Rancher平台部署Percona XtraDB Cluster数据库集群
各种MySQL数据库集群高可用方案

https://bobcares.com/blog/mysql-high-availability-top-7-solutions/
1. Redundant devices to combat hardware failures
2. Shared storage with SAN and NAS
3. Storage replication using DRBD
4. MySQL replication to avoid single point failures
5. MySQL clustering
6. Galera multi-master MySQL replication
7. Percona XtraDB Cluster
PXC技术概要

Percona XtraDB Cluster与MySQL Replication区别在于:
分布式系统的CAP理论:
C:一致性,所有节点的数据一致;
A:可用性,一个或多个节点失效,不影响服务请求;
P:分区容忍性,节点间的连接失效,仍然可以处理请求;
任何一个分布式系统,需要满足这三个中的两个。
MySQLReplication:可用性和分区容忍性;
Percona XtraDBCluster:一致性和可用性。
因此MySQL Replication并不保证数据的一致性,而Percona XtraDB Cluster提供数据一致性。
Percona XtraDBCluster是MySQL高可用性和可扩展性的解决方案。Percona XtraDBCluster提供的特性有:
- 同步复制,事务要么在所有节点提交或不提交。
- 多主复制,可以在任意节点进行写操作。
- 在从服务器上并行应用事件,真正意义上的并行复制。
- 节点自动配置。
- 数据一致性,不再是异步复制。
Percona XtraDBCluster完全兼容MySQL和Percona Server,表现在:
- 数据的兼容性
- 应用程序的兼容性:无需更改应用程序
它的集群特点是:
- 集群是有节点组成的,推荐配置至少3个节点,但是也可以运行在2个节点上。
- 每个节点都是普通的mysql/percona服务器,可以将现有的数据库服务器组成集群,反之,也可以将集群拆分成单独的服务器。
- 每个节点都包含完整的数据副本。
优点如下:
- 当执行一个查询时,在本地节点上执行。因为所有数据都在本地,无需远程访问。
- 无需集中管理。可以在任何时间点失去任何节点,但是集群将照常工作。
- 良好的读负载扩展,任意节点都可以查询。
缺点如下:
- 加入新节点,开销大。需要复制完整的数据。
- 不能有效的解决写缩放问题,所有的写操作都将发生在所有节点上。
- 有多少个节点就有多少重复的数据。
PXC的传统物理机三节点部署简要说明
那么这样一个MySQL集群方案,在我们传统的物理机环境的安装部署,是否会很复杂呢?熟悉其组件及工作原理之后,安装倒是不特别复杂。我们以CentOS系列为范例,简要看看其安装配置流程:



PXC在Rancher容器管理平台的部署
Percona作为标准的Catalog项目出现在Rancher Server1.1版本之后,如果你使用的是较低的版本,例如v1.0.1,在数据库分类里将只会见到MariaDB Galera Cluster项目。当然你可以在低版本中添加自定义的Catalog,例如
https://github.com/alanpeng/MyRancherCatalog.git

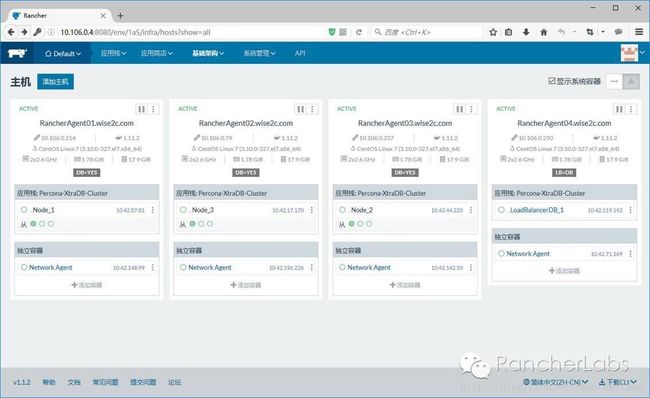
部署好的Percona XtraDB Cluster集群宿主机结构如图所示(除了拉起Percona-XtraDB-Cluster集群之外,还在其前端加入了一个Rancher内置的LoadBalancer):
将此Catalog项目打开,我们可以看见其docker-compose.yml及rancher-compose.yml文件的内容如下:


Stack/Service结构示意图:

这里的12个容器角色如下:Node节点3个,运行confd服务;ClusterCheck节点3个分别监听集群节点健康状态;Server节点3个,是数据库主服务应用;3个Data作为数据卷共享的提供,是sidekick容器类型。
所有容器列表如下:

数据库连接验证测试:
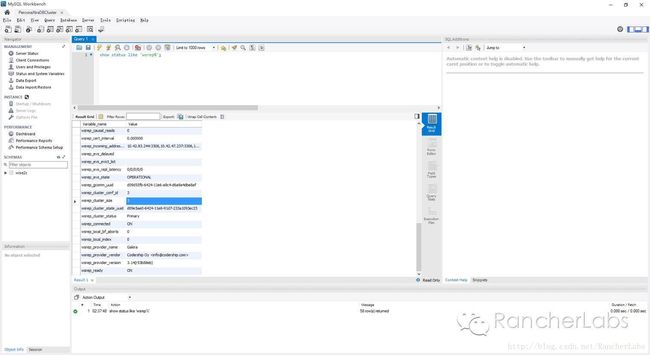
从前端负载均衡宿主机的IP访问数据库,执行语句show status like ‘wsrep%’;返回的结果表明数据库集群节点数为3,同步复制状态正常。
在Rancher平台如何灵活运用Confd+Metadata进行配置管理
以上PXC集群运行于容器之上并被Rancher平台管理,其中的具体实现细节较多,因为我们需要这样的数据库集群满足弹性伸缩的要求,举例来说也就是可以动态的将集群节点数由3个增加至更多,那么必然每个节点的配置文件需要动态的进行更新,要做到这一点,我们可以结合confd与Rancher的metadata元数据服务来实现,当然这里涉及到数据库集群专有的技术,giddyup专有工具的结合也是必不可少的选择。
1. 首先给出整个项目的代码文件供参考
分3个模块:
https://github.com/Flowman/docker-pxc
https://github.com/Flowman/docker-pxc-confd
https://github.com/Flowman/docker-pxc-clustercheck
2. 数据库集群配置工具giddyup
https://github.com/cloudnautique/giddyup
在数据库集群服务的启动脚本
https://github.com/Flowman/docker-pxc/blob/master/start_pxc里我们使用了giddyup工具,其中比较重要的命令有以下项:
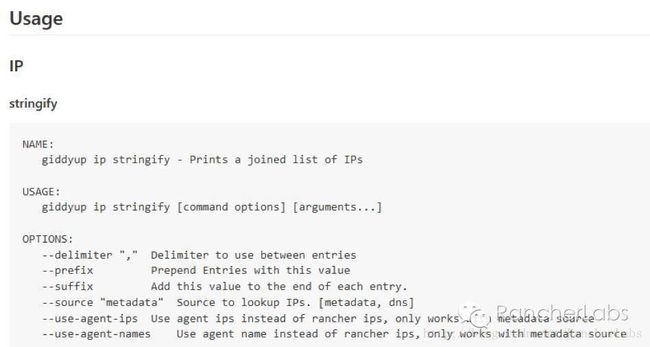
获取集群节点成员IP列表,请参照本篇前面章节中my.cnf文件中提及的wsrep_cluster_address=gcomm:// …

获取集群运行状态并返回节点规模数
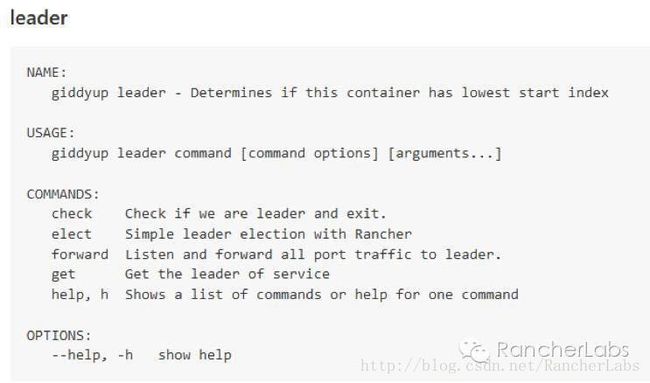
探测当前容器节点是否属于数据库集群的bootstrap角色(leader)
3. 配置管理工具confd
https://github.com/kelseyhightower/confd 它对rancher提供了很好的支持,能够与Rancher的metadata元数据服务紧密结合:


