SMPL, SMAL, SMALR, SMALST--单图像的人体+动物三维重建论文
SMPL(Skinned Multi-Person Linear Model)
SMPL: A Skinned Multi-Person Linear Model【Oct 2015】
摘要
我们提出了一种学习的人体形状和位置的形状变化模型,它比以前的模型更精确,并且与现有的图形管道兼容。我们的去皮肤多人线性模型(SMPL)是一种基于去皮肤的顶点的模型,它精确地表示了自然人体姿态中的各种体型。该模型的参数从数据中学习,包括位姿模板、混合权重、位置相关的混合形状、身份相关的混合形状,以及从顶点到关节位置的回归器。与以往的模型不同,位置相关的混合形状是位姿旋转矩阵元素的线性函数。这个简单的公式能够从大量的不同姿势的不同人体的三维网格中训练整个模型。我们使用线性或双四元数混合去除皮肤对SMPL的变体进行了定量评估,结果表明,这两种方法都比基于相同数据训练的Blend-SCAPE模型更精确。我们还将SMPL扩展到真实的动态软组织变形模型。由于SMPL基于混合去除皮肤的理念,所以它与现有的呈现引擎兼容,符合研究目标。
目标
这篇文章提出了一个使用pose和shape参数驱动的线性的人体模型,模型的主要参数有:rest pose template,blend weights,pose-dependent blend shapes,identity-dependent blend shapes,和一个从顶点到关节的regressor,这些参数都是是从训练数据中学习得来的。与之前的工作不同的是,pose-dependent blend shapes这一项是pose旋转矩阵的线性函数。这样使得从一个大型数据集里面训练这个模型成为可能的。
目标是创造一个可以表示不同形状的身体的,可以随着动作自然的变形的,并且软组织在运动过程中还能发生形变的人体模型
一般商业上的操作手法是手动操作网格,来修改使用传统模型时出的问题。人的工作量就比较大。也有人从扫描的人体数据集中学习一个统计的身体模型,但是与商用软件不兼容,没法使用。
因此SMPL模型的目标就是,既能使用,又能表示大范围的人体,还要能通过pose来自然的形变,还要有软组织的动力学,做动画的效率高,并且和现有的渲染引擎兼容。
现有的LBS模型( Linear Blend Skinning)是使用得最广泛的,他是建立顶点和骨架之间的关系。但是这个模型会出现一些问题。(如四元数、双四元数skinning,球面skinning)
模型
人体模型包含了 N N N = 6890个点,与 K K K = 23个关节。
模型的输入参数为形状参数 β \beta β,和动作参数 θ \theta θ,模型中包含以下几项:
-
T ˉ ∈ R 3 N \bar{\textbf{T}} \in \mathbb{R}^{3N} Tˉ∈R3N ,平均的模板形状 (mean template shape)
这个时候的pose是zero pose,( θ ∗ ⃗ \vec{\theta^*} θ∗)
-
W ∈ R N × K \mathcal{W}\in \mathbb{R}^{N\times K} W∈RN×K ,各个关节的混合权重
-
B S ( β ⃗ ) : R ∣ β ⃗ ∣ ↦ R 3 N B_S(\vec{\beta}):\mathbb{R}^{|\vec{\beta}|} \mapsto \mathbb{R}^{3N} BS(β):R∣β∣↦R3N ,blend shape函数,将shape参数映射到每一个点上
-
J ( β ⃗ ) : R ∣ β ⃗ ∣ ↦ R 3 K J(\vec{\beta}):\mathbb{R}^{|\vec{\beta}|} \mapsto \mathbb{R}^{3K} J(β):R∣β∣↦R3K ,将shape参数映射到每个joint的位置上
-
B P ( θ ⃗ ) : R ∣ θ ⃗ ∣ ↦ R 3 N B_P(\vec{\theta}):\mathbb{R}^{|\vec{\theta}|} \mapsto \mathbb{R}^{3N} BP(θ):R∣θ∣↦R3N ,将pose参数映射到每个点上
最终得到的结果就是 M ( β ⃗ , θ ⃗ ; Φ ) : R ∣ θ ⃗ ∣ × ∣ β ⃗ ∣ ↦ R 3 N M(\vec{\beta},\vec{\theta};\Phi):\mathbb{R}^{|\vec{\theta}|\times |\vec{\beta}|} \mapsto \mathbb{R}^{3N} M(β,θ;Φ):R∣θ∣×∣β∣↦R3N ,将shape和pose参数映射到每个点上。这里的 Φ \Phi Φ 指的是学习的模型的参数。
pose参数是使用axis-angle来定义的,对于每一个joint,都有一个 ω ⃗ k ∈ R 3 \vec{\omega}_k\in \mathbb{R}^3 ωk∈R3,然后加上原点处的,总共24个关节,就有72个参数。旋转矩阵是使用罗德里格旋转公式(Rodrigues’ rotation formula)计算得到
W ( T ˉ , J , θ ⃗ , W ) : R 2 N × 3 K × ∣ θ ⃗ ∣ × ∣ W ∣ ↦ R 3 N W(\bar{\mathbf{T}},\mathbf{J},\vec{\theta},\mathcal{W}):\mathbb{R}^{2N\times 3K\times|\vec{\theta}|\times |\mathcal{W}|} \mapsto \mathbb{R}^{3N} W(Tˉ,J,θ,W):R2N×3K×∣θ∣×∣W∣↦R3N ,将rest pose、joint location、pose参数、blend weights权重转化成每个点的坐标量。

