Elasticsearch(三) Python 使用 elasticsearch 的基本操作
参考文章:https://cuiqingcai.com/6214.html
一. python 安装 elasticsearch标准库
1. pip install elasticsearch
2. 中文分词插件:
elasticsearch默认是英文分词器,所以我们需要安装一个中文分词插件 elasticsearch-analysis-ik (注意和elasticsearch的版本对应),安装之后重新启动 Elasticsearch 自动加载安装好的插件 :
elasticsearch-plugin install https://github.com/medcl/elasticsearch-analysis-ik/releases/download/v6.5.4/elasticsearch-analysis-ik-6.5.4.zip (这里的版本号请替换成你的 Elasticsearch 的版本号。)
二. elasticsearch 相关概念
Elasticsearch 基本的概念,如节点、索引、文档等等

| 1. Node & Cluster | 单个 Elasticsearch 实例称为一个节点(Node); 一组节点构成一个集群(Cluster)。 |
| 2. Index | Elasticsearch 数据管理的顶层单位就叫做 Index(索引); 相当于 MySQL、MongoDB 等里面的数据库的概念; 注意:每个 Index (即数据库)的名字必须是小写。 |
| 3. Document | Index 里面单条的记录称为 Document(文档); Document 使用 JSON 格式表示; 同一个 Index 的Document,不要求有相同的结构(scheme),但最好保持相同,有利于提高搜索效率。 |
| 4. Type | Document 可以分组,这种分组就叫做 Type; 它是虚拟的逻辑分组,用来过滤 Document,类似 MySQL 中的数据表,MongoDB 中的 Collection; 不同的 Type 应有相似的结构。(根据规划 Elastic 6.x 版只允许每个 Index 包含一个 Type,7.x 版将会移除 Type。) |
| 5.Fields | 即字段,每个 Document 都类似一个 JSON 结构,它包含了许多字段,每个字段都有其对应的值; 可以类比 MySQL 数据表中的字段。 |
二. python 操作 elasticsearch
1. 创建 Index -- es.indices.create(index=' ')
即字段,每个 Document 都类似一个 JSON 结构,它包含了许多字段,每个字段都有其对应的值;
可以类比 MySQL 数据表中的字段。
2. 删除 Index -- es.indices.delete(index='news')
result = es.indices.delete(index='news', ignore=[400, 404])
print(result)3. 插入数据 -- es.create() & es.index()
es.indices.create(index='news', ignore=400)
data = {'title': '美国留给伊拉克的是个烂摊子吗', 'url': 'http://view.news.qq.com/zt2011/usa_iraq/index.htm'}
# 方法一:es.create() 手动指定 id 唯一标识
result = es.create(index='news', doc_type='politics', id=1, body=data)
print(result)
# 方法二:es.index() 自动生成id
es.index(index='news', doc_type='politics', body=data)
4. 更新数据
data = {
'title': '美国留给伊拉克的是个烂摊子吗',
'url': 'http://view.news.qq.com/zt2011/usa_iraq/index.htm',
'date': '2011-12-16'
}
result = es.update(index='news', doc_type='politics', body=data, id=1)
print(result)
# 第二种方法:index -- 数据不存在,增加; 如果已经存在,更新
es.index(index='news', doc_type='politics', body=data, id=1)5. 删除数据
# delete -- 指定对应的id
result = es.delete(index='news', doc_type='politics', id=1)
print(result)6.查询数据 -- 优势:其异常强大的检索功能
新建一个索引并指定需要分词的字段, 更新 mapping 信息
from elasticsearch import Elasticsearch
es = Elasticsearch()
mapping = {
'properties': {
'title': {
'type': 'text',
'analyzer': 'ik_max_word',
'search_analyzer': 'ik_max_word'
}
}
}
es.indices.delete(index='news', ignore=[400, 404])
es.indices.create(index='news', ignore=400)
# 设置mapping 信息:指定字段的类型 type 为 text,分词器 analyzer 和 搜索分词器 search_analyzer 为 ik_max_word,即中文分词插件,默认的英文分词器。
result = es.indices.put_mapping(index='news', doc_type='politics', body=mapping)
print(result)插入几条新的数据
datas = [
{
'title': '美国留给伊拉克的是个烂摊子吗',
'url': 'http://view.news.qq.com/zt2011/usa_iraq/index.htm',
'date': '2011-12-16'
},
{
'title': '公安部:各地校车将享最高路权',
'url': 'http://www.chinanews.com/gn/2011/12-16/3536077.shtml',
'date': '2011-12-16'
},
{
'title': '中韩渔警冲突调查:韩警平均每天扣1艘中国渔船',
'url': 'https://news.qq.com/a/20111216/001044.htm',
'date': '2011-12-17'
},
{
'title': '中国驻洛杉矶领事馆遭亚裔男子枪击 嫌犯已自首',
'url': 'http://news.ifeng.com/world/detail_2011_12/16/11372558_0.shtml',
'date': '2011-12-18'
}
]
for data in datas:
es.index(index='news', doc_type='politics', body=data)查询 -- 根据关键词查询一下相关内容
result = es.search(index='news', doc_type='politics')
print(result) # 返回所有结果检索 -- 全文检索
# 使用 DSL 语句来进行查询: match 指定全文检索,检索字段 title,检索内容 “中国领事馆”
dsl = {
'query': {
'match': {
'title': '中国 领事馆'
}
}
}
es = Elasticsearch()
result = es.search(index='news', doc_type='politics', body=dsl)
print(json.dumps(result, indent=2, ensure_ascii=False))返回的检索结果有两条,第一条的分数为 2.54,第二条的分数为 0.28。这是因为第一条匹配的数据中含有“中国”和“领事馆”两个词,第二条匹配的数据中不包含“领事馆”,但是包含了“中国”这个词,所以也被检索出来了,但是分数比较低。
检索结果会按照检索关键词的相关性进行排序,这就是一个基本的搜索引擎雏形。
====== 拓展 -- 高级查询 ======


# ElasticSearch Search apis
1. query: 条件查询 -->
match: 分词查询,评分机制打分;
term: 不分词查询;
Bool: 真值查询,通常和must/should/mustnot一起组合;
range: 指定字段在某个特定范围,然后查询
match_phrase: 查询指定段落?;
2. size: 输出的数据条数
3. sort: 指定字段排序显示
4. _source: 指定输出的字段
5. from: 开始的偏移量
6. to": 结束位置
7. aggs: 聚合复杂查询
8. scrapt_fields: 脚本运算查询?
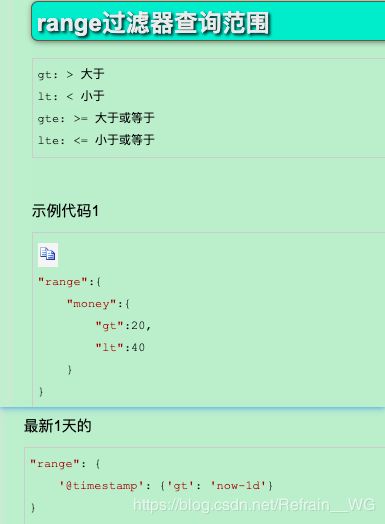


.....
参考文章:https://cuiqingcai.com/6214.html
相关拓展:https://cuiqingcai.com/6255.html
https://elasticsearch-py.readthedocs.io/en/master/
------------- END --------------