Java如何进行读取文件(1)—IO流

一、FileInputStream、FileoutputStream
(一)FileInputStream
(1)read()方法
(a)不加改造的read()方法
FileInputStream fis = null;
try {
// fis = new FileInputStream("C:\\Users\\赵晓东\\Desktop\\javaIO\\FileInputStream.txt");
// /*相对路径一定是从当前所在的位置作为起点开始找*/
/*IDEA默认的当前路径是哪里?*/
fis = new FileInputStream("abc.txt");
int readDate= fis.read();
System.out.println(readDate);
} catch (FileNotFoundException e) {
e.printStackTrace();
} catch (IOException e) {
e.printStackTrace();
} finally {
try {
if(fis !=null){
fis.close();
}
} catch (IOException e) {
e.printStackTrace();
}
}我的abc文件中写的是abc,读取的结果为:
97可见它只能读取一个,并且最后一定要在finally里面写一个关闭的方法。避免浪费资源。fis.close();l
(b)加上while循环的read()方法
如果我们想让它一直读取怎么办呢?这时候就要用到了循环。
FileInputStream fis = null;
try {
fis = new FileInputStream("abc.txt");
int readCount = 0;
while (readCount !=-1){
readCount =fis.read();
if(readCount ==-1){
break;
}
System.out.println(readCount);
}
} catch (FileNotFoundException e) {
e.printStackTrace();
} catch (IOException e) {
e.printStackTrace();
} finally {
if(fis!=null){
try {
fis.close();
} catch (IOException e) {
e.printStackTrace();
}
}
}解释:当它读到最后会返回一个-1代表读完了。
(c)读取多个的read(byte[] b)
- int
- read(byte[] b)
- 从该输入流读取最多 b.length个字节的数据为字节数组。
这样可以一次最多读取b.length个字节,减少了硬盘和内存的交互,提高程序的执行效率,往byte[]数组当中读。
首先,我在zxd文件中写了abcdef,int readCount表示返回的是读取的数量。
FileInputStream fis = null;
try {
fis = new FileInputStream("zxd");
/*第一次读*/
byte[] bytes = new byte[4];
int readCount = fis.read(bytes);
System.out.println(readCount);
/*第二次读*/
readCount = fis.read(bytes);
System.out.println(readCount);
/*第三次读*/
readCount = fis.read(bytes);
System.out.println(readCount);
} catch (FileNotFoundException e) {
e.printStackTrace();
} catch (IOException e) {
e.printStackTrace();
} finally {
try {
if(fis!=null){
fis.close();
}
} catch (IOException e) {
e.printStackTrace();
}
}读取的结果
4
2
-1并且在第二次读的时候,会把前面ab会覆盖了。下面我们用图来模拟一下。
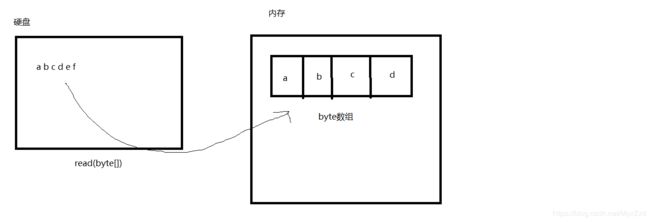
第一次读的时候,会把abcdef中的abcd读入到数组里面。
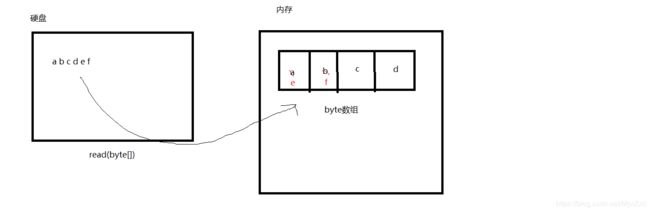
第二次读的时候,ef会把前面ab覆盖了。
(2)available()
这个表示返回流当中剩余的没有读到的字节数量
intavailable()返回从此输入流中可以读取(或跳过)的剩余字节数的估计值,而不会被下一次调用此输入流的方法阻塞。
FileInputStream fis = null;
fis = new FileInputStream("zxd");
int allNumber=fis.available();
System.out.println(allNumber);6可见available返回的是文件的大小。正好可以通过它,传入到数组中然后这样就可以直接读取了。
FileInputStream fis = null;
fis = new FileInputStream("zxd");
int allNumber=fis.available();
System.out.println(allNumber);
byte [] bytes = new byte[allNumber];
int number =fis.read(bytes);
System.out.println(new String(bytes));6
abcdef这样就可以通过avaliable方法获得文件大小,然后再用数组进行声明,直接用read方法进行读取,就不会浪费,也不会因为空间太小了。
(3)skip跳过几个字节不读取
- long
- skip(long n)
- 跳过并从输入流中丢弃 n字节的数据。
FileInputStream fis = null;
fis = new FileInputStream("zxd");
fis.skip(3);
System.out.println(fis.read());跳过3个正好读取的是d,也就是100了。
100(二)FileoutputStream
(1)Wirte()方法进行写
voidwrite(byte[] b)将
b.length个字节从指定的字节数组写入此文件输出流。
voidwrite(byte[] b, int off, int len)将
len字节从位于偏移量off的指定字节数组写入此文件输出流。
也可以全写进去,也可以只写一部分。
FileOutputStream fot = null;
try {
fot = new FileOutputStream("myfile");
byte [] bytes = {97,98,99,100};
fot.write(bytes);
/*一定要进行刷新*/
fot.flush();
} catch (FileNotFoundException e) {
e.printStackTrace();
} catch (IOException e) {
e.printStackTrace();
} finally {
try {
fot.close();
} catch (IOException e) {
e.printStackTrace();
}
}这时候,我们会看见idea里面多了一个myfile文件,里面还有abcd

