自然语言处理NLP【分词篇】
NLP简介和三种分词模型
NLP逐渐成为人工智能一大热点研究方向,目前国外对英文分词的研究比较深入,而中文分词发展较缓。它需要联系上下文、作者背景、内容背景等进行调整。
处理这些高度模糊句子所采用消歧的方法,通常运用到语料库以及隐马尔可夫模型(Hidden Markov Model,HMM)、支持向量机(Support Vector Machine,SVM)和条件随机场(Conditional Random Field, CRF)三种为主,也常用于句法分析、命名实体识别、词性标注等,且后两者(SVM、CRF)明显优于隐马尔可夫模型。
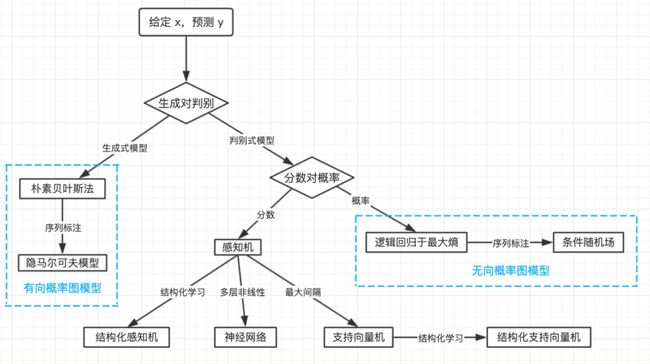
其中隐马尔可夫模型(HMM)和条件随机场(CRF)的模型主干相同,其能够应用的领域往往是重叠的,但在命名实体、句法分析等领域CRF更胜一筹。当然不是必须学习HMM才能读懂CRF,但通常来说如果做自然语言处理,这两个模型大家都应该有所了解。
中文分词的概念
中文分词就是输入一个汉语句子,输出一串由“BEMS”组成的序列串,以“E”、“S”结尾进行切词,进而得到句子划分。其中B(begin)代表该字是词语的起始字,M(middle)代表词语中间字,E(end)结束字,S(single)单字成词。
例如:
小普是星海湾最受欢迎的小马
得到BEMS组成的序列为
BESBMESBMESBE
因为句尾只能是E或S,所以得到的切词方式为
BE/S/BME/S/BME/S/BE
进而得到中文句子切词为
小普/是/星海湾/最/受欢迎/的/小马
我们的目的是想要获得每个字的位置,就需要通过了解每个字的状态和它之前的字推出。这就是一个典型的隐马尔可夫模型问题。
什么是隐马尔可夫(HMM)模型
现实生活中有这样一类随机现象,在已知现在情况的条件下,未来时刻的情况只与现在有关,而与遥远的过去并无直接关系。
比如天气预测,如果我们知道“晴天,多云,雨天”之间的转换概率,那么如果今天是晴天,我们便可以推断明天的天气情况,同理后天的天气可以由明天的天气进行推断。

假设我们没办法知道真实的天气情况,仅有今明后三天的植物状态数据。由于植物状态与天气有关,我们可以通过隐马尔可夫模型(Hidden Markov Model)利用植物数据推测真正的天气情况。
即通过观察某种信息来间接地推出该信息背后隐藏的信息。同理,中文分词就是观察中文句子间接地推出每个字在词语中的位置。
运用HMM模型导出的Viterbi算法
1、 五元组:
观测序列-O:小普是星海湾最受欢迎的小马。
初始状态概率向量-π:句子的第一个字属于{B,E,M,S}这四种状态的概率。
状态转移概率矩阵-A:如果前一个字位置是B,那么后一个字位置为BEMS的概率各是多少(如图1,B后面是E的概率为e^(-0.590),此次已取对数方便计算)。
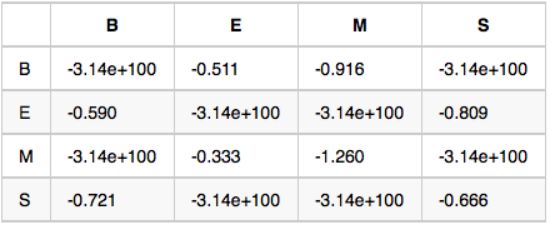
观测概率矩阵-B:在状态B的条件下,如图2观察值为“耀”的概率,取对数后是-10.460。

2、 两种假设
假设一(有限历史性):W_i只由W_(i-1)决定
假设二(独立输出):第i时刻的接收信号w_i只由发送信号![]() r_i决定
r_i决定
3、 viterbi算法
通过五元组加上两个假设导出解决中文分词问题的Viterbi算法,而viterbi算法是一种解码问题:参数(O,π,A,B)已知的情况下,求解状态值序列S。它是一个多步骤、多选择模型的最优化问题,每步选择都保存了所有前序步骤到当前步骤的最小总代价以及下一步的选择。
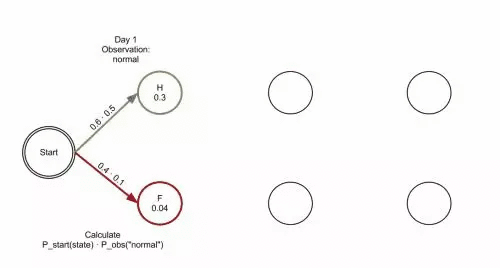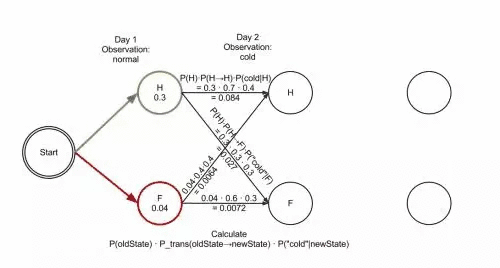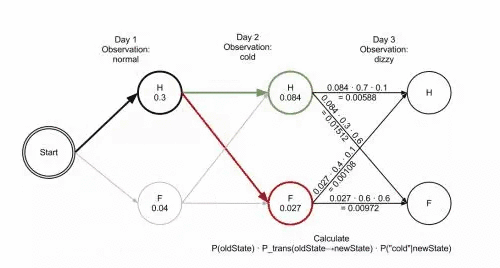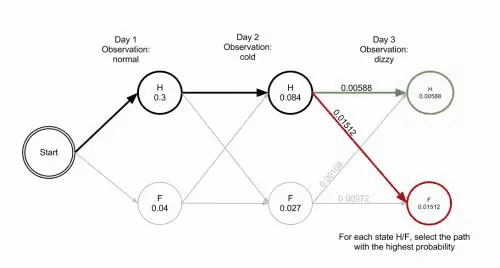
简单介绍完隐马尔可夫模型后会在此基础上写中文分词(二)提出CRF的理解和两者的比较。简单概括就是:
隐马尔可夫模型(HMM)是在拟合联合概率p(x,y)分布的参数,而条件随机场(CRF)是直接在拟合后验概率p(y|x)的参数。
参考:
https://blog.csdn.net/u014365862/article/details/54891582
https://www.cnblogs.com/mantch/p/12292084.html
作者:陈光泽,就读于华中科技大学。