利用Python进行数据分析——python数据分析初窥
本文将要向你介绍的是用于高效处理数据的Python工具。虽然读者各自工作的最终目的千差万别,但基本都需要完成以下几个大类的任务:
- 与外界进行交互
读写各种各样的文件格式和数据库。 - 准备
对数据进行清理、修整、整合、规范化、重塑、切片切块、变形等处理以便进行分析。 - 转换
对数据集做一些数学和统计运算以产生新的数据集。比如说,根据分组变量对一个大表进行聚合。 - 建模和计算
将数据跟统计模型、机器学习算法或其他计算工具联系起来。 - 展示
创建交互式的或静态的图片或文字摘要。
我将在本章中给出一些范例数据集,并讲解我们能对其做些什么。这些例子仅仅是为了提起你的兴趣,因此只会在一个比较高的层次进行讲解。即使你从来没用过这些东西也没关系,本书后续的章节将会对此进行非常详细的讲解。
在这些代码示例中,你可以看到诸如In [15]:之类的输入输出提示符,它们来自IPython shell。
来自bit.ly的1.usa.gov数据
2011年,URL缩短服务bit.ly跟美国政府网站usa.gov合作,提供了一份从生成.gov或.mil短链接的用户那里收集来的匿名数据。
以每小时快照为例,文件中各行的格式为JSON(即JavaScript Object Notation,这是一种常用的Web数据格式)。例如,如果我们只读取某个文件中的第一行,那么你所看到的结果应该是下面这样:
In [15]: path = 'ch02/usagov_bitly_data2012-03-16-1331923249.txt'
In [16]: open(path).readline()
Out[16]: '{ "a": "Mozilla\\/5.0 (Windows NT 6.1; WOW64) AppleWebKit\\/535.11 (KHTML, like US,en;q=0.8", "hh": "1.usa.gov", "r": "http:\\/\\/www.facebook.com\\/l\\/7AQEFzjSi
Python有许多内置或第三方模块可以将JSON字符串转换成Python字典对象。这里,我将使用json模块及其loads函数逐行加载已经下载好的数据文件:
import json
path = 'ch02/usagov_bitly_data2012-03-16-1331923249.txt'
records = [json.loads(line) for line in open(path)]
现在,records对象就成为一组Python字典了:
{
'a': 'Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/535.11 (KHTML, like Gecko) Chrome/17.0.963.78 Safari/535.11',
'c': 'US',
'nk': 1,
'tz': 'America/New_York',
'gr': 'MA',
'g': 'A6qOVH',
'h': 'wfLQtf',
'l': 'orofrog',
'al': 'en-US,en;q=0.8',
'hh': '1.usa.gov',
'r': 'http://www.facebook.com/l/7AQEFzjSi/1.usa.gov/wfLQtf',
'u': 'http://www.ncbi.nlm.nih.gov/pubmed/22415991',
't': 1331923247,
'hc': 1331822918,
'cy': 'Danvers',
'll': [42.576698, -70.954903]
}
用纯Python代码对时区进行计数
假设我们想要知道该数据集中最常出现的是哪个时区(即tz字段),得到答案的办法有很多。首先,我们用列表推导式取出一组时区:
import json
path='pydata-book-master/ch02/usagov_bitly_data2012-03-16-1331923249.txt'
records=[json.loads(line) for line in open(path)]
time_zones=[rec['tz'] for rec in records if 'tz' in rec]
print(time_zones)
结果为:
['America/New_York', 'America/Denver', 'America/New_York', 'America/Sao_Paulo', 'America/New_York', 'America/New_York', 'Europe/Warsaw', '', '', '', 'America/Los_Angeles', 'America/New_York', 'America/New_York', 'America/New_York', 'Asia/Hong_Kong', 'Asia/Hong_Kong', 'America/New_York', 'America/Denver', 'Europe/Rome', 'Africa/Ceuta', 'America/New_York', 'America/New_York', 'America/New_York', 'Europe/Madrid', 'Asia/Kuala_Lumpur', 'Asia/Nicosia', 'America/Sao_Paulo', '', '', 'Europe/London', 'America/New_York', 'Pacific/Honolulu', 'America/Chicago', '', '', 'Pacific/Honolulu', '',