如果没有myfile文件会新建,如果有则直接输入。输入的时候会把源文件情况,再输入。所以谨慎使用。
下面这种方式是以追加的方式在末尾写入,不会情况源文件内容。
FileOutputStream(String name, boolean append)创建文件输出流以指定的名称写入文件。

 这时候我们会发现myfile文件中追加了abcd
这时候我们会发现myfile文件中追加了abcd
将字符串转换成数组的形式进行追加


三、FileReader、FileWriter
文件字符输入流,只能读取普通文本,读取文本内容时,比较方便,快捷。这次就变成了char[]数组了。他们两个的方法和FileInputStream和FinleoutputStream一样。
四、带有缓冲区的字符流(这时候就不需要char byte数组了,自带有缓冲区)
(一)BufferedReader
带有缓冲区的字符输入流。使用这个流的时候,不需要自定义char数组,或者说不需要自定义byte数组。自带缓冲。
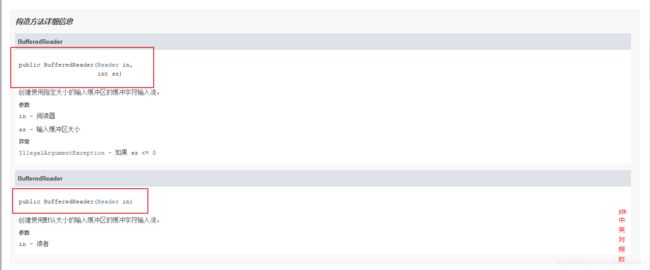
从构造方法可以看出,如果要实例一个BufferedReader,里面需要传入一个流。
FileReader reader = new FileReader("zxd");
/**/
BufferedReader br = new BufferedReader(reader);
/*关闭流*/
br.close();当一个流的构造方法中,需要一个流的时候,被传进来的流叫做节点流。外部负责包装的流,叫做:包装流。还有一个名字叫做:处理流。


从源代码可以看出,当我们关闭流的时候,只需要关闭最后一个即可。
bufferedReader.readLine()能读一行。但是不带换行符。
(a)如果字节流想传进入怎么办?
这时候需要通过InputStreamReader

