汇编
索引
[###MOV]
[###指令后面加S]
[###条件执行和标志位][###指令后面加条件]
[@str@strb@strh@ldr@ldrb@ldrh]
[@LSL@LSR @ASR@ROR]
[@前索引@后索引@自动索引]
[@str@ldr]
[@栈 @fd @fa @ed @ea]
[@批量数据存储]
[@原子操作 @swp]
[@状态寄存器传送指令 @mrs]
[@协处理器指令]
[@MRC][@MCR]
[@汇编伪指令和伪操作]
[@.arm][@.thumb][@.section][@.text][@.data][@.bss][@.align][@.org][@.local][@.global][@.end][@.include]
[@.byte][@.short][@.long /.word ][@.quad][@.float][@.string /.asciz/.ascii ]
[@.equ][@.macro]
指令分为六类:
数据处理指令:对数据进行逻辑、数学等运算与处理
跳转指令:实现程序的跳转
Load/Store指令:CPU与内存之间进行数据的存取
状态寄存器传送指令:对状态寄存器进行读写操作
协处理器指令:对协处理器进行操作
异常中断产生指令:产生异常中断
MOV
MOV R0,#0X55
@R0 = 0X55
ps:@立即数
@ #0xff000000
@ mov r0, #0xff00
@ 立即数的本质是包含在指令当中的数
@ 一个立即数是由一个八位二进制数循环右移偶数次得到的
@ mov r0, #0xffffff00
@ 不是立即数 编译器对指令进行了替换
@ 数据处理指令的语法:<操作>{
}{S} Rd, Rn, Operand2
@ <操作码><目标寄存器Rd><第一操作寄存器Rn><第二操作数Operand2>
指令后面加S
数据运算指令后加后缀‘s’时才会对CPSR中的条件位产生影响,默认不会对CPSR中的条件位产生影响
条件执行和标志位&&###指令后面加条件
CMP r3,#0 | | CMP r3,#0
BEQ skip | equal=> | ADDNE r0,r1,r2
ADD r0,r1,r2 | | ......
skip | |
.......
|条件码|助记符后缀 |标志 |含义 |
|-----|---------:|---------------------:|-------------------|--
|0000 | EQ | Z置位 | 相等 |
|0001 | NE | Z清零 | 不等于 |
|0010 | CS | C置位 |无符号大于或等于 |
|0011 | CC | C清零 | 无符号小于 |
|0100 | MI | N置位 | 负数 |
|0101 | PL | N清零 | 正数或零 |
|0110 | VS | V置位 | 溢出 |
|0111 | VC | V清零 | 未溢出 |
|1000 | HI | C置位 | 无符号数大于 |
|1001 | LS | C清零 | 无符号数小于或等于 |
|1010 | GE | N等于 | 带符号数大于或等于 |
|1011 | LT | N不能与于V | 带符号数小于 |
|1100 | GT | Z清零且N等于V | 带符号数大于 |
|1101 | LE | Z置位或N不等于V | 带符号数小于或等于 |
|1110 | AL | 忽略 | 无条件执行 |
(@str@strb@strh@ldr@ldrb@ldrh)
@str
mov r0, #0xaa
mov r1, #0x41000000
str r0, [r1]
@将r0中的数据存储到以r1为起始地址的四个字节的内存单元中
@strb
mov r0, #0xaa
mov r1, #0x41000000
strb r0, [r1]
@将r0中的[7:0]存储到r1指向的内存单元
@strh
mov r0, #0xaa
mov r1, #0x41000000
strh r0, [r1]
@将r0中[15:0]数据存储到以r1为起始地址的2个字节的内存单元中
@位操作
