Scrapy之10行代码爬下电影天堂全站

欢迎关注天善智能,我们是专注于商业智能BI,人工智能AI,大数据分析与挖掘领域的垂直社区,学习,问答、求职一站式搞定!
对商业智能BI、大数据分析挖掘、机器学习,python,R等数据领域感兴趣的同学加微信:tstoutiao,邀请你进入数据爱好者交流群,数据爱好者们都在这儿。
作者: 张小鸡 Python爱好者社区专栏作者
知乎ID:https://www.zhihu.com/people/mr.ji
个人公众号:鸡仔说
前言
scrapy的强大相信大家已早有耳闻,之前用的时候只是感觉它爬取效率高,内部的异步封装很友好。殊不知我看到的知识冰山一角,它还有很多提高开发效率的功能,今天就以一个实例带大家窥探一二
工具环境
语言:python3.6
编辑器:Pycharm
数据库:MongoDB
框架:scrapy1.5.1
温馨提示:
阅读此文可能需要对scrapy框架有基本的了解,对xpath解析有一个基本的了解
爬取思路
爬取站点:dytt8.net/
这样的站点我一眼望过去就想给站长打Q币,为什么啊?这站点简直是为爬虫而生啊?你看,一点花里胡哨的东西都没有,我们小眼一瞅便知,和我们不相关的就只是游戏部分的资源。我们需要如果要进入爬取更多的页面就只需要点击导航页

当我点开这些导航页,我都要惊喜的哭了,你们谁也别拦我,我要给站长打钱,对爬虫简直太友好了,我们其实只需要跟踪带有index页面的链接,然后深入下去爬取内页即可
当我们到达内页,再看下哪里可以深入,这里其实也很简单,翻到最底下发现,只需要继续跟踪下一页链接即可
show me the code
1. 新建项目文件
scrapy startproject www_dytt8_net 得到一个如下结构的文件目录 ?