这时候报错,的原因是字节流不能作为BufferedReader的参数,所以这时候需要InputStreamReader

(1) readline()
FileReader reader = new FileReader("zxd");
/**/
BufferedReader br = new BufferedReader(reader);
String s1 =br.readLine();
System.out.println(s1);
/*关闭流*/
br.close();abcdef
readline()读取直接读取一行。
接下来,我们可以对它进行循环。
String s = null;
while ((s=br.readLine())!=null){
System.out.println(s);
}但是readline()不带换行符。
(2)当我们想往BufferedReader中传入字节流可以吗?(FileInputStream)

可以看出,是不可以的。
这个时候需要使用转换流了。(将字节流转换成字符流)
java.io.InputStreamReader
java.io.outputStreamWriter
InputStreamReader(InputStream in)创建一个使用默认字符集的InputStreamReader。
通过 构造方法可以看出InputStreamReader里面可以传入InputStream的。

这个时候就不报错了。
(二)BufferedWriter
FileWriter f1 = new FileWriter("zjy");
BufferedWriter br = new BufferedWriter(f1);
/*进行文件的写工作*/
br.write("hahah");
/*刷新*/
br.flush();
/*关闭包装流/
*/
br.close();当然,你想追加,可以构造方法哪里写true。同样,如果想用字节流(Inputoutstream)也是需要转换流的。(outputStreamReader)
五、PrintStream标准的字节输出流(默认输出到控制台)
我们平时输出的:
System.out.println("Hello World");其实,就是这个字节输出流
PrintStream ps = System.out
ps.println("Hello World");当然它不需要关闭close().
那么可以输出改变方向吗?
/*指向一个日志文件*/
PrintStream out = null;
try {
out = new PrintStream(new FileOutputStream("log.txt",true));
/*改变输出方向*/
System.setOut(out);
/*日期当前时间*/
Date nowTime = new Date();
SimpleDateFormat sdf = new SimpleDateFormat("yyyy-MM-dd HH:mm:ss SSS");
String strTime = sdf.format(nowTime);
System.out.println(strTime +":"+msg);
} catch (FileNotFoundException e) {
e.printStackTrace();
}public class LogTest {
public static void main(String[] args) {
/*测试工具类*/
Logger.log("调用gc,启动垃圾回收");
Logger.log("用户尝试进行登录");
}
}可以,以上就是日志工具的实现原理。
六、对象专属的流ObjectInputStream、ObjectOutputStream
(1)序列化ObjectOutputStream
对象的序列化(Serialize)和反序列化(DeSerialize)
将内存中的Java对象放到硬盘文件上叫序列化,是因为内存中的Java对象切割成一块一块的并且编号,放到硬盘文件上。
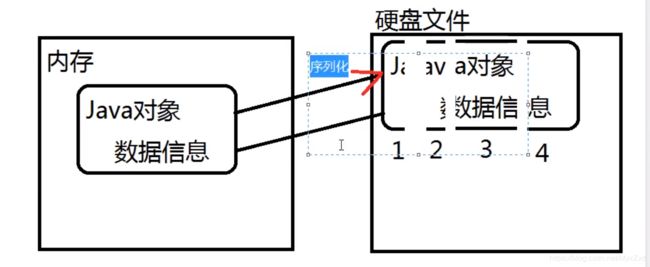
如果从硬盘文件恢复到内存中,那么叫反序列化。
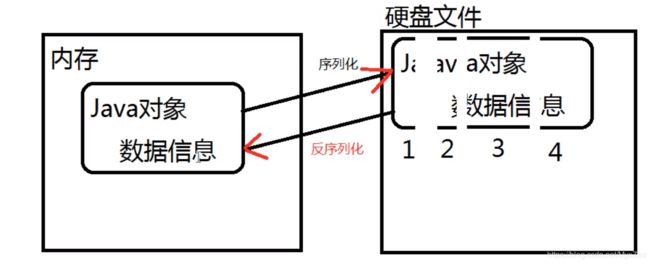
一个是拆分一个是组装。
如果需要序列化就是需要ObjectOutputStream了。如果反序列化就是需要ObjectInputStream了。
下面用个例子说明一下:
首先写一个Student类
public class Student {
private int no;
private String name;
public Student(int no, String name) {
this.no = no;
this.name = name;
}
public Student(int no) {
this.no = no;
}
public Student(String name) {
this.name = name;
}
public Student() {
}
public int getNo() {
return no;
}
public void setNo(int no) {
this.no = no;
}
public String getName() {
return name;
}
public void setName(String name) {
this.name = name;
}
} public static void main(String[] args) throws Exception{
/*进行序列化例子*/
Student s1 = new Student(1,"赵晓东");
/*通过流去给一个文件students为文件的名字*/
FileOutputStream f1 = new FileOutputStream("Students");
/*调用ObjectOutputStream*/
ObjectOutputStream o1 = new ObjectOutputStream(f1);
/*调用方法进行序列化*/
o1.writeObject(s1);
/*刷新*/
o1.flush();
/*关闭流*/
o1.close();
}
}
Exception in thread "main" java.io.NotSerializableException: com.javase.IO.Student
at java.io.ObjectOutputStream.writeObject0(ObjectOutputStream.java:1184)
at java.io.ObjectOutputStream.writeObject(ObjectOutputStream.java:348)
at com.javase.IO.ObjectOutputStreamTest.main(ObjectOutputStreamTest.java:16)这时候我们看见会报错。这个异常的意思是Student不支持序列化。然后我们让student去实现Serializable