@AND@ORR@EOR@BIC
@LSL
only for reg
/*
*@置位
*/
MOV R1,#0x01
ORR R0,R1,LSL #0x4
@ r0 |= 0x01<<4
/*
*@翻转
*/
MOV R1,#0x01
EOR R0,R1,LSL #0x4
@ r0 ^= 0x01<<4
/*
*@清零
*/
MOV R1,#0x01
BIC R0,R1,LSL #0x4
@ r0 &= ( ~(0x01<<4))
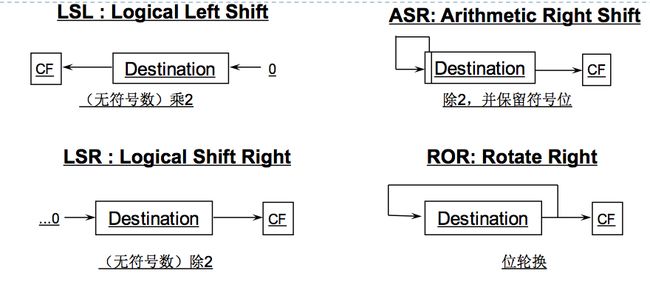
@LSL@LSR @ASR@ROR
@str@ldr
@前索引@后索引@自动索引
- 标号(地址助记符)
val
ldr r0,val @ r0=*(val)
ps:注意区分: ldr r0,=val @ r0=val
- 寄存器间接寻址
ldr r0,=0x40000000
ldr r1,[r0] @ r1 = *r0 =*(0x40000000)
- 基址变址寻址
索引方式
@前索引
mov r0, #0xaa
mov r1, #0x41000000
str r0, [r1, #4]
将r0中的数据存储到r1+4内存中
mov r2, #8
str r0, [r1, r2]
将r0中的数据存储到r1+r2内存中
str r0, [r1, r2, lsl #1]
r1 + (r2 << 1)
@后索引
mov r0, #0xaa
mov r1, #0x41000000
str r0, [r1], #4
将r0存储到r1指向的内存单元中 然后r1 = r1 + 4
@自动索引
mov r0, #0xaa
mov r1, #0x41000000
str r0, [r1, #8]!
将r0存储到1r+8地址中,然后r1=r1+8
在地址后加‘!’使用完地址后地址自增
@批量数据存储
@ mov r1, #1
@ mov r2, #2
@ mov r3, #3
@ mov r4, #4
@ mov r5, #5
@ mov r11,#0x41000000
@ stm r11, {r1-r5}
@ 将r1-r5寄存器中的值存储到以r11为起始地址的内存单元中
@ stm r11!, {r1,r3,r5}
@ 编号小的寄存器对应的存储到低地址
@ 加上'!'后存储完以后地址值自动更新
@增长方式
@ 增长方式
@ mov r1, #1
@ mov r2, #2
@ mov r3, #3
@ mov r4, #4
@ mov r5, #5
@ mov r11,#0x41000000
@ stmda r11!, {r1-r2}
@ stmda r11!, {r1-r5}
@ IA 先使用后增长
@ IB 先增长后使用
@ DA 先使用后递减
@ DB 先递减后使用
@ 将r1-r5存储到r11为起始地址的内存单元 然后将该数据再读取到r6-r10寄存器
@ stmia r11!, {r1-r5}
@ ldmda r11!,{r6-r10}
@栈 @fd @fa @ed @ea
@fd 满减 常用
mov r1, #1
mov r2, #2
mov r3, #3
mov r4, #4
mov r5, #5
mov r11,#0x41000000
stmfd r11!, {r1-r5}
ldmfd r11!, {r6-r10}
@ 栈的种类
@ fd满减 fa满增 ed空减 ea空增
@ 一般使用满减栈
@ 使用什么后缀压栈 就使用什么后缀的出栈指令 这样不会出现错误
@ 初始化栈
@ mov sp, #0x41000000
@原子操作 @swp
swp r0, r1, [r2]
[r2]=>r0 ; r1=>[r2]
将r2地址中的数据加载到r0寄存器,然后将r1中的数据存储到r2指向的内存中
优点:单条指令可以实现内存与处理器之间的数据交换 中间不会被打断
@状态寄存器传送指令 @mrs
mrs r0, cpsr \\读取CPSR中的值到R0寄存器
bic r0, r0, #0x1f
orr r0, r0, #0x10 \\修改r0中的值
msr cpsr, r0 \\将r0中的数据写入CPSR
