video_analyst项目搭建与siamfc++小结
文章目录
- video_analyst简介
- 开源video_analyst
- Repository structure(in progress)
- 帮助文档整理
- DEVELOP.md
- 注册机制 registry mechanism
- 配置树 configuration tree
- 添加自己的模块 add you own module
- template_module
- Process to Go
- Misc
- Pros of this design
- 结构 structure
- Trainer
- Tester
- 其他 misc
- Logging
- 关于调试的建议 tips for debugging
- PIPELIEN_API.md
- Minimal Runnable Pipeline
- 学习资料
video_analyst简介
开源video_analyst
为方便学术交流,旷视研究院开源了以深度学习任务为核心的基于PyTorch的训练工程VideoAnalyst,它目前以算法SiamFC++为项目实例,通过分析当前深度学习模型训练测试工程的结构特点,开发出一套注重任务扩展性的深度学习训练/测评框架,其系统由5个模块构成:
- dataloader,提供训数据;
- model,构建模型结构、初始化和损失函数等,构成模型的整体架构;
- optimizer,专注于模型(model)的训练细节,比如学习率调节 (lr schedule)、优化器参数 (optim method)、梯度调整 (grad modifier) 等;
- engine trainer,控制一个epoch的训练流程;tester-控制一个测试集的测试流程;
- pipeline,根据一个任务使用model完成的任务处理流程,可以独立运行测试,或提供对外API接口。
video_analyst采用config与代码模块一一对应的方式,配置即系统构建,整个工程在一套大的config配置对的规划下进行开发,以此来解决(1)如何在以上5个模块中实现不同的任务(2)如何对一个训练或测试流程进行合理的模块化配置。对于模块的具体实现,采用注册器的形式对其所属的任务进行注册。
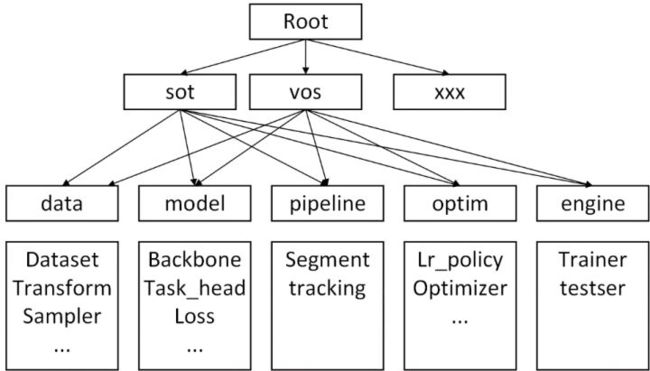
video_analyst工程按照配置即系统构建的设计原则,在配置文件中按照代码模块的实际分布进行相关参数的配置,使其集中化、逻辑化。训练和测试仅需要运行python3 main/train.py or test.py -cfg configfile.yaml即可。具体的模块构建流程如下图:

Repository structure(in progress)
Tip: 把这个项目的架构认真读完很有用。
├── experiments # 实验配置,网络的结构配置、数据集配置等等,整个项目都会根据配置文件运行,配置即系统构建, in yaml format
├── main
│ ├── train.py # 训练入口,已经集成化了,当模块构建完成后,可直接运行, python3 main/train.py or test.py -cfg configfile.yaml
│ └── test.py # test entry point
├── video_analyst
│ ├── data # modules related to data
│ │ ├── dataset # data fetcher of each individual dataset
│ │ ├── sampler # data sampler, including inner-dataset and intra-dataset sampling procedure
│ │ ├── dataloader.py # data loading procedure
│ │ └── transformer # data augmentation
│ ├── engine # procedure controller, including traiing control / hp&model loading
│ │ ├── monitor # monitor for tasks during training, including visualization / logging / benchmarking
│ │ ├── trainer.py # train a epoch
│ │ ├── tester.py # test a model on a benchmark
│ ├── model # model builder
│ │ ├── backbone # backbone network builder
│ │ ├── common_opr # shared operator (e.g. cross-correlation)
│ │ ├── task_model # holistic model builder
│ │ ├── task_head # head network builder
│ │ └── loss # loss builder
│ ├── pipeline # pipeline builder (tracking / vos)
│ │ ├── segmenter # segmenter builder for vos
│ │ ├── tracker # tracker builder for tracking
│ │ └── utils # pipeline utils
│ ├── config # configuration manager
│ ├── evaluation # benchmark
│ ├── optim # optimization-related module (learning rate, gradient clipping, etc.)
