近几天微软的发布会上讲到了不少认脸解锁的内容,经过探索,其实利用手头的资源我们完全自己也可以完成这样一个过程。
本文讲解了如何使用Python,基于OpenCV与Face++实现人脸解锁的功能。
本文基于Python 2.7.11,Windows 8.1 系统。
主要内容
- Windows 8.1上配置OpenCV
- OpenCV的人脸检测应用
- 使用Face++完成人脸辨识(如果你想自己实现这部分的功能,可以借鉴例如这个项目)
Windows 8.1上配置OpenCV
入门的时候配置环境总是一个非常麻烦的事情,在Windows上配置OpenCV更是如此。
既然写了这个推广的科普教程,总不能让读者卡在环境配置上吧。
下面用到的文件都可以在这里(提取码:b6ec)下载,但是注意,目前OpenCV仅支持Python2.7。
将cv2加入site-packages
将下载下来的cv2.pyd文件放入Python安装的文件夹下的Lib\site-packages目录。
就我的电脑而言,这个目录就是C:\Python27\Lib\site-packages。
记得不要直接使用pip安装,将文件拖过去即可。
安装numpy组件
在命令行下进入到下载下来的文件所在的目录(按住Shift右键有在该目录打开命令行的选项)
键入命令:
pip install numpy-1.11.0rc2-cp27-cp27m-win32.whl
如果你的系统或者Python不适配,可以在这里下载别的轮子。
测试OpenCV安装
在命令行键入命令:
python -c "import cv2"
如果没有出现错误提示,那么cv2就已经安装好了。
OpenCV的人脸检测应用
人脸检测应用,简而言之就是一个在照片里找到人脸,然后用方框框起来的过程(我们的相机经常做这件事情)
那么具体而言就是这样一个过程:
- 获取摄像头的图片
- 在图片中检测到人脸的区域
- 在人脸的区域周围绘制方框
获取摄像头的图片
这里简单的讲解一下OpenCV的基本操作。
以下操作是打开摄像头的基本操作:
#coding=utf8
import cv2
# 一般笔记本的默认摄像头都是0
capInput = cv2.VideoCapture(0)
# 我们可以用这条命令检测摄像头是否可以读取数据
if not capInput.isOpened(): print('Capture failed because of camera')
那么怎么从摄像头读取数据呢?
# 接上段程序
# 现在摄像头已经打开了,我们可以使用这条命令读取图像
# img就是我们读取到的图像,就和我们使用open('pic.jpg', 'rb').read()读取到的数据是一样的
ret, img = capInput.read()
# 你可以使用open的方式存储,也可以使用cv2提供的方式存储
cv2.imwrite('pic.jpg', img)
# 同样,你可以使用open的方式读取,也可以使用cv2提供的方式读取
img = cv2.imread('pic.jpg')
为了方便显示图片,cv2也提供了显示图片的方法:
# 接上段程序
# 定义一个窗口,当然也可以不定义
imgWindowName = 'ImageCaptured'
imgWindow = cv2.namedWindow(imgWindowName, cv2.WINDOW_NORMAL)
# 在窗口中显示图片
cv2.imshow(imgWindowName, img)
当然在完成所有操作以后需要把摄像头和窗口都做一个释放:
# 接上段程序
# 释放摄像头
capInput.release()
# 释放所有窗口
cv2.destroyAllWindows()
在图片中检测到人脸的区域
OpenCV给我们提供了已经训练好的人脸的xml模板,我们只需要载入然后比对即可。
# 接上段程序
# 载入xml模板
faceCascade = cv2.CascadeClassifier('haarcascade_frontalface_default.xml')
# 将图形存储的方式进行转换
gray = cv2.cvtColor(img, cv2.COLOR_BGR2GRAY)
# 使用模板匹配图形
faces = faceCascade.detectMultiScale(gray, 1.3, 5)
