【etcd】
一、ETCD 简介
etcd是一个由CoreOS团队开发的开源项目,旨在提供一个高可用的、分布式的、一致的键值存储,用于配置共享和服务发现。尽管它看起来像一个键值存储,但etcd的设计目标远远超出了传统数据库的功能范围。
etcd的核心特性包括:
- 高可用性和容错性:etcd使用Raft共识算法来确保数据的一致性和服务的高可用性。这意味着即使集群中的某些节点出现故障,etcd也能继续提供服务,并保证数据的一致性。
- 分布式一致性:etcd通过Raft算法确保所有节点上的数据都是一致的。这意味着无论你从集群中的哪个节点读取数据,你都会得到相同的结果。
- 键值存储:etcd提供了一个简单的键值接口,允许用户存储和检索数据。这些键值对可以组织成层次化的目录结构,类似于文件系统。
- Watch机制:etcd支持watch机制,允许客户端订阅特定键或前缀的变化。当这些键的值发生变化时,etcd会实时通知客户端。
- 安全性:etcd支持SSL/TLS加密和客户端证书验证,以确保数据传输的安全性。
- 与Kubernetes的集成:etcd是Kubernetes集群的核心组件之一,用于存储集群的状态信息,如Pods、Services、Deployments等的配置。
尽管etcd具有键值存储的特性,但它通常不被归类为传统的关系型数据库或非关系型数据库。相反,它被视为一种专门用于配置管理、服务发现和分布式协调的特殊类型存储系统。etcd的设计目标是提供高可用性、一致性和简单的API,以支持复杂的分布式系统。
二、ETCD 部署
以 CentOS 7 为例,可以通过 yum install -y etcd 进行安装。
然而通过系统工具安装的 etcd 版本比较滞后,如果需要安装最新版本的 etcd ,可以通过二进制包、源码编译以及 Docker 容器安装。
1、二进制安装
脚本来源: Github etcd-io/etcd
# etcd 版本
ETCD_VER=v3.5.18
# etcd 下载地址
DOWNLOAD_URL=https://github.com/etcd-io/etcd/releases/download
rm -f /tmp/etcd-${ETCD_VER}-linux-amd64.tar.gz
rm -rf /tmp/etcd-download-test && mkdir -p /tmp/etcd-download-test
curl -L ${DOWNLOAD_URL}/${ETCD_VER}/etcd-${ETCD_VER}-linux-amd64.tar.gz -o /tmp/etcd-${ETCD_VER}-linux-amd64.tar.gz
tar xzvf /tmp/etcd-${ETCD_VER}-linux-amd64.tar.gz -C /tmp/etcd-download-test --strip-components=1
rm -f /tmp/etcd-${ETCD_VER}-linux-amd64.tar.gz
/tmp/etcd-download-test/etcd --version
/tmp/etcd-download-test/etcdctl version
/tmp/etcd-download-test/etcdutl version
# start a local etcd server
/tmp/etcd-download-test/etcd
# write,read to etcd
/tmp/etcd-download-test/etcdctl --endpoints=localhost:2379 put foo bar
/tmp/etcd-download-test/etcdctl --endpoints=localhost:2379 get foo
2、Docker 部署
etcd uses gcr.io/etcd-development/etcd as a primary container registry, and quay.io/coreos/etcd as secondary.