│ │ ├── optimizer # optimizer
│ │ ├── scheduler # learning rate scheduler
│ │ └── grad_modifier # gradient-related operation (parameter freezing)
│ └── utils # useful tools
└── README.md
帮助文档整理
DEVELOP.md
注册机制 registry mechanism
这是一个通用设计,已被MMDetection和Detectron2等几个主流深度学习工程采用。
注册机制的主要思想是构建一个字典,其键为模块名称,其值为模块类对象,然后通过检索模块类对象并使用预定义的配置文件实例化它们来构建整个pipeline(例如,pipeline的跟踪器/分割器/训练器等)。
以下是注册机制使用的一个示例:(在xxx_base.py里构建字典,在XXX_impl/YYY.py里实现模块类)

# In XXX_base.py
from videoanalyst.utils import Registry
TRACK_TEMPLATE_MODULES = Registry('TRACK_TEMPLATE_MODULE')
VOS_TEMPLATE_MODULES = Registry('VOS_TEMPLATE_MODULE')
TASK_TEMPLATE_MODULES = dict(
track=TRACK_TEMPLATE_MODULES,
vos=VOS_TEMPLATE_MODULES,
)
# In XXX_impl/YYY.py
@TRACK_TEMPLATE_MODULES.register
@VOS_TEMPLATE_MODULES.register
class TemplateModuleImplementation(TemplateModuleBase):
...
配置树 configuration tree
videoanalyst基于yaml和yacs,以层级的方式定义配置。
- Hyper-parameters。建议开发人员以默认的.yaml配置文件为例,并从它们开始开发。 此外,代码定义及其描述位于每个模块的XXX_impl下==(注册机制里的模块的定义)==。
- PS。为了进行序列化,请在default_hyper_params中不要使用原始的dict对象。 用yacs.config.CfgNode封闭它。
添加自己的模块 add you own module
提供的默认的TEMPLATES位于video_analyst/docs/TEMPLATES下。
template_module
这一模块用于构建自己的module。将TEMPLATES下的TemplateModule、TEMPLATE_MODULES和template_module替换成你自己的模块名。
Process to Go
最基本的,需要overwrite/complete以下部分:
- template_module_impl/template_module_impl.py
- TemplateModuleImplementation.default_hyper_params。这部分定义模块的hyper-parameters(name/type)
- TemplateModuleImplementation.default_hyper_params。定义如何根据给定的配置文件更新hyper-parameters。例如,根据配置文件中给出的score_size和x_size计算未给出的score_offset。
- template_module_base.py。定义模块的基类
- build, builder.py。定义模块constructor的行为。

Misc
- template_module_impl文件夹下的命名规范。默认情况下template_module_impl/init.py会过滤掉类似于"_utils.py"、 "_bak.py"之类的文件名。具体的请参考template_module_impl/init.py。
- Inheritance。由于default_hyper_params,实现类的继承性有些棘手。 给出的例子在template_module_impl / inherited_template_module_impl。
Pros of this design
由于着重于多任务框架的设计和实现,遵守开闭原则 (Open–closed principle),因此video_analyst具有非常好的多任务扩展属性。
举个例子来说,为了增加一个额外的实验ShuffleNetV2。不需要修改追踪文件,只需要添加一些ShuffleNetV2相关的文件。
Untracked files:
(use "git add ..." to include in what will be committed)
experiments/siamfcpp/train/siamfcpp_shufflenetv2x0_5-trn.yaml
experiments/siamfcpp/train/siamfcpp_shufflenetv2x1_0-trn.yaml
tools/train_test-shufflenetv2x0_5.sh
tools/train_test-shufflenetv2x1_0.sh
videoanalyst/model/backbone/backbone_impl/shufflenet_v2.py
结构 structure
Trainer
- Trainer Structure
Trainer
├── Dataloder (pytorch) # make batch of training data
│ └── AdaptorDataset (pytorch) # adaptor class (pytorch index dataset)
│ └── Datapipeline # integrate data sampling, data augmentation, and target making process
│ ├── Sampler # define sampling strategy
│ │ ├── Dataset # dataset interface
│ │ └── Filter # define rules to filter out invalid sample
│ ├── Transformer # data augmentation
│ └── Target # target making
├── Optimizer
│ ├── Optimizer (pytorch) # pytorch optimizer
│ │ ├── lr_scheduler # learning rate scheduling
│ │ └── lr_multiplier # learning rate multiplication ratio
│ ├── Grad_modifier # grad clip, dynamic freezing, etc.
