ac就是paf里的 a c i , j a^{i,j}_{c} aci,j, f 2 ( a x 2 , a y 2 ) f_{2}(a_{x2}, a_{y2}) f2(ax2,ay2)就是公式(1)计算得到的新的confidence map, a ⃗ 1 , b 1 \vec a_{1} , b_{1} a1,b1分别表示paf信息的 ( a x 1 i j a^{ij}_{x1} ax1ij, a y 1 i j a^{ij}_{y1} ay1ij), a b 1 i j a^{ij}_{b1} ab1ij. 因为根据文章的方法, 两个应该连接的关键点之间会有几处点用来连接两个点, 就像图4(b)一样, 两个点之间会有一个点(或者多个点, paf label生成的时候默认三个点或者一个点, 选择方式是两点之间的[0.4, 0.5, 0.6]或者只有[0.5]offset). 再确定一个点之后, 会采用target_with_median or target_with_maxscore方法其中一个来确定另外一个连接点, 这样就找到了另外一个关节点.因为在确定一个点之后, 它对应的paf_fields就可以找到. 首先计算出连接这个点的所有线段的score, target_with_median的意思就是计算剩下的paf_fields的x,y坐标和这个线段的score相乘求平均, 得到一个target x, y. 以下图为例, 就是

先找到线段1的score:
target_with_median就是和2做平均, (x, y)和score相乘然后求平均, 就是target point 的(x, y)target_with_max就是找到1中最大的score所处的位置, 直接取对应的线段2的点的值,就是target point的(x,y)
为了确保根据paf找到的两个点确实是应该连到一起的, 程序会执行reverse操作, 即如果通过point a找到了point b, 那么就会从point b找到point c, 如果point a和point c之间的距离小于设定好的阈值, 那么就说明这两个点应该被连在一起. 计算出来哪些点需要连在一起之后, 从随机的一个点出发作为种子点, 然后去找和它连接的最大可能性的线段的点, 持续的进行下去, 直到一个完整的pose被找到或者没有满足条件的点为止.