2. 创建crawl模板样式的爬虫demo
先命令行进入到spiders目录下
cd www_dytt8_net/www_dytt8_net/spiders
然后创建爬虫模板
scrapy genspider -t crawl dytt8 www.dytt8.net
得到如下文件 ?
3. 配置跟踪页面规则
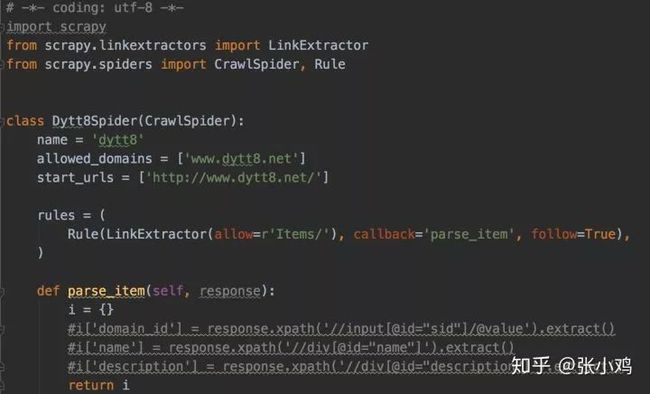
爬取思路中,我们已经介绍过了,只需要跟踪首页链接中,带有index的页面,进入到内页后,我们继续跟踪下一页即可遍历所有电影页面。简单了,我们配置一下rule,让爬爬开启追踪模式,黑喂狗→
Rule(LinkExtractor(deny=r'.*game.*', allow='.*/index\.html'))
这里的LinkExtractor的作用可以提取一些链接,通过对象提供的参数,方便我们进行追踪和过滤不需要的链接。如这里的deny表示我们不需要其中包含game字段的链接,而allow表示我们允许index的链接
其实内部还支持很多别的提取规则,小伙伴们可以去官方文档看看,全是爬虫的大杀器:
https://scrapy.readthedocs.io/en/latest/topics/link-extractors.html#module-scrapy.linkextractors.lxmlhtml
4. 导航页点击进去的下一页
Rule(LinkExtractor(restrict_xpaths=u'//a[text()="下一页"]'))
简直良心啊有木有?这要是平时,我们得写好几个代码段呐。这里就真的只需要一行,restrict_xpaths 支持xpath语法,提取标签页为下一页的所有a标签内的链接,这里其实我过滤掉了callback参数,表示这个页面跟踪后,交给谁处理下一步,还有一个参数是follow 可以设为True 或 False 表示接下来要不要对这个页面进行进一步的追踪
5. 提取文章页链接,交由解析函数处理
Rule(LinkExtractor(allow=r'.*/\d+/\d+\.html', deny=r".*game.*"), callback='parse_item', follow=True)
我们将页面中有这种形式的页面提取出来{数字}/{数字}.html 的页面提取出来其实就是详情文章页面,注意这里需要过滤掉是游戏的页面,所有增加拒绝跟踪链接的规则deny=r".*game.*",最后将提取到的链接回调给parse_item处理
6. 提取所需关键信息
在items.py内定义我们需要提取的字段
import scrapyclass WwwDytt8NetItem(scrapy.Item): # define the fields for your item here like: # name = scrapy.Field() title = scrapy.Field() publish_time = scrapy.Field() images = scrapy.Field() download_links = scrapy.Field() contents = scrapy.Field()
接着将spiders/dytt8.py中的回调函数中的提取规则写出来
def parse_item(self, response): item = WwwDytt8NetItem() item['title'] = response.xpath('//div[@class="title_all"]/h1/font/text()').extract_first() item['publish_time'] = response.xpath('//div[@class="co_content8"]/ul/text()').extract_first().strip().replace('发布时间:', '') imgs_xpath = response.xpath('//div[@id="Zoom"]//img') item['images'] = [i.xpath('./@src').extract_first() for i in imgs_xpath if i.xpath('./@src')] item['download_links'] = re.compile('').findall(response.text) item['contents'] = [i.strip().replace('\n', '').replace('\r', '') for i in response.xpath('string(//div[@id="Zoom"])').extract()] yield item
7. 启动脚本看下运行状态
scrapy crawl dytt8
感受爬爬的力量吧?

8. 数据库存储 这里介绍一下scrapy-mongodb,也是超级好用,省去了自己链接和配置的麻烦,没有下载的童鞋,可以pip安装下
我们只需要settings.py中,配置如下中间键
ITEM_PIPELINES = { # 'www_dytt8_net.pipelines.WwwDytt8NetPipeline': 300, 'scrapy_mongodb.MongoDBPipeline': 300,}
然后写入mongodb配置即可
MONGODB_URI = 'mongodb://localhost:27017'MONGODB_DATABASE = 'spider_world'MONGODB_COLLECTION = 'dytt8'
来,咱们状态全开run一波,最后得到2W+部片子???
至此,我们便可以看到满满的电影种子链接,以后有什么想看的电影,自己直接在库里找找看,是不是很棒啊真正核心代码其实不到十行!!!以后不是很复杂的爬虫,还是用丝瓜皮吧,人生苦短,请用丝瓜皮
github地址:http://link.zhihu.com/?target=https%3A//github.com/hacksman/spider_world
个人网站:http://link.zhihu.com/?target=http%3A//www.zxiaoji.com/
作者其他好文推荐:
当女票发来一套送命题,程序员应该怎么做?
Python的爱好者社区历史文章大合集:
Python的爱好者社区历史文章列表
关注后在公众号内回复“ 课程 ”即可获取:
小编的转行入职数据科学(数据分析挖掘/机器学习方向)【最新免费】
小编的Python的入门免费视频课程!
小编的Python的快速上手matplotlib可视化库!
崔老师爬虫实战案例免费学习视频。
陈老师数据分析报告扩展制作免费学习视频。
玩转大数据分析!Spark2.X + Python精华实战课程免费学习视频。