以上转自博客:SMPL: A Skinned Multi-Person Linear Model 阅读笔记
结论
SMPL使用标准的皮肤方程并定义了修改基本网格的身体形状和姿态混合形状。对模型进行了数千次扫描,扫描对象是不同姿势的不同人体。模型的形式使得从大量的数据中学习参数成为可能,同时直接最小化顶点重建误差。具体来说,我们学习了rest模板、关节回归器、体型模型、姿势混合形状和动态混合形状。令人惊讶的结果是,当Blend-SCAPE和SMPL在完全相同的数据上进行训练时,基于顶点的模型比基于形变的模型更精确,且呈现效率更高。同样令人惊讶的是,相对较小的一组学习混合形状在纠正LBS的错误方面和在DQBS上做得一样好。利用4D配准网格,我们利用自回归模型将SMPL扩展到动态软组织变形随时间的位形函数。SMPL可以作为一个FBX文件导出,并且我们使用脚本在公共呈现系统中对模型运动,这将使人能逼真地动起来。
SMAL(Skinned Multi-Animal Linear Model)
3D Menagerie: Modeling the 3D Shape and Pose of Animals【Apr 2017】
摘要
在学习逼真的、铰接的、三维人体模型方面,已经做了大量的工作。相比之下,这样的动物模型很少,尽管有很多应用。主要的挑战是动物远不如人类配合。最好的人体模型是从成千上万个特定姿势的人的3D扫描中学习的,这在活体动物身上是不可行的。因此,我们从一组任意姿态的小玩偶的3D扫描中学习我们的模型。我们采用一种新的基于零件的形状模型来计算扫描的初始配准。然后我们将它们的姿势标准化,学习一个统计形状模型,并将配准和模型一起细化。通过这种方法,我们精确地排列了来自不同四足动物家族的扫描图像,它们的形状和姿势都非常不同。通过配准到一个通用模板,我们学习了一个表示动物的形状空间,包括狮子、猫、狗、马、牛和河马。动物的形状可以从模型中取样,摆姿势,动画,并对齐数据。我们通过将其与真实动物(包括未在训练中看到的物种)的图像进行拟合来展示泛化。
目标
我们的目标是建立一个像SMPL这样的统计形状模型,它在低维欧氏子空间中捕捉人体形状的变化,对人体的关节结构建模,并能适合于图像数据。
从少量训练集中学习动物的3D统计形状模型。将这一模型和形状和姿态于2D图像进行配准和细化,从而可以拟合真实动物生成3D模型,甚至对之前没有见过的形状生成模型。
数据集
使用Artec手持三维扫描机来扫描动物玩具模型。从以下的物种收集了41个扫描结果:1 cat, 5 cheetahs, 8 lions, 7 tigers, 2 dogs, 1 fox,1 wolf, 1 hyena, 1 deer, 1 horse, 6 zebras, 4 cows, 3 hippos.
并收集一组手动标注的36关键点。
模型
GLoSS(The Global/Local Stitched Shape model)
是一种三维铰接式模型,其中每个部件的身体形状变形都是局部定义的,并且通过最小化部件接口的缝合成本将部件组装在一起。为了定义网格拓扑,我们使用从Turbosquid网站下载的一只母狮的3D网格,它被分为33个部分,姿势保持中立,使其沿矢状面对称。

