蚂蚁金服 Service Mesh 大规模落地系列 - 控制面篇

本文为《蚂蚁金服 Service Mesh 大规模落地系列》第七篇 - 控制面篇,该系列将会从核心、RPC、消息、无线网关、控制面、安全、运维、测试等模块对 Service Mesh 双十一大规模落地实践进行详细解析。文末包含往期系列文章。
引言
Service Mesh 是蚂蚁金服下一代架构的核心,本次主题主要分享在蚂蚁金服当前的体量下,控制面平稳支撑大规模 Sidecar 的落地实践。聚焦控制面核心组件 Pilot 和 Citadel,分享蚂蚁金服双十一控制面如何管理并服务好全站 Sidecar。
本次分享主要分为两大部分,分别是:
Pilot 落地实践;
Citadel 安全加固;
Pilot 落地实践
在开始分享落地实践之前,我们先来看看 Istio 的架构图:

理想很丰满,现实很骨感。由于性能等方面的综合考虑,我们在落地过程中,将控制面的组件精简为 Pilot 和 Citadel 两个组件了,不使用因性能问题争议不断的 Mixer,不引入 Galley 来避免多一跳的开销。
在架构图中,控制面组件 Pilot 是与 Sidecar 交互最重要的组件,负责配置转化和下发,直面 Sidecar 规模化带来的挑战。这也是双十一大促中,控制面最大的挑战。
规模化的问题在生产实践中,是一个组件走向生产可用级的必经之路。接下来将会分别从稳定性、性能优化、监控这三个方面分别展开。
稳定性增强
我们先梳理下 Pilot 提供的服务能力,从功能实现上来看,Pilot 是一个 Controller + gRPC Server 的服务,通过 List/Watch 各类 K8s 资源,进行整合计算生成 XDS 协议的下发内容,并提供 gRPC 接口服务。本次分享我们先把关注点放在 gRPC 接口服务这个环节,如何保证接口服务支撑大规模 Sidecar 实例,是规模化的一道难题。
负载均衡
要具备规模化能力,横向扩展能力是基础。Pilot 的访问方式我们采用常用的 DNSRR 方案,Sidecar 随机访问 Pilot 实例。由于是长连接访问,所以在扩容时,原有的连接没有重连,会造成负载不均。为解决这个问题,我们给 Pilot 增加了连接限流、熔断、定期重置连接功能,并配合 Sidecar 散列重连逻辑,避免产生连接风暴。
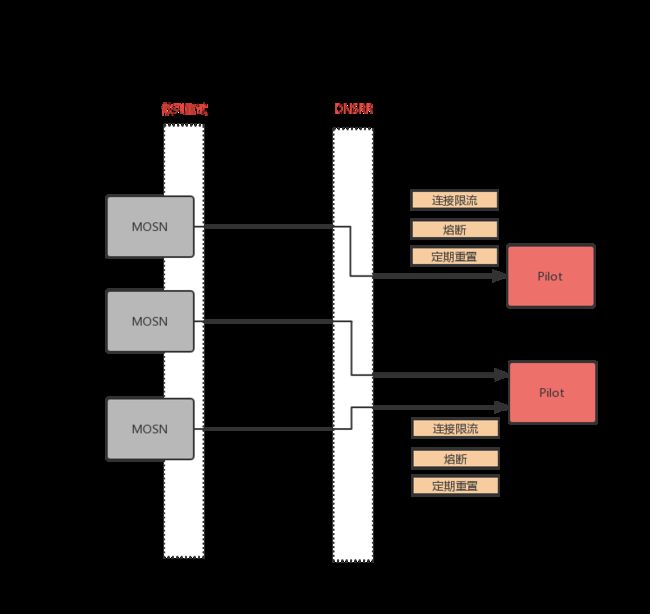
连接限流
为了降低大量 MOSN 同时连接同一个 Pilot 实例的风险,在 gRPC 首次连接时,Pilot 增加基于令牌桶方案的流控能力,控制新连接的处理响应,并将等待超时的连接主动断连,等待 Sidecar 下一次重连。
熔断
基于使用场景的压测数据,限制单实例 Pilot 同时可服务的 Sidecar 数量上限,超过熔断值的新连接会被Pilot 主动拒绝。
定期重置
为了实现负载均衡,对于已经存在的旧连接,应该怎么处理呢?我们选择了 Pilot 主动断开连接,不过断开连接的周期怎么定是个技术活。要考虑错开大促峰值,退避扩缩容窗口之类,这个具体值就不列出来了,大家按各自的业务场景来决定就好了。
Sidecar 散列重连
最后还有一点是 Client 端的配合,我们会控制 Sidecar 重连 Pilot 时,采用退避式重试逻辑,避免对 DNS 和 Pilot 造成负载压力。