如何与元数据结合?confd有两个重要文件,一个是模板文件,一个是配置文件,其执行过程就是从backends对象例如Rancher的metadata获取数据,然后将其更新至真正被服务调用的配置文件中去:

这里的pxc.cnf.tmpl文件是模板文件,而pxc.toml文件则是配置文件。confd的配置文件是建立一个服务,监控特定的backends对象(例如etcd、rancher元数据等等)的键值以及当值发生变化时执行某些操作。其文件格式是TOML,易于使用,其规则跟人的直觉也相近。我们可以看到容器执行期间,Rancher预先在rancher-compose.yml中定义的metadata元数据通过confd将一些重要参数传递给了数据库集群服务的配置文件my.cnf:

我们知道Rancher的metadata元数据是有版本差异的,那么如何知道在这个PXC数据库集群里它调用的元数据从何而来呢?
看一下Dockerfile的内容我们不难发现
https://github.com/Flowman/docker-pxc-confd/blob/master/Dockerfile

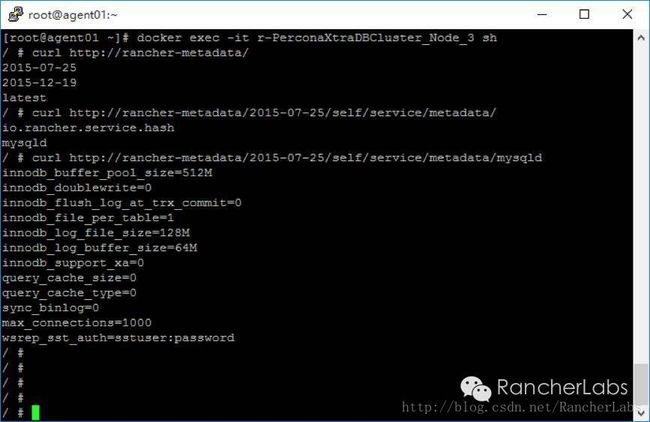
这里从mysql元数据服务项返回的值正是我们在rancher-compose.yml文件中预先定义好了的:
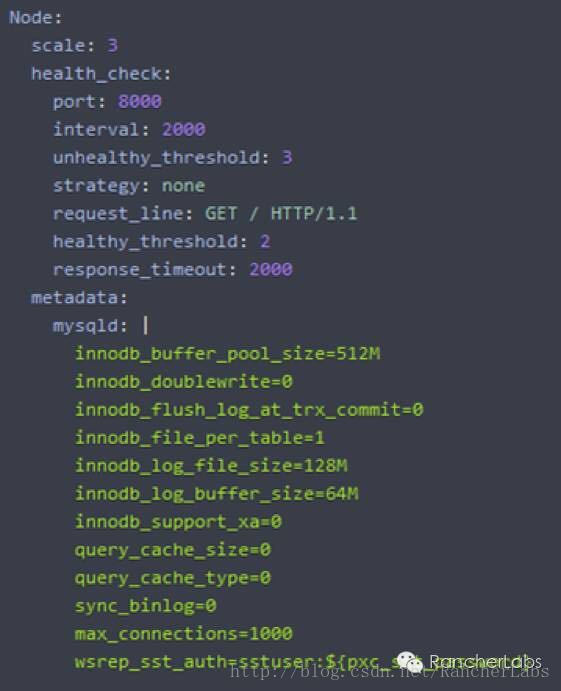
从Percona XtraDB Cluster这个Rancher的Catalog项目,我们可以较为全面的理解confd配置服务是如何与Rancher的元数据服务进行结合的,这样就能实现较为复杂的数据库集群应用完全自动化的实现弹性伸缩功能。
Q & A
Q:如果在k8s环境部署mysql集群,用什么方案比较好?
A:Rancher的k8s里面的模板没有cattle环境的模板多,Cattle的模板是没有办法直接拿到K8s环境里面来用的,k8s的模板是k8s的yaml文件结合rancher-compose文件。Rancher官网blog有一篇是关于如何转换Prometheus的cattle模板成为k8s模板的,有兴趣的话可以参考一下:http://rancher.com/converting-prometheus-template-cattle-kubernetes/
原文来源:Rancher Labs