Python网络爬虫中图片下载简单实现
代码功能:
从LOL官网下载所有的英雄皮肤壁纸,保存到电脑硬盘上
实现流程:
//大话较长哈,不想听话痨请直接看代码清单哈哈
首先,要向批量下载所有的英雄的皮肤壁纸,你就要找到这些图片链接地址的规律,来有效顺利的依次的requests.get()所有的图片,就这一步我在控制台花费的不少时间,走的弯路不说了,直接说成功的路线吧。
用浏览器(我这里用的Edge)进入LOL官网,点进LOL英雄介绍页面,点开进入英雄的页面,比如我进去了阿卡丽的页面,随机选择一个皮肤图片,鼠标右键点击检查元素,查看该图片的URL,
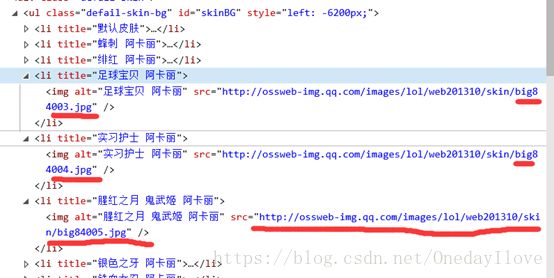
你会发现,这些皮肤壁纸的url前面都是一样的,就.jpg前面的三个数字不一样,但你会发现这些数字是按顺序排列的,第一个皮肤(即默认皮肤)URL的后三位是000,接着是001、002、003等等,一直到00(皮肤总数-1)(因为开头从000开始),发现这个规律很不错,我们只用把前面不变的url和变化的00X.jpg组合起来就可以得到每个皮肤的地址来下载了。但还有个问题,这只是阿卡丽的皮肤地址,其他英雄的皮肤地址是怎么样的?继续打开另一个英雄的页面,查看他的皮肤URL,
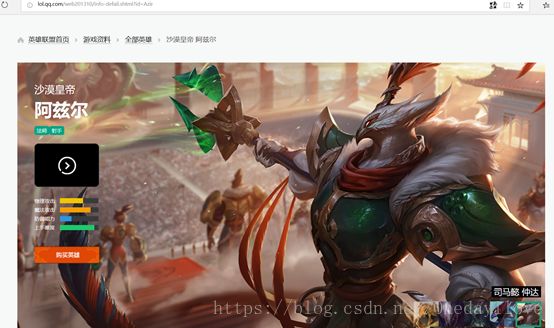

你会发现,哇塞,阿兹尔皮肤url中/big数字.jpg前面的url和阿卡丽的皮肤的一模一样,而且.jpg前面的三位数字和作用和规律和阿卡丽的一样,代表皮肤的顺序,阿兹尔和阿卡丽唯一的不同就是/bigXXOOO.jpg中的XX部分(你也发现了XX也可以是XXX三个数字),只要再找到每个英雄对应的这XX部分的数字,就能找到所有英雄的皮肤地址了。
因此,我们返回LOL全部英雄的界面,按你万年没按过的F12,进入控制台,再刷新那个网页,找到champion.js文件,打开看看

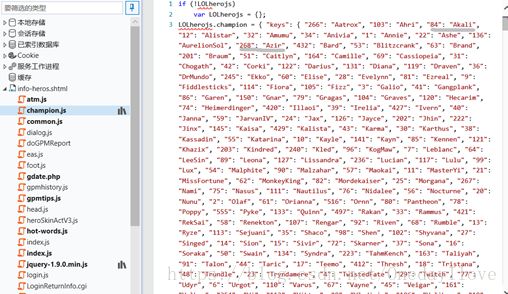
发现了吗,Champion对象中键 key 的值保存的对象(当前对JS了解不深,如果表达失误见谅)就是相应数字对应的相应英雄,比较下阿卡丽和阿兹尔对应的键,和前面我们找到的/bigXXOOO.jpg中的XX一样,把这个“key”:{······}复制到新建的getHeroimg.py里作为一个字典,当然Champion对象里有很多丰富的信息,先不用管。
接下来就很简单了,看代码注释就行
代码清单:
import requests #Python上网必备
import os #用来创建文件夹保存皮肤图片
import time #导入时间库,用来计算程序用时
#所有英雄对应的编号
herolist = {"266": "Aatrox","103": "Ahri","84": "Akali","12": "Alistar","32": "Amumu","34": "Anivia","1": "Annie","22": "Ashe","136": "AurelionSol","268": "Azir","432": "Bard", "53": "Blitzcrank", "63": "Brand", "201": "Braum", "51": "Caitlyn", "164": "Camille", "69": "Cassiopeia", "31": "Chogath", "42": "Corki", "122": "Darius", "131": "Diana", "119": "Draven", "36": "DrMundo", "245": "Ekko", "60": "Elise", "28": "Evelynn", "81": "Ezreal", "9": "Fiddlesticks", "114": "Fiora", "105": "Fizz", "3": "Galio", "41": "Gangplank", "86": "Garen", "150": "Gnar", "79": "Gragas", "104": "Graves", "120": "Hecarim", "74": "Heimerdinger", "420": "Illaoi", "39": "Irelia", "427": "Ivern", "40": "Janna", "59": "JarvanIV", "24": "Jax", "126": "Jayce", "202": "Jhin", "222": "Jinx", "145": "Kaisa", "429": "Kalista", "43": "Karma", "30": "Karthus", "38": "Kassadin", "55": "Katarina", "10": "Kayle", "141": "Kayn", "85": "Kennen", "121": "Khazix", "203": "Kindred", "240": "Kled", "96": "KogMaw", "7": "Leblanc", "64": "LeeSin", "89": "Leona", "127": "Lissandra", "236": "Lucian", "117": "Lulu", "99": "Lux", "54": "Malphite", "90": "Malzahar", "57": "Maokai", "11": "MasterYi", "21": "MissFortune", "62": "MonkeyKing", "82": "Mordekaiser", "25": "Morgana", "267": "Nami", "75": "Nasus", "111": "Nautilus", "76": "Nidalee", "56": "Nocturne", "20": "Nunu", "2": "Olaf", "61": "Orianna", "516": "Ornn", "80": "Pantheon", "78": "Poppy", "555": "Pyke", "133": "Quinn", "497": "Rakan", "33": "Rammus", "421": "RekSai", "58": "Renekton", "107": "Rengar", "92": "Riven", "68": "Rumble", "13": "Ryze", "113": "Sejuani", "35": "Shaco", "98": "Shen", "102": "Shyvana", "27": "Singed", "14": "Sion", "15": "Sivir", "72": "Skarner", "37": "Sona", "16": "Soraka", "50": "Swain", "134": "Syndra", "223": "TahmKench", "163": "Taliyah", "91": "Talon", "44": "Taric", "17": "Teemo", "412": "Thresh", "18": "Tristana", "48": "Trundle", "23": "Tryndamere", "4": "TwistedFate", "29": "Twitch", "77": "Udyr", "6": "Urgot", "110": "Varus", "67": "Vayne", "45": "Veigar", "161": "Velkoz", "254": "Vi", "112": "Viktor", "8": "Vladimir", "106": "Volibear", "19": "Warwick", "498": "Xayah", "101": "Xerath", "5": "XinZhao", "157": "Yasuo", "83": "Yorick", "154": "Zac", "238": "Zed", "115": "Ziggs", "26": "Zilean", "142": "Zoe", "143": "Zyra"
}
#这个是每个皮肤url前面不变的部分
url_1 = "http://ossweb-img.qq.com/images/lol/web201310/skin/big"
#考虑到皮肤数量最多的安妮也只有12个,因此可以把url上限调为011来减少访问无效的地址
num = ['000','001','002','003','004','005','006','007','008','009','010','011',]
#把访问和下载英雄图片代码做成一个函数
def getImg():
for key,value in herolist.items(): #遍历每个英雄对应的数字编号和名字(英文名字)
#在f盘新建一个以英雄名字命名的文件夹,用来保存下载的英雄皮肤壁纸
os.mkdir("f:\\"+value)
os.chdir("f:\\"+value) #定位到新建的文件夹中
url_2 = url_1 + key
for n in num: #遍历该英雄的每个皮肤url
url = url_2 + n + ".jpg" #生成完整的皮肤url
img = requests.get(url) #获得Response对象
#如果img的状态码不等于200,表示刚刚生成的url不存在,也就是已有的皮肤图片下载完了,跳过该循环
if img.status_code == 200:
#用 n 做文件名保存下载的图片,img.content用来返回二进制数据
open(n+".jpg",'wb').write(img.content)
print(value + " 所有的皮肤壁纸获取成功···")
start = time.time()
getImg() #运行爬虫程序
end = time.time()
spendtime = end - start
print("运行成功!\n")
print("用时 " + str(spendtime) + "秒")