一般用于模式的切换
对CPSR的操作 读-改-写
当前在哪种模式下使用哪种模式下的寄存器 编程的时候不需要专门指定
@异常中断产生指令 @swi 1
swi 1
@协处理器指令
[@MRC][@MCR]
MRC 将协处理器中寄存器的值传送到处理器寄存器
MCR 将处理器中寄存器的值传送到协处理器寄存器
@汇编伪指令和伪操作(在ppt中有详细介绍)
@伪指令
ldr r0, =0x12345678
将0x12345678放入r0寄存器
先将0x12345678放在内存当中 然后再通过内存访问指令将其读取 进行了指令的替换
ldr r0, =55
根据伪指令书写方式的不同 最终生成的指令可能也不同
ADR R0, lable
ADR伪指令为小范围地址读取伪指令
ADRL R0,lable
ADRL伪指令为中等范围地址读取伪指令
@伪操作
@宏操作
[@.equ][@.macro]
.equ GPF3DAT,0x114001E4
mov r0, #GPF3DAT
宏替换指令
.macro {$label}macroname{$parameter{,$parameter}...}
........code
.endm
函数宏 :宏操作可以 使用一个或多个参数,当宏操作被展开时,这些参数被相应的值替换 。
@数据定义(Data Definition)伪操作
[@.byte][@.short][@.long /.word ][@.quad][@.float][@.string /.asciz/.ascii ]
.byte
单字节定义 .byte 0x12,’a’,23 在当前位置定义 0x12 'a' 23三个byte的数据
.short
定义双字节数据.short 0x1234,65535
.long /.word
定义4字节数据.word 0x12345678
.quad
定义8字节.quad 0x1234567812345678
.float
定义浮点数.float 0f3.2
.string /.asciz/.ascii
定义字符串 .ascii “abcd\0”,
@杂项伪操作
[@.arm][@.thumb][@.section][@.text][@.data][@.bss][@.align][@.org][@.local][@.global][@.end][@.include]
.arm 定义一下代码使用ARM指令集编译
.thumb .thumb 定义一下代码使用Thumb指令集编译
.section .section expr 定义一个段。expr可以使.text .data. .bss
.text {subsection} 将定义符开始的代码编译到代码段
.data {subsection} 将定义符开始的代码编译到数据段,初始化数据段
.bss {subsection} 将变量存放到.bss段,未初始化数据段
.align{alignment}{,fill}{,max} 通过用零或指定的数据进行填充来使当前位置与指定边界对齐
.org offset{,expr}指定从当前地址加上offset开始存放代码,并且从当前地址到当前地址加上offset之间的内存单元,用零或指定的数据进行填充
_start 汇编程序的缺省入口是_ start标号,用户也可以在连接脚本文件中用 ENTRY标志指明其它入口点.
.local定义一个局部的符号
.global/.globl:用来声明一个全局的符号
.end 文件结束
.include “filename”包含指定的头文件, 可以把一个汇编常量定义放在头文件中
@GUN汇编书写标准
代码行中的注释符号: ‘@’ 整行注释符号: ‘#’ 语句分离符号: ‘;’ 直接操作数前缀: ‘#’ 或 ‘$’
标号:标号只能由az,AZ,0~9,“.”,_等(由点、字母、数字、 下划线等组成,除局部标号外,不能以数字开头)字符组成,标号的后面加“:”。
局部标号:局部标号主要在局部范围内使用而且局部标号可以重复出现。它由两部组成开头是一个0-99直接的数字局部标号 后面加“:”
F:指示编译器只向前搜索
B:指示编译器只向后搜索