print(faces)
在人脸的区域周围绘制方框
在上一个步骤中,faces中的四个量分别为左上角的横坐标、纵坐标、宽度、长度。
所以我们根据这四个量很容易的就可以绘制出方框。
# 接上段程序
# 函数的参数分别为:图像,左上角坐标,右下角坐标,颜色,宽度
cv2.rectangle(img, (x, y), (x + w, y + h), (255, 0, 0), 2)
成果
根据上面讲述的内容,我们现在已经可以完成一个简单的人脸辨认了:
#coding=utf8
import cv2, time
print('Press Esc to exit')
faceCascade = cv2.CascadeClassifier('haarcascade_frontalface_default.xml')
imgWindow = cv2.namedWindow('FaceDetect', cv2.WINDOW_NORMAL)
def detect_face():
capInput = cv2.VideoCapture(0)
# 避免处理时间过长造成画面卡顿
nextCaptureTime = time.time()
faces = []
if not capInput.isOpened(): print('Capture failed because of camera')
while 1:
ret, img = capInput.read()
gray = cv2.cvtColor(img, cv2.COLOR_BGR2GRAY)
if nextCaptureTime < time.time():
nextCaptureTime = time.time() + 0.1
faces = faceCascade.detectMultiScale(gray, 1.3, 5)
if 0 < len(faces):
for x, y, w, h in faces:
cv2.rectangle(img, (x, y), (x + w, y + h), (255, 0, 0), 2)
cv2.imshow('FaceDetect', img)
# 这是简单的读取键盘输入,27即Esc的acsii码
if cv2.waitKey(1) & 0xFF == 27: break
capInput.release()
cv2.destroyAllWindows()
if __name__ == '__main__':
detect_face()
使用Face++完成人脸辨识
第一次认识Face++还是因为支付宝的人脸支付,响应速度还是非常让人满意的。
现在只需要免费注册一个账号然后新建一个应用就可以使用了,非常方便。
他的官方网址是这个,注册好之后在这里的我的应用中创建应用即可。
创建好应用之后你会获得API Key与API Secret。
Face++的API调用逻辑简单来说是这样的:
- 上传图片获取读取到的人的face_id
- 创建Person,获取person_id(Person中的图片可以增加、删除)
- 比较两个face_id,判断是否是一个人
- 比较face_id与person_id,判断是否是一个人
上传图片获取face_id
在将图片通过post方法上传到特定的地址后将返回一个json的值。
如果api_key, api_secret没有问题,且在上传的图片中有识别到人脸,那么会存储在json的face键值下。
#coding=utf8
import requests
# 这里填写你的应用的API Key与API Secret
API_KEY = ''
API_SECRET = ''
# 目前的API网址是这个,你可以在API文档里找到这些
BASE_URL = 'http://apicn.faceplusplus.com/v2'
# 使用Requests上传图片
url = '%s/detection/detect?api_key=%s&api_secret=%s&attribute=none'%(
BASE_URL, API_KEY, API_SECRET)
files = {'img': (os.path.basename(fileDir), open(fileDir, 'rb'),