-
姿态变形空间
使用LBS(linear blend skinning)动画母狮模板,对局部坐标系中各部分的顶点进行主成分分析(PCA),得到平均位姿变形向量mp,i和基矩阵 B B Bp,i
-
形状变形空间
为身体的每个部位定义了一个合成的形状空间,包含7种变形的形状模板:沿x,y,z方向缩放以及固定一个方向其余两个方向按比例缩放,即为每个部位定义了一个简单的解析变形空间。
GLoSS-based registration
为了更好地将GLoSS适配扫描形状,主要工作是最小化该值:
E ( I I ) E(II) E(II) = E E Em(d,s) + E E Estitch ( I I ) (II) (II) + E E Ecurv ( I I ) (II) (II) + E E Edata ( I I ) (II) (II) + E E Epose(r)
- E E Em(d,s)代表一个模型,表达式如下:

其中 E E Es是合成形状分布的马氏距离的平方, E E Ed是L2范数的平方, E E Esm表示对称部位具有相似形状变形的约束条件,有利于使躯干的部位具有相似的长度。 - E E Estitch ( I I ) (II) (II)是部位之间接口对应点距离的平方和, E E Estitch ( I I ) (II) (II) =
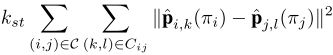
- E E Ecurv ( I I ) (II) (II)是曲率项,倾向于与模板中有类似成对关系的部分, E E Ecurv ( I I ) (II) (II) =

- E E Edata ( I I ) (II) (II)是数据部分,是衡量两个扫描模型间的匹配度。 E E Edata ( I I ) (II) (II) =
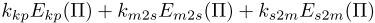
- E E Epose ( I I ) (II) (II)是从动画中学习尾巴的姿势。
过程呈现如下图:
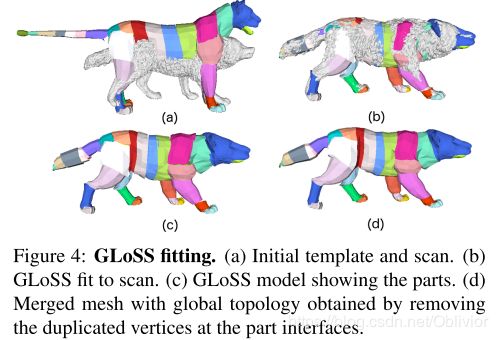
a. 初始化模板和扫描模型;
b. 将GLoSS拟合扫描模型;
c. GLoSS显示各部位(不同颜色);
d. 去除身体各部位连接间的多余顶点,使用全局拓扑变形网格,最终拟合。
ARAP-based refinement
GLoSS模型完成了初始化配准,考虑到这一点,将每个GLoSS网格从其基于部位的拓扑转换为一个不重复接口点的全局拓扑。然后通过减小从 E E Edata ( I I ) (II) (II)定义的能量方程去对齐扫描模型的顶点集合v,以捕获细节。
As-Rigid-As-Possible (ARAP) 正则化为: E E E(v) = E E Edata(v) + E E Earap(v)
这种无模型优化使网格顶点更接近扫描,因此更准确地捕捉动物的形状,如下图:

Skinned Multi-Animal Linear Model
1.Pose normalization 姿势归一化
解决模型非对称问题,执行顶点的平均后,我们镜像网格,以获得配准在中立的姿态,并使用拉普拉斯平滑移除部分旋转对顶点的非线性影响。