我们可以看到有些是未知的(即空的)。虽然可以将它们过滤掉,但现在暂时先留着。接下来,为了对时区进行计数,这里介绍两个办法:一个较难(只使用标准Python库),另一个较简单(使用pandas)。计数的办法之一是在遍历时区的过程中将计数值保存在字典中:
import json
from collections import defaultdict
def get_counts(sequece):
counts=defaultdict(int) #所有的值均被初始化为0
for s in sequece:
counts[s]+=1
return counts
path='pydata-book-master/ch02/usagov_bitly_data2012-03-16-1331923249.txt'
records=[json.loads(line) for line in open(path)]
time_zones=[rec['tz'] for rec in records if 'tz' in rec]
print(time_zones[:])
counts=get_counts(time_zones)
print(counts)
我将代码写到函数中是为了获得更高的可重用性。要用它对时区进行处理,只需将time_zones传入即可:

如果想要得到前10位的时区及其计数值,我们需要用到一些有关字典的处理技巧:
def top_counts(count_dict,n=10):
value_key_pairs={(count,tz) for tz,count in count_dict.items()}
return sorted(value_key_pairs)[-n:]
print(top_counts(count_dict=counts))
输出为:
[(33, 'America/Sao_Paulo'),
(35, 'Europe/Madrid'),
(36, 'Pacific/Honolulu'),
(37, 'Asia/Tokyo'),
(74, 'Europe/London'),
(191, 'America/Denver'),
(382, 'America/Los_Angeles'),
(400, 'America/Chicago'),
(521, ''),
(1251, 'America/New_York')]
你可以在Python标准库中找到collections.Counter类,它能使这个
任务变得更简单:
from collections import Counter
counts=Counter(time_zones)
print(counts.most_common(10))
![]()
用pandas对时区进行计数
DataFrame是pandas中最重要的数据结构,它用于将数据表示为一个表格。从一组原始记录中创建DataFrame是很简单的:
from pandas import DataFrame,Series
import pandas as pd
import numpy as np
import json
path='pydata-book-master/ch02/usagov_bitly_data2012-03-16-1331923249.txt'
records=[json.loads(line) for line in open(path)]
frame = DataFrame(records)
print(frame['tz'][:10])
0 America/New_York
1 America/Denver
2 America/New_York
3 America/Sao_Paulo
4 America/New_York
5 America/New_York
6 Europe/Warsaw
7
8
9
Name: tz, dtype: object
然后,我们想利用绘图库(即matplotlib)为这段数据生成一张图片。为此,我们先给记录中未知或缺失的时区填上一个替代值。fillna函数可以替换缺失值(NA),而未知值(空字符串)则可以通过布尔型数组索引加以替换:
clean_tz=frame['tz'].fillna('Missing') #缺失值就是缺少该'tz'的value
clean_tz[clean_tz=='']='Unknown' #空值就是含有'tz',但value=''
tz_counts=clean_tz.value_counts()
print(tz_counts[:10])
输出如下:
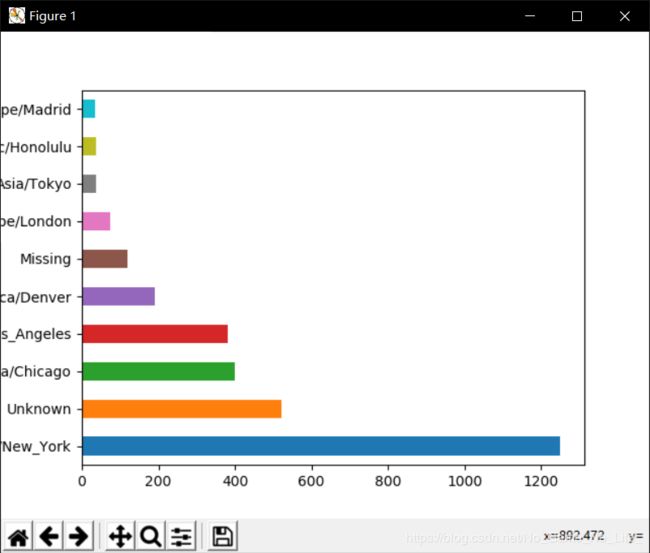
America/New_York 1251
Unknown 521
America/Chicago 400
America/Los_Angeles 382
America/Denver 191
Missing 120
Europe/London 74
Asia/Tokyo 37
Pacific/Honolulu 36
Europe/Madrid 35