这时候会有Students文件,并且是乱码的形式

所以参与序列化和反序列化的对象必须实现Serializable接口
这个接口当中什么都没有,那么它起到什么作用呢?起到了标识的作用,JVM看见了它会特殊待遇。JAVA中有两种接口,一种是普通接口,另一种是标志接口,标识接口是给JVM虚拟机看的。
JVM看到Serializable会自动生成一个序列化版本号。
(2)反序列化ObjectInputStream
public static void main(String[] args) throws Exception{
/*创建流读取文件*/
FileInputStream f1 = new FileInputStream("Students");
/*进行反序列化*/
ObjectInputStream o1 = new ObjectInputStream(f1);
/*调用方法*/
Object ob =o1.readObject();
System.out.println(ob);
o1.close();
}
}(3)能不能一次序列化多个对象
可以,可以将序列化放到集合当中,序列化集合。
User类
public class User implements Serializable {
private int id;
private String name;
public User(int id, String name) {
this.id = id;
this.name = name;
}
public User() {
}
@Override
public String toString() {
return "User{" +
"id=" + id +
", name='" + name + '\'' +
'}';
}
}
序列化
public static void main(String[] args) throws Exception{
/*创建集合*/
List l1 = new ArrayList<>();
l1.add(new User(1,"哈哈哈"));
l1.add(new User(2,"呵呵呵"));
l1.add(new User(3,"嘿嘿嘿"));
// 通过流去读取
FileOutputStream f1 = new FileOutputStream("Users");
// 序列化
ObjectOutputStream o1 = new ObjectOutputStream(f1);
// 调用序列化方法
o1.writeObject(l1);
o1.flush();
o1.close();
}结果

(4)transient表示不参加序列化操作
private transient String name;(5)关于序列化版本号
Java虚拟机看到Serializable接口之后,会自动生成了一个序列化版本号,这里没有手动手写处理,java虚拟机会默认提供这个序列化版本号。
java语言中采用什么机制来区分类的?
第一:首先通过类名进行区分,如果类名不一样,肯定不是一个类。
第二:如果类名一样,再怎么进行类的区别?靠序列化版本号进行区分。

这种自动生成序列化版本号有什么缺陷?
一旦自动生成的序列化版本号缺点是:一旦代码确定之后,不能进行后续的修改,因为只要修改,必然会重新编译,此时会生成全新的序列化版本号,这个时候java虚拟机会认为这是一个全新的类。
最终结论:
凡是一个类实现了Serializable接口,建议给该类提供一个固定不变的序列化版本号,这样,以后这个类即使代码修改了,但是版本号不变,java虚拟机会认为是同一个类。
所以建议将序列化版本号手动的写出来,不建议自动生成。
private static final long serialVersionUID=1L;总结:记得在一级的时候,不知道序列化是干什么的,不知道怎么去读取学生的文件的,现在终于是明白了。另外我发现流在读取的时候和集合的遍历很相似。