2.Shape model 变形模型
中立的姿态下,可以在欧几里得空间中对形状变化的统计量进行建模,作者计算了平均形状和主要成分,以捕获动物形状之间的差异。
3.SMAL 模型
该模型是形状参数 β \beta β,姿态参数 θ \theta θ和变换参数 γ \gamma γ的函数 M ( β , θ , γ ) M(\beta,\theta,\gamma) M(β,θ,γ)
β \beta β是学习好的PCA形状空间的系数; θ \theta θ是 N N N=33个关节的相对旋转运动树; γ \gamma γ是应用于跟关节的全局变换。这一点类似与SMPL模型。
4.Fitting 拟合
将SMAL模型拟合于扫描模型,需要最小化该参数,并使用Chumpy优化:
![]()
5.Co-registration 联合配准
首先执行一个SMAL模型优化,将当前模型与扫描对齐,然后运行一个无模型步骤,通过在下式中添加一个耦合项,将无模型配准耦合到当前SMAL模型,或者对其进行正则化。
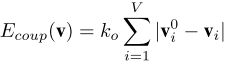
- V为模板中的顶点数量,vi0是拟合扫描的模型顶点i,vi是被优化的耦合网格顶点集合。联合配准过程中使用30维的形状空间,共进行了4次配准和模型构建迭代,形成最终SMAL模型的形状空间。
6.Animal shape space 动物形状空间
经联合配准细化后,最终的主成分如下图所示:

Fitting Animals to Images
主要完成以下工作:
- Keypoint reprojection关键点重投影
- Silhouette reprojection轮廓重投影
- Shape prior形状先验
- Pose priors姿势先验
- Optimization整体优化
最后得到从真实图片恢复的动物三维模型:
结论
人体建模有着很长的历史,而动物建模则处于起步阶段。我们在使动物模型的建造变得实用方面已经迈出了一小步。我们展示了从玩具开始,我们可以学习一个模型,它可以概括为真实动物的图像,也可以概括为训练中没有看到的动物类型。这为从更多的动物和更多的扫描中构建更丰富的模型提供了一个思路。虽然我们已经证明扫描玩具是一个很好的起点,但我们显然希望有一个更丰富的模型。为此,我们认为我们需要结合图像和视频内容。我们的匹配图像提供了一个起点,从学习更丰富的变形来拟合二维图像,这里我们关注的是有限的四足动物。一个关键问题是处理不同数量的部位(如角、象牙、树干)和形状迥异的部件(如大象的耳朵)。超越现有的动物类将涉及创建一个可重用形状部件的词汇表和组合它们的新方法。
SMALR(SMAL with Refine)
Lions and Tigers and Bears:Capturing Non-Rigid, 3D, Articulated Shape from Images【June 2018】
摘要
动物在自然界中广泛存在,分析它们的形状和运动在许多领域和行业中都很重要。然而,由于用于捕捉人体形状的三维扫描方法不适用于野生动物或自然环境,因此很难对三维动物形状进行建模。因此,我们提出了一种仅从图像捕捉动物详细三维形状的方法。动物的铰接性和可变形性使这一问题极具挑战性,特别是在有移动和未经校准的摄像机的无约束环境中。为了使这成为可能,我们使用一个强大的关节动物形状的先验模型,去拟合我们的图像数据。然后,我们以标准的参考姿势对动物形状进行变形,使其在铰接和投影到多个图像时与图像证据相匹配。我们的方法比以前的方法提取了更多的三维形状细节,并且能够用少量的视频帧来建模新物种,包括灭绝动物的形状。此外,投影的三维形状足够精确,便于从多个帧提取真实的纹理映射。
改进
SMAL证明了扫描动物模型玩具是可行的,本篇文章SMALR(SMAL with Refine)仅通过图像和视频内容,使用一个关节动物形状的先验模型,学习更丰富的变形以拟合图像,提取更多的三维纹理细节,并提供少量视频帧重建模型的方法。
步骤

- 图像对齐:输入一套带有标注点和轮廓的同一动物图集,将SMAL模型与图像对齐,以获取每张图像中动物形状和姿态的估计。(28个标注点包括:足部x4,膝部x4,踝x4,肩x2,尾部前后,颈部,下巴,眼睛x2,鼻孔x2,脸颊x2,嘴部x2,耳尖x2)
- 形状恢复:对初始网格进行正则变形优化 ,以更好地匹配轮廓和标注点,再更新每个图像里动物的姿态。
- 纹理恢复:从图像中抽象出动物的纹理,得到一个完整的、纹理分明的三维动物模型。
1. 图像对齐
- 首先收集各个角度动物图像的集合{ Ii },分割动物后的轮廓剪影形成{ Si }, { v ( β , r , t ) v(\beta,r,t) v(β,r,t) } 表示为SMAL模型的网格顶点集合。( β \beta β是学习好的PCA形状空间的系数; r r r是姿态参数,33个关节的相对旋转运动树; t t t=(tx, ty, tz) 是应用于跟关节的全局变换。)
- 其次,设{ Ki }为手工标注的二维标注点的集合,每个标注点都与一组三维模型上的顶点相关联,将其表示为{ VK,j }j=1nK,再将与第j个标注点相关联的顶点数量表示为 n n nH(j)
- 再通过透视投影方法对相机建模,{ c(f(i), rc(i), tc(i) } 分别表示为相机的焦距,三维旋转角和位置平移。设置相机的中心点为图像中心,缩放图像为480像素。
- 使用与动物躯干相对应的二维标注点来估计动物的平移和全局旋转,再将N个SMAL模型的姿态初始化为位姿先验中的平均姿态,使平移值为0(覆盖动物图像)
- 设定相机焦点坐标的fx = fy = 1000,计算沿z轴的平移值(深度),表示为

