(Java)XMLDecoder反序列化漏洞
基本概念
XMLDecoder用于将XMLEncoder创建的xml文档内容反序列化为一个Java对象,其位于java.beans包下。
影响版本
XMLDecoder在JDK 1.4~JDK 11中都存在反序列化漏洞安全风险。
Demo
import com.sun.beans.decoder.DocumentHandler;
import org.xml.sax.helpers.DefaultHandler;
import javax.xml.parsers.SAXParser;
import javax.xml.parsers.SAXParserFactory;
import java.io.BufferedInputStream;
import java.io.File;
import java.io.FileInputStream;
import java.beans.XMLDecoder;
public class test {
public static void XMLDecode_Deserialize(String path) throws Exception {
File file = new File(path);
FileInputStream fis = new FileInputStream(file);
BufferedInputStream bis = new BufferedInputStream(fis);
XMLDecoder xd = new XMLDecoder(bis);
xd.readObject();
xd.close();
}
public static void main(String[] args){
//XMLDecode Deserialize Test
String path = "poc.xml";
try {
XMLDecode_Deserialize(path);
// File f = new File(path);
// SAXParserFactory sf = SAXParserFactory.newInstance();
// SAXParser sp = sf.newSAXParser();
//
// DefaultHandler dh = new DefaultHandler();
// DocumentHandler dh = new DocumentHandler();
// sp.parse(f, dh);
} catch (Exception e) {
e.printStackTrace();
}
}
}
Payload:
poc.xml,可以看到java标签的class属性指定XMLDecoder类,对象标签指定ProcessBuilder类、void标签指定方法为start,即可调用ProcessBuilder.start()来执行其中的命令。
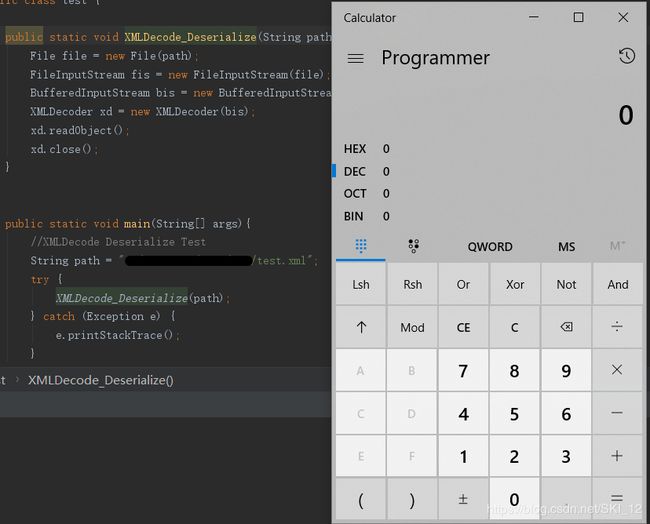
运行后,会弹出计算器:
调试分析
在IDEA下设置断点跟踪调试。
在readObject()处设置断点,可看到XMLDecoder对象xd的input属性包含了输入XML文档的路径:

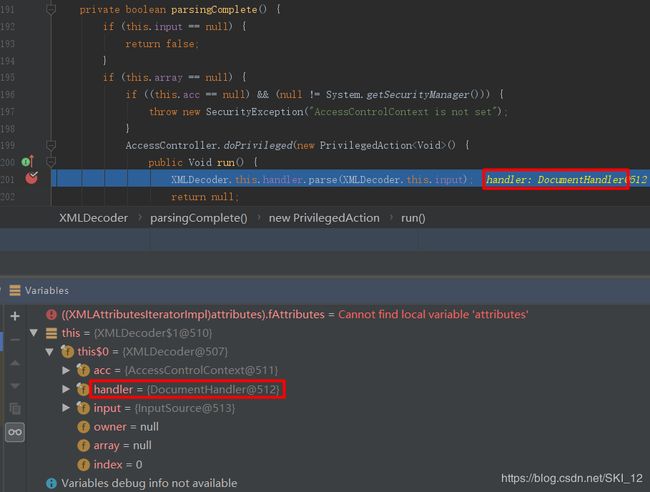
继续往里调试,调用到XMLDecoder.parsingComplete()时,发现里面调用了XMLDecoder.this.handler.parse(),其中this.handler即为DocumentHandler,换句话说,就是调用了DocumentHandler.parser()来解析输入的XML文档内容:
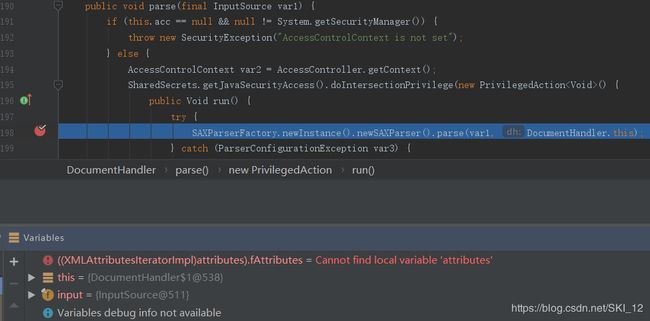
跟踪进去,可以看到DocumentHandler.parser()中调用了SAXParserFactory.newInstance().newSAXParser().parse()来解析XML内容:
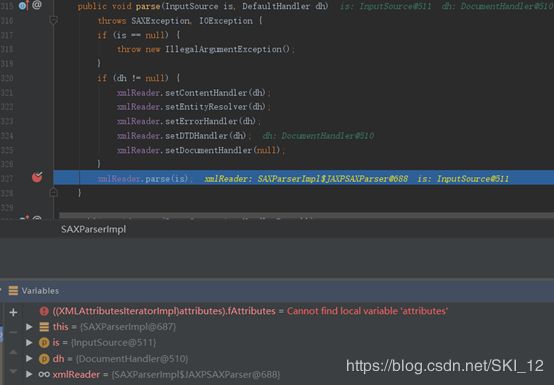
接着设置xmlReader的相关handler,如处理XML内容、实体、错误、文档类型定义、文件等句柄,最后调用xmlReader.parse()解析XML文件内容:
继续调试,在XML11Configuration.parse()中发现调用determineDocVersion():
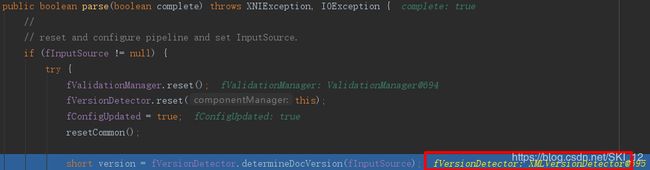
跟踪进去发现,determineDocVersion()主要获取XML实体扫描器然后扫描解析来获取XML文档的版本信息:

返回版本信息后,继续往下在XML11Configuration.parse()中调用startDocumentParsing()函数,主要是重置扫描器的版本配置并开始文件扫描准备,其中开始文件扫描准备是调用startEntity()函数(跟踪进去可以看到是通知扫描器开始实体扫描,其中文档实体的伪名称为“[xml]”、DTD的伪名称为“[dtd]”、参数实体名称以“%”开头;接着函数内部会调用startDocument()函数开始准备文件扫描):
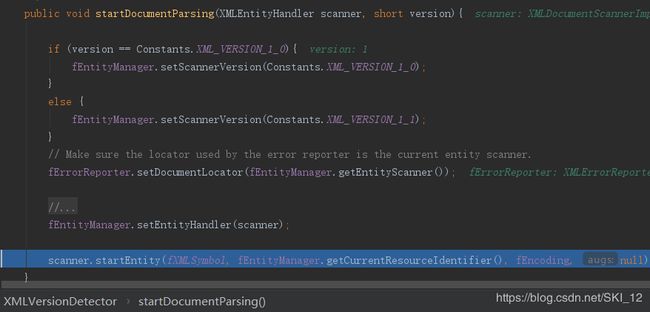
可以看到最后调用到的startDocument()函数会清空当前对象和句柄为文件扫描的开始做准备:

返回到XML11Configuration.parse()中继续往下调试,调用scanDocument()开始文件扫描:

进入scanDocument(),可以看到设置实体句柄后,主要是执行do while循环体,其中的包含START_DOCUMENT、START_ELEMENT、CHARACTERS、SPACE、ENTITY_REFERENCE、PROCESSING_INSTRUCTION、COMMENT、DTD、CDATA、NOTATION_DECLARATION、ENTITY_DECLARATION、NAMESPACE、ATTRIBUTE、END_ELEMENT等的扫描识别:
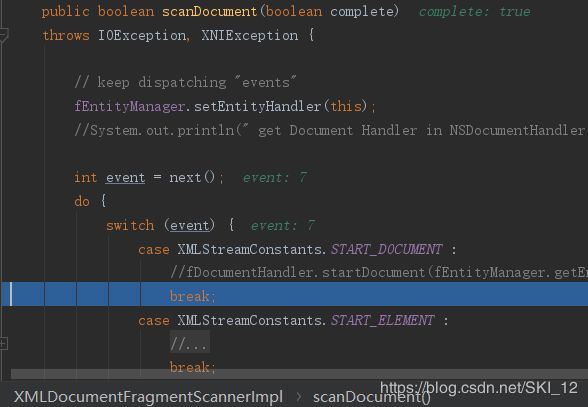
中间XML节点解析的过程不用过多分析,调试至END_ELEMENT时,可以看到其中提取出“calc”参数值:
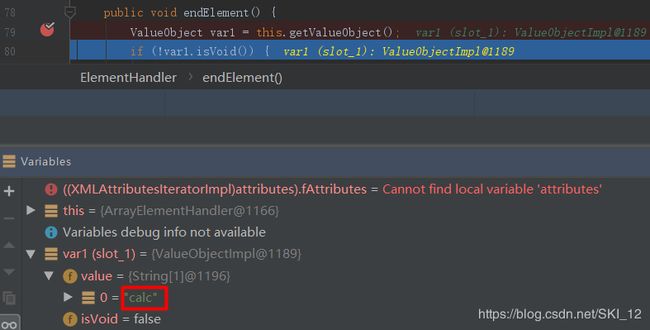
跟踪进去后面的getValueObject()函数,可以看到变量var3和var4,分别为获取到ProcessBuilder类名和start方法名,在调用Expression():

继续跟踪到里面,最后会调用MethodUtil.invoke()方法实现反射执行任意类方法:

再次F7直接执行了代码弹出计算器:
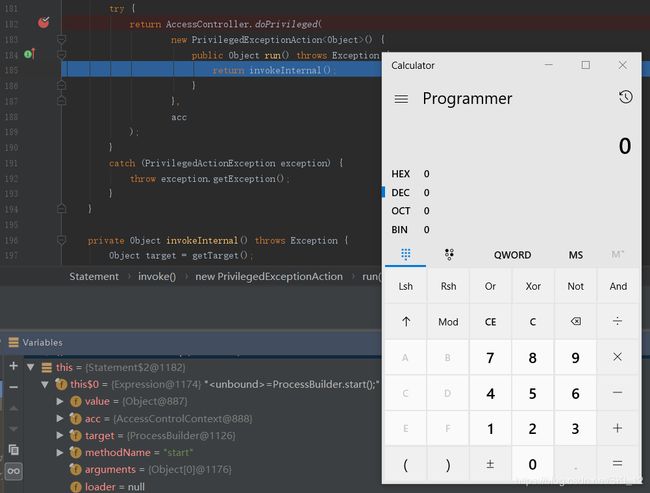
整体地看一下,整个调用过程大致如下:
XMLDecoder.readObject() -> XMLDecoder.parsingCompelete() -> DocumentHandler.parse() -> SAXParserFactory.newInstance().newSAXParser().parse() -> xmlReader.parse()
可以发现,XMLDecoder类解析XML是调用DocumentHandler类实现的,而DocumentHandler类是基于SAXParser类对XML的解析上的。
那么可以去分析一下,到底哪个类才是真正的漏洞类。测试一下,可以看出DocumentHandler类才是XMLDecoder反序列化漏洞的根源类:

检测方法
全局搜索XMLDecoder关键字,排查是否调用readObject()函数且参数是否可控。
防御方法
若可以尽量不使用XMLDecoder反序列化XML内容;若使用则尽量确保参数不可由外界输入,尽量以白名单的方式限定XML文档名且结合严格的过滤机制。