性能优化
规模化的另一道难题是怎么保证服务的性能。在 Pilot 的场景,我们最关注的当然是配置下发的时效性了。性能优化离不开细节,其中部分优化是通用的,也有部分优化是面向业务场景定制的,接下来会分享下我们优化的一些细节点。
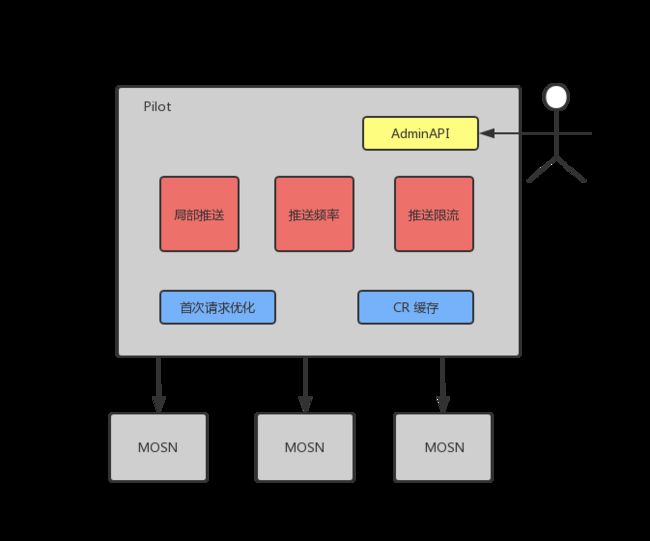
首次请求优化
社区方案里 Pilot 是通过 Pod.Status 来获取 Pod 的 IP 信息,在小集群的测试中,这个时间基本秒级内可以完成。然而在大集群生产环境中,我们发现 Status 的更新事件时间较慢,甚至出现超过 10s 以上的情况,而且延迟时间不稳定,会增加 Pilot 首次下发的时延。我们通过与基础设施 K8s 打通,由 PaaS 侧将 Pod 分配到的 IP 直接标记到Pod.Annotation 上,从而实现在第一次获取 Pod 事件时,就可以获取到 IP,将该环节的时延减少到0。
按需获取 & Custom Resource 缓存
这是一个面向 DBMesh 业务场景的定制性优化,是基于按需获取的逻辑来实现的。其目的在于解决 DBMesh CR 数量过多,过大导致的性能问题,同时避免 Pilot 由于 List/Watch CR 资源导致 OOM 问题,Pilot 采用按需缓存和过期失效的策略来优化内存占用。
局部推送
社区方案中当 Pilot List/Watch 的资源发生变更时,会触发全部 Sidecar 的配置推送,这种方案在生产环境大规模集群下,性能开销是巨大的。举个具体例子,如果单个集群有 10W 以上的 Pod 数量,任何一个 Pod 的变更事件都会触发全部 Sidecar 的下发,这样的性能开销是不可接受的。
优化的思路也比较简单,如果能够控制下发范围,那就可以将配置下发限制在需要感知变更的 Sidecar 范围里。为此,我们定义了 ScopeConfig CRD 用于描述各类资源信息与哪些 Pod 相关,这样 Pilot 就可以预先计算出配置变更的影响范围,然后只针对受影响的 Sidecar 推送配置。
其他优化
强管控能力是大促基本配备,我们给 Pilot Admin API 补充了一些额外能力,支持动态变更推送频率、推送限流、日志级别等功能。
监控能力
安全生产的基本要求是要具备快速定位和及时止血能力,那么对于 Pilot 来说,我们需要关注的核心功能是配置下发能力,该能力有两个核心监控指标:
下发时效性
针对下发的时效性,我们在社区的基础上补充完善了部分下发性能指标,如下发的配置大小分布,下发时延等。
配置准确性
而对于配置准确性验证是相对比较复杂的,因为配置的准确性需要依赖 Sidecar 和 Pilot 的配置双方进行检验,因此我们在控制面里引入了 Inspector 组件,定位于配置巡检,版本扫描等运维相关功能模块。
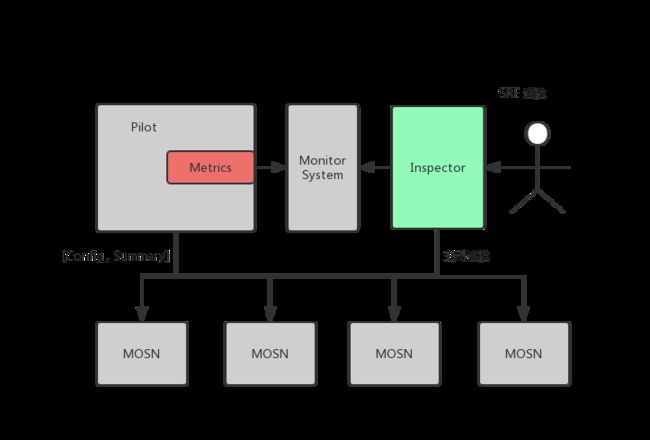
配置巡检的流程如下:
Pilot 下发配置时,将配置的摘要信息与配置内容同步下发;
MOSN 接收配置时,缓存新配置的摘要信息,并通过 Admin API 暴露查询接口;
Inspector 基于控制面的 CR 和 Pod 等信息,计算出对应 MOSN 的配置摘要信息,然后请求 MOSN 接口,对比配置摘要信息是否一致;