mimetypes.guess_type(fileDir)[0]), }
r = requests.post(url, files = files)
# 如果读取到图片中的头像则输出他们,其中的'face_id'就是我们所需要的值
faces = r.json().get('face')
print faces
创建Person
这个操作没有什么可以讲的内容,可以对照这段程序和官方的API介绍。
官方的API介绍可以见这里,相信看完这一段程序以后你就可以自己完成其余的API了。
# 上接上一段程序
# 读取face_id
if not faces is None: faceIdList = [face['face_id'] for face in faces]
# 使用Requests创建Person
url = '%s/person/create'%BASE_URL
params = {
'api_key': API_KEY,
'api_secret': API_SECRET,
'person_name': 'LittleCoder',
'face_id': ','.join(faceIdList), }
r = requests.get(url, params = params)
# 获取person_id
print r.json.()['person_id']
进度确认
到目前为止,你应该已经可以就给定的两张图片比对是否是同一个人了。
那么让我们来试着写一下这个程序吧,两张图片分别为'pic1.jpg', 'pic2.jpg'好了。
下面我给出了我的代码:
def upload_img(fileDir, oneface = True):
url = '%s/detection/detect?api_key=%s&api_secret=%s&attribute=none'%(
BASE_URL, API_KEY, API_SECRET)
if oneface: url += '&mode=oneface'
files = {'img': (os.path.basename(fileDir), open(fileDir, 'rb'),
mimetypes.guess_type(fileDir)[0]), }
r = requests.post(url, files = files)
faces = r.json().get('face')
if faces is None:
print('There is no face found in %s'%fileDir)
else:
return faces[0]['face_id']
def compare(faceId1, faceId2):
url = '%s/recognition/compare'%BASE_URL
params = BASE_PARAMS
params['face_id1'] = faceId1
params['face_id2'] = faceId2
r = requests.get(url, params)
return r.json()
faceId1 = upload_img('pic1.jpg')
faceId2 = upload_img('pic2.jpg')
if face_id1 and face_id2:
print(compare(faceId1, faceId2))
else:
print('Please change two pictures')
成品
到此,所有的知识介绍都结束了,相比大致如何完成这个项目各位读者也已经有想法了吧。
下面我们需要构思一下人脸解锁的思路,大致而言是这样的:
- 使用一个程序设置账户(包括向账户中存储解锁用的图片)
- 使用另一个程序登陆(根据输入的用户名测试解锁)
这里会有很多重复的代码,就不再赘述了,你可以在这里或者这里(提取码:c073)下载源代码测试使用。
这里是设置账户的截图:
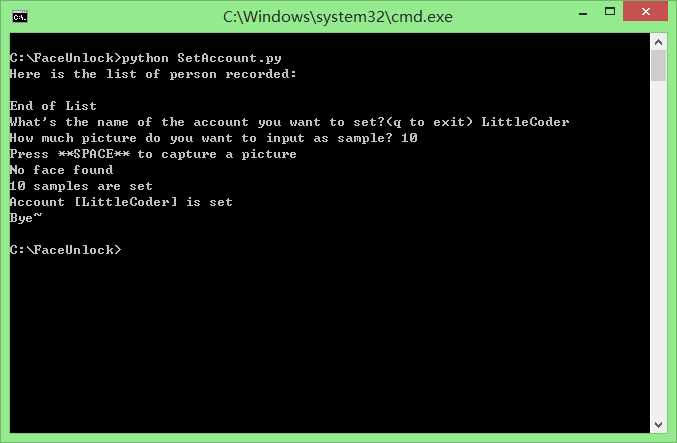
这里是登陆的截图:
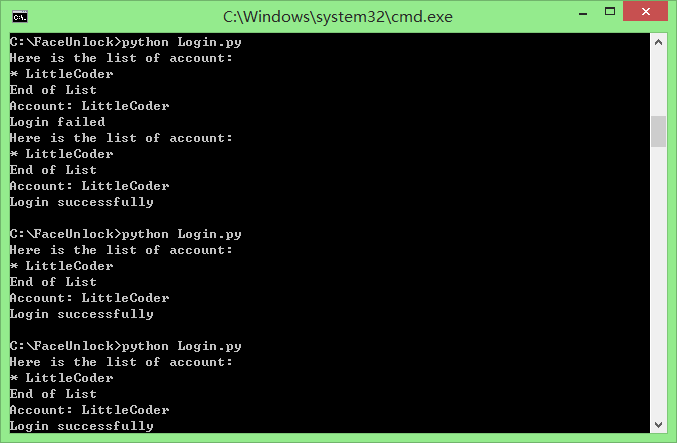
结束语
希望读完这篇文章能对你有帮助,有什么不足之处万望指正(鞠躬)。
160331
LittleCoder
EOF