│ └── TaskModel # model, subclass of pytorch module (torch.nn.Module)
│ ├── Backbone # feature extractor
│ ├── Neck # mid-level feature map operation (e.g. cross-correlation)
│ └── Head # task head (bbox regressor, mask decoder, etc.)│
└── Monitor # monitoring (e.g. pbar.set_description, tensorboard, etc.)
- Trainer Building Process(Functional Representation)
model = builder.build(model_cfg) # model_cfg.loss_cfg, model.loss
optimzier = builder.build(optim_cfg, model)
dataloader = builder.build(data_cfg)
trainer = builder.build(trainer_cfg, optimzier, dataloader)
Tester
- Tester Structure。Pipeline对象可以独立地运行。
Tester
├── Benchmark implementation # depend on concrete benchmarks (e.g. VOT / GOT-10k / LaSOT / etc.)
└── Pipeline # manipulate underlying nn model and perform pre/post-processing
└── TaskModel # underlying nereural network
├── Backbone # feature extractor
├── Neck # mid-level feature map operation (e.g. cross-correlation)
└── Head # task head (bbox regressor, mask decoder, etc.)
其他 misc
Logging
目前使用的loggers如下
- global:建立在每一个地方
- data:建立在videoanalyst/data/builder.py;日志文件默认存储在snapshots/EXP_NAME/logs/data.log
关于调试的建议 tips for debugging
为了进行调试/单元测试,请在源代码的开头插入以下代码。请注意,它要求要调试的文件不应具有相对的导入代码。 (因此,我们始终鼓励绝对导入)。你可以在该项目的许多path.py文件中查这些此代码。
import os.path as osp
import sys # isort:skip
module_name = "videoanalyst"
p = __file__
while osp.basename(p) != module_name:
p = osp.dirname(p)
ROOT_PATH = osp.dirname(p)
ROOT_CFG = osp.join(ROOT_PATH, 'config.yaml')
sys.path.insert(0, ROOT_PATH) # isort:skip
PIPELIEN_API.md
Minimal Runnable Pipeline
假定:①将exp_cfg_path中的.yaml文件和videoanalyst放在同一级别上;②您有一个索引为0的GPU,则以下代码段将实例化并配置一个可立即用于你自己的应用程序的pipeline对象。 它支持以下API:void init(im, state),state update(im)
import cv2
import torch
from videoanalyst.config.config import cfg as root_cfg
from videoanalyst.config.config import specify_task
from videoanalyst.model import builder as model_builder
from videoanalyst.pipeline import builder as pipeline_builder
root_cfg.merge_from_file(exp_cfg_path)
# resolve config
task, task_cfg = specify_task(root_cfg)
task_cfg.freeze()
exp_cfg_path = osp.realpath(parsed_args.config)
# from IPython import embed;embed()
root_cfg.merge_from_file(exp_cfg_path)
logger.info("Load experiment configuration at: %s" % exp_cfg_path)
# build model
model = model_builder.build_model(task, task_cfg.model)
# build pipeline
pipeline = pipeline_builder.build('track', task_cfg.pipeline, model)
pipeline.set_device(torch.device("cuda:0"))
# register your template
im_template = cv2.imread("test file")
state_template = ...
pipeline.init(im_template)
# perform tracking based on your template
im_current = cv2.imread("test file")
state_current = pipeline.update(im_template)
学习资料
- 漫谈视频目标跟踪与分割
- video_analys源码仓库