利用counts对象的plot方法即可得到一张水平条形图:
import matplotlib.pyplot as plt
tz_counts[:10].plot(kind='barh',rot=0)
plt.show()
将这些"agent"字符串中的所有信息都解析出来是一件挺郁闷的工作。不过只要你掌握了Python内置的字符串函数和正则表达式,事情就好办了。比如说,我们可以将这种字符串的第一节(与浏览器大致对应)分离出来并得到另外一份用户行为摘要:
from pandas import DataFrame,Series
import pandas as pd
import numpy as np
import json
path='pydata-book-master/ch02/usagov_bitly_data2012-03-16-1331923249.txt'
records=[json.loads(line) for line in open(path)]
frame = DataFrame(records)
results=Series([x.split()[0] for x in frame.a.dropna()]) #dropna=drop N/A 去掉缺失值 x.split()以空格为界限
print(results[:5])
输出为:
0 Mozilla/5.0
1 GoogleMaps/RochesterNY
2 Mozilla/4.0
3 Mozilla/5.0
4 Mozilla/5.0
使用value_counts统计每个出现的频度:
print(results.value_counts()[:8])
输出为:
Mozilla/5.0 2594
Mozilla/4.0 601
GoogleMaps/RochesterNY 121
Opera/9.80 34
TEST_INTERNET_AGENT 24
GoogleProducer 21
Mozilla/6.0 5
BlackBerry8520/5.0.0.681 4
现在,假设你想按Windows和非Windows用户对时区统计信息进行分解。为了简单起见,我们假定只要agent字符串中含有"Windows"就认为该用户为Windows用户。由于有的agent缺失,所以首先将它们从数据中移除:
from pandas import DataFrame,Series
import pandas as pd
import numpy as np
import json
path='pydata-book-master/ch02/usagov_bitly_data2012-03-16-1331923249.txt'
records=[json.loads(line) for line in open(path)]
frame = DataFrame(records)
cframe=frame[frame.a.notnull()]
operating_system=np.where(cframe['a'].str.contains('Windows'),'Windows','Not Windows')
print(operating_system[:5])
输出为:
['Windows' 'Not Windows' 'Windows' 'Not Windows' 'Windows']
接下来就可以根据时区和新得到的操作系统列表对数据进行分组了:
by_tz_os = cframe.groupby(['tz', operating_system])
agg_counts = by_tz_os.size().unstack().fillna(0)
print(agg_counts[:10])
indexer = agg_counts.sum(1).argsort()
print(indexer[:10])
通过size对分组结果进行计数(类似于上面的value_counts函数),并利用unstack对计数结果进行重塑。
为了选取最常出现的时区,根据agg_counts中的行数构造了一个间接索引数组。
输出为:
Not Windows Windows
tz
245.0 276.0
Africa/Cairo 0.0 3.0
Africa/Casablanca 0.0 1.0
Africa/Ceuta 0.0 2.0
Africa/Johannesburg 0.0 1.0
Africa/Lusaka 0.0 1.0
America/Anchorage 4.0 1.0
America/Argentina/Buenos_Aires 1.0 0.0
America/Argentina/Cordoba 0.0 1.0
America/Argentina/Mendoza 0.0 1.0
tz
24
Africa/Cairo 20
Africa/Casablanca 21
Africa/Ceuta 92
Africa/Johannesburg 87
Africa/Lusaka 53
America/Anchorage 54
America/Argentina/Buenos_Aires 57
America/Argentina/Cordoba 26
America/Argentina/Mendoza 55
dtype: int64
暂且只介绍到这里,我们后面会对上面用到的没用到的函数进行一一分析,本文只是初窥门径。