- 再通过求解下式优化问题,得到平移和全局旋转的估计值:
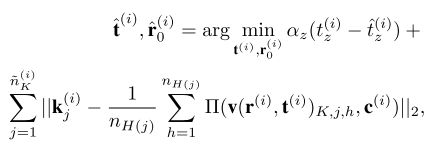
其中, Π Π Π是投影算符, n n nK(i)是第 i i i张图像中标注点的数量。 - 一旦获得每张图像的全局旋转和平移的估计,就能以此估计关节的位姿和形状参数。通过在所有模型参数和图像中的焦距最小化损失,第 i i i张图像的未知模型惩罚项表示为

其中,
(1). Ekp是关键点重投影损失;
(2). Eβ(i)(β)表示将所有帧的形状调整为相同的惩罚项;
(3). Ecam是对fx和fy具有相同值的惩罚项;
(4). Esil,Elim,Epose,Eshape在SMAL的论文中定义过,分别为轮廓惩罚项,关节限制惩罚项,姿态惩罚项和形状惩罚项。 - 当已知动物所属的科时,使用特定科的均值和协方差训练样本。在图像对齐的最后,获得了对所有图像的姿态、平移和形状的估计。
2. 形状恢复
本阶段通过估计小尺度拟合的偏差,从图像中获取更精确的三维形状。对每一种动物,定义了一个顶点位移矢量dv:
![]()
通过这种方法,能够在关节拟合前将变形参数拟合于图像里的动物,为了估计dv,最小化:
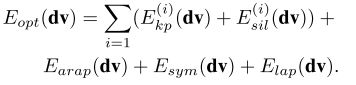
其中,Earap(局部刚性旋转的网格变形(ARAP)的惩罚项),Esym(与动物身体的主轴对称惩罚项)和Elap(拉普拉斯平滑惩罚项)为正则化惩罚项,是约束优化的必要条件。
主要思想是通过移动N个模型的顶点去拟合轮廓剪影图像和标注点坐标。得出dv就能得到动物的形状模型,再执行SMAL位姿预测,以保持模型形状不变。

3. 纹理恢复
为SMAL模型定义了纹理坐标和UV映射。:
- 为每个图像-模型网络定义纹理图像和可见性权重;
- 结合纹理映射,取其加权平均值;
- 利用对称性互换得到完整的纹理图像。