由于 Sidecar 的数量较大,Inspector 在巡检时,支持基于不同的巡检策略执行。大体可以分为以下两类:
周期性自动巡检,一般使用抽样巡检;
SRE 主动触发检查机制;
Citadel 安全方案
证书方案
Sidecar 基于社区 SDS 方案 (Secret Discovery Service),支持证书动态发现和热更新能力。同时蚂蚁金服是一家金融科技公司,对安全有更高的要求,不使用 Citadel 的证书自签发能力,而是通过对接内部 KMS 系统获取证书。同时提供证书缓存和证书推送更新能力。
我们先来看看架构图,请看图:
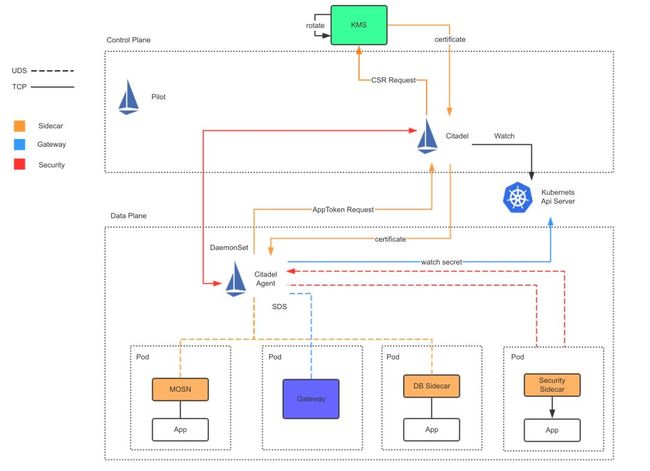
对整体架构有个大致理解后,我们分解下 Sidecar 获取证书的流程,一图胜千言,再上图:
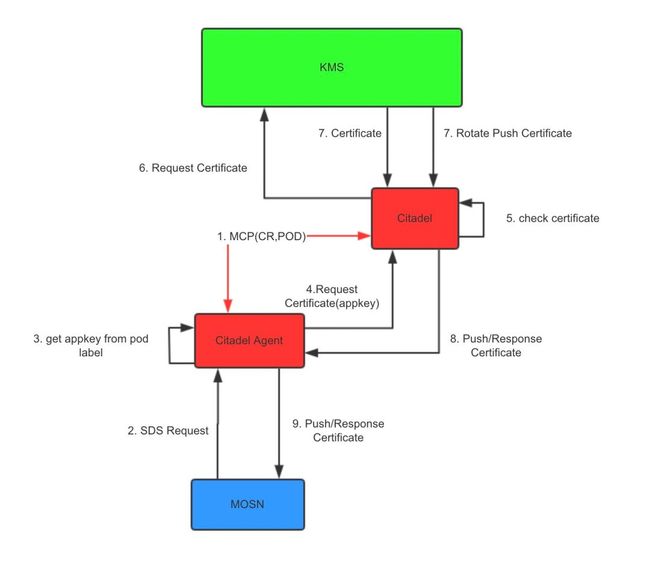
补充说明下图中的每一步环节:
Citadel 与 Citadel Agent (nodeagent) 组件通过 MCP 协议(Mesh Configuration Protocol) 同步 Pod 和 CR 信息,避免 Citadel Agent 直接请求 API Server 导致 API Server 负载过高;
MOSN 通过 Unix Domain Socket 方式向 Citadel Agent 发起 SDS 请求;
Citadel Agent 会进行防篡改校验,并提取 appkey;
Citadel Agent 携带 appkey 请求 Citadel 签发证书;
Citadel 检查证书是否已缓存,如无证书,则向 KMS 申请签发证书;
KMS 会将签发的证书响应回 Citadel,另外 KMS 也支持证书过期轮换通知;
Citadel 收到证书后,会将证书层层传递,最终到达MOSN ;
国密通信
国密通信是基于 TLS 通信实现的,采用更复杂的加密套件来实现安全通信。该功能核心设计是由 Policy 和 Certificate 两部分组成:
Pilot 负责 Policy 的下发;
Citadel 负责 Certificate 下发 (基于 SDS 证书方案);
在落地过程中,仅依靠社区的 PERMISSIVE TLS MODE 还不能满足蚂蚁金服可灰度、可监控、可应急的三板斧要求。所以在社区方案的基础上,引入 Pod 粒度的 Sidecar 范围选择能力(也是基于 ScopeConfig ),方案基本如下图所示:
 流程如下:
流程如下:
Pilot List/Watch ScopeConfig CRD 和 Policy CRD ,基于 Pod Label 选择 Pod 粒度范围实例;
Provider 端 MOSN 收到 Pilot 下发的国密配置后,通过 SDS 方案获取证书,成功获取证书后,会将服务状态推送至 SOFARegistry;
SOFARegistry 通知 Consumer 端 MOSN 特定 Provider 端已开启国密通信状态,重新发起建连请求;
MCP 优化
Citadel Agent 通过 Citadel 去同步 POD 及 CRD 等信息,虽然避免了 Node 粒度部署的 Citadel Agent 对 API Server 的压力。但是使用 MCP 协议同步数据时,我们遇到了以下两个挑战:
大集群部署时,POD 数量在 10W 以上时,全量通信的话,每次需同步的信息在 100M 以上,性能开销巨大,网络带宽开销也不可忽视;
Pod 和 CR 信息变更频繁,高频的全量推送直接制约了可拓展性,同时效率极低;
为了解决以上两个问题,就需要对 MCP 实现进行改造。改造的目标很明确,那就是减少同步信息量,降低推送频率。为此,我们强化了社区 MCP 的实现,补充了这些功能:
为 MCP 协议支持增量信息同步模式,性能大幅优于社区原生方案全量 MCP 同步方式;
Citadel Agent 是 Node 粒度组件,基于最小信息可见集的想法,Citadel 在同步信息给 Citadel Agent 时,通过 Host IP ,Pod 及 CR 上的 Label 筛选出最小集,仅推送每个 Citadel Agent 自身服务范围的信息;
更进一步,基于 Pod 和 CR 的变更事件可以预先知道需要推送给哪些 Citadel Agent 实例,只对感知变更的Citadel Agent 触发推送事件,即支持局部推送能力;
未来思考
本次大促的控制面的重心在于解决规模化问题,后续控制面将会在服务发现、精细化路由、Policy As Code 等领域深入探索。我们将与社区深度合作,控制面将支持通过 MCP 对接多种注册中心(SOFARegistry(已开源), Nacos等)进行服务发现信息同步,解决大规模服务注册发现问题,支持增量推送大量 endpoint。同时控制面还能通过增强配置下发能力,为应用启动提速,将在 Serverless 极速启动场景获取技术红利。控制面还将结合 Policy As Code,从而更具想象空间,具备极简建站,默认安全等能力。
到此,本次分享的内容就结束了。Istio 生产级实践机会难得,并且任重道远。最后,欢迎有志之士加入我们,一起打造世界级规模的 Service Mesh。
MOSN:
https://github.com/sofastack/sofa-mosn
SOFARegistry:
https://github.com/sofastack/sofa-registry
作者简介
本文作者:彭泽文(花名:封尘),蚂蚁金服 Mesh 控制面主站负责人,主要 Focus 领域:Service Mesh(MOSN、Istio)。
蚂蚁金服 Service Mesh 大规模落地系列文章
蚂蚁金服 Service Mesh 大规模落地系列 - Operator 篇
蚂蚁金服 Service Mesh 大规模落地系列 - 网关篇
蚂蚁金服 Service Mesh 大规模落地系列 - RPC 篇
蚂蚁金服 Service Mesh 大规模落地系列 - 运维篇
蚂蚁金服 Service Mesh 大规模落地系列 - 消息篇
蚂蚁金服 Service Mesh 大规模落地系列 - 核心篇
Service Mesh 落地负责人亲述:蚂蚁金服双十一四大考题
本文归档在 sofastack.tech。

???? 圣诞快乐~奖励支持 SOFAStack 的你~
* 点下右下角“在看”
* 到公众号对话框发送“圣诞快乐”,试试手气~
* 本期互动奖品“蚂蚁 U 型枕(以及消除 bug 的神秘力量)”