结论
我们利用最近在关节动物建模方面的进展,使从图像中恢复精确形状和纹理的任务变得易于处理。我们已经展示了我们的方法在一系列不同动物身上的应用。在这里,我们着重于恢复内在的动物形状,并假设一般的位置依赖的变形所提供的SMAL。未来的工作应该探索我们是否也能从图像和视频中学习位置相关的变形。此外,这里我们依赖于手动分割的图像和单击的特征点。这两个过程都可以通过深度学习和训练数据实现自动化。我们计划探索使用我们的模型综合生成这样的训练数据。最后,我们计划利用SMALR模型来捕捉视频序列中的三维运动动物,并将形状集合扩展到更广泛的动物形态。
SMALST(SMAL with learned Shape and Texture)
Three-D Safari: Learning to Estimate Zebra Pose, Shape, and Texture from Images “In the Wild”【Oct 2019】
摘要
我们提出了第一种从野外采集的图像中自动捕捉动物的三维姿态、形状和纹理的方法。特别地,我们关注的问题是如何从一组图像中捕捉关于格雷维斑马的3D信息。格雷维斑马是非洲最濒危的物种之一,现在只剩下几千只了。捕捉这些动物的形状和姿势可以为生物学家和自然资源保护主义者提供有关动物健康和行为的信息。濒危物种的训练数据相对于人类姿态、形状和纹理估计的研究来说是有限的,动物处于复杂的、有遮挡的自然场景中,它们是善于伪装的,成群行走,彼此看起来很相似。为了克服这些挑战,我们将最近的SMAL动物模型集成到一个基于网络的端到端训练的回归管道中,综合生成具有姿态、形状和背景变化的图像。超越了目前最先进的人体形状和姿态估计方法,我们的方法在训练中学习斑马的形状空间。利用光损耗从图像中学习形状空间是一种新颖的方法,该方法可用于在有限的三维监督下学习其他场景中的形状。此外,我们将三维姿态和形状预测与纹理合成任务结合起来,从一张图像中获得动物的完整纹理图。我们展示了预测的纹理映射允许对网络特性进行新的每个实例的无监督优化。SMALST (SMAL具有学习过的形状和纹理)超越了以前的工作,即假设手动关键点和/或分割,直接从像素回归到三维动物形状、姿态和纹理。
改进
基于SMALR注释大约500张图像来获得10只动物的精确形状、姿势和纹理,本方法添加了各种变化,生成了数千张合成训练图像,如下图:

这些图像足够逼真,证明可以让本方法学会从图像像素中估计动物体型、姿势和纹理,而无需对附加的手工标记图像进行任何的微调。
主要工作
通过使用包含动物形状、外观和神经网络的完全生成模型,并利用光度损失来训练神经网络,该网络可以从单个图像预测动物的三维姿态、形状和纹理。
创新点:通过共享的特征空间将纹理预测与三维姿态和形状联系起来,以便在预测纹理映射时,网络估计模型参数,实现图像像素和纹理映射元素之间实现最优映射,并预测了图像像素和纹理图之间的流动。
步骤
制作了一个全是斑马的,共有12850张RGB图像的,计算机生成的数据集。采用SMALR从一套57张斑马图像中生成的10个不同模型,每个模型都为其生成包括在背景、形状、姿势、相机和外观都不同的的随机图像,如上图。
- 降低以下损失:
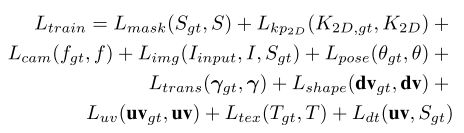
- 其中Lmask表示预测掩模和剪影轮廓之间的L1损失;
- Lkp2D表示2D关键点和3D关键点的投影MSE损失;
- Lcam表示预测焦距和实际焦距之间的MSE损失;
- Limg计算为渲染的斑马图像和剪影轮廓之间的感知距离;
- Lpose表示预测3D模型和姿势参数的MSE损失,计算为测地线距离;
- Ltrans表示预测变换和全局变换的MES损失;
- Lshape表示预测顶点位移和真值顶点位移的MSE损失;
- Luv表示uv流损失,定义为预测的纹理uv流和真值纹理uv流之间的L1损失;
- Ltex表示预测的纹理图和真值纹理图之间的L1损失;
- Ldt表示纹理损失,其鼓励uv流从前景区域提取颜色。
除此之外,通过学习到的特征空间和光度损失对每个实例执行无监督优化。给定一个输入图像,执行回归网络和实例优化,对特征空间变量进行优化,最小化以下损失:
![]()
- 其中Lphoto是光度损失,计算为预测图像和输入图像之间的感知距离。
实验结果

结论
我们是第一个从野外的单一图像研究自动生成动物的三维姿态,形状和外观的团队。传统上,计算机视觉研究的重点一直是人体,而处理野生动物带来了新的技术挑战。我们通过创建一个结合真实外观与合成的姿态、形状和背景的数字数据集来克服缺乏训练数据的问题。我们通过训练端到端网络,直接从图像中还原三维姿态、形状、摄像机、全局平移和纹理,从而消除了关键点检测或分段的需要。我们已经证明,预测纹理映射有助于恢复更精确的姿态和形状。此外,我们还展示了,由于预测的纹理映射,我们可以通过利用光度损失对编码器特性执行基于每个实例网络的优化来改进结果。在这项工作中,我们关注的是斑马,但我们的方法是通用的,可以应用于其他动物或人类。