ETCD_VER=v3.5.18
rm -rf /tmp/etcd-data.tmp && mkdir -p /tmp/etcd-data.tmp && \
docker rmi gcr.io/etcd-development/etcd:${ETCD_VER} || true && \
docker run \
-p 2379:2379 \
-p 2380:2380 \
--mount type=bind,source=/tmp/etcd-data.tmp,destination=/etcd-data \
--name etcd-gcr-${ETCD_VER} \
gcr.io/etcd-development/etcd:${ETCD_VER} \
/usr/local/bin/etcd \
--name s1 \
--data-dir /etcd-data \
--listen-client-urls http://0.0.0.0:2379 \
--advertise-client-urls http://0.0.0.0:2379 \
--listen-peer-urls http://0.0.0.0:2380 \
--initial-advertise-peer-urls http://0.0.0.0:2380 \
--initial-cluster s1=http://0.0.0.0:2380 \
--initial-cluster-token tkn \
--initial-cluster-state new \
--log-level info \
--logger zap \
--log-outputs stderr
docker exec etcd-gcr-${ETCD_VER} /usr/local/bin/etcd --version
docker exec etcd-gcr-${ETCD_VER} /usr/local/bin/etcdctl version
docker exec etcd-gcr-${ETCD_VER} /usr/local/bin/etcdutl version
docker exec etcd-gcr-${ETCD_VER} /usr/local/bin/etcdctl endpoint health
docker exec etcd-gcr-${ETCD_VER} /usr/local/bin/etcdctl put foo bar
docker exec etcd-gcr-${ETCD_VER} /usr/local/bin/etcdctl get foo
3、ETCD 集群部署
etcd 有三种集群化启动的配置方案,分别为静态配置启动、etcd动态发现、DNS发现。
| 特性 | DNS 自发现 | etcd 自发现服务 | 静态配置 |
|---|---|---|---|
| 核心原理 | 依赖 DNS SRV 记录解析节点地址 | 通过预生成的发现 URL(托管于外部 etcd 服务)自动发现节点 | 手动指定所有节点的 IP 或域名 |
| 适用场景 | 动态 IP 环境(如 Kubernetes) | 初始化新集群,无现有节点引导时使用 | 固定 IP 的物理机/虚拟机 |
| 扩展性 | 新增节点无需修改已有配置,自动加入 | 仅用于集群初始化,后续扩容需其他机制 | 需手动更新所有节点的配置 |
| 复杂度 | 需维护 DNS SRV 和 A/CNAME 记录 | 需管理发现 URL(生成、过期处理) | 配置简单,但维护成本高 |
| 依赖服务 | DNS 服务器 | 外部的 etcd 发现服务(公有或自建) | 无 |
| 典型用例 | 云环境动态集群(如 AWS、GCP) | 首次启动无静态配置的集群 | 本地测试或小型固定环境 |
| TLS 要求 | 强制要求 TLS 加密 | 不强制,但建议启用 | 可选 |
| 动态节点变更 | 支持(通过更新 DNS 记录) | 仅初始化阶段有效,后续需手动干预 | 不支持,需重启集群 |
| 故障恢复能力 | 节点重启后自动重连 DNS 解析 | 依赖发现 URL 的有效性 | 依赖静态配置的持久性 |
搭建 etcd 集群,环境信息如下:
| HostName | ip | 客户端交互端口 | peer 通信端口 |
|---|---|---|---|
| etcd1 | 10.0.1.10 | 2379 | 2380 |
| etcd2 | 10.0.1.11 | 2379 | 2380 |
| etcd3 | 10.0.1.12 | 2379 | 2380 |
3.1 静态配置
静态启动 etcd 集群要求:在启动整个集群之前,已经预先清楚所要配置的集群大小,以及集群上各节点的地址和端口信息的场景。
配置方式:在启动etcd服务时,通过命令行参数或环境变量来配置集群信息。
二进制部署启动ectd服务:
etcd -name etcd0 \
--listen-client-urls http://10.0.1.10:2379 \
--advertise-client-urls http://10.0.1.10:2379 \
--initial-advertise-peer-urls http://10.0.1.10:2380 \
--listen-peer-urls http://10.0.1.10:2380 \
--initial-cluster etcd0=http://10.0.1.10:2380,etcd1=http://10.0.1.11:2380,etcd2=http://10.0.1.12:2380 \
--initial-cluster-state new \
--initial-cluster-token tkn
配置项说明:
--name # etcd集群中的节点名,这里可以随意,可区分且不重复就行
--listen-peer-urls # 监听的用于节点之间通信的url,可监听多个,集群内部将通过这些url进行数据交互(如选举,数据同步等)
--initial-advertise-peer-urls # 建议用于节点之间通信的url,节点间将以该值进行通信。
--listen-client-urls # 监听的用于客户端通信的url,同样可以监听多个。
--advertise-client-urls # 建议用于客户端通信的url,该值用于 etcd 代理或 etcd 成员与 etcd 节点通信。
--initial-cluster-token # etcd-cluster-1,节点的 token 值,设置该值后集群将生成唯一 id,并为每个节点也生成唯一 id,当使用相同配置文件再启动一个集群时,只要该 token 值不一样,etcd 集群就不会相互影响。
--initial-cluster # 也就是集群中所有的 initial-advertise-peer-urls 的合集。
--initial-cluster-state # new,新建集群的标志
docker 部署 etcd集群:
docker run \
-p 2379:2379 \
-p 2380:2380 \
--volume=/var/lib/etcd:/etcd-data \
--name ectd gcr.io/etcd-development/etcd:3.5.18 \
/usr/local/bin/etcd \
--name ectd0
--data-dir=/etcd-data \
--initial-advertise-peer-urls http://10.0.1.10:2380 \
--listen-peer-urls http://0.0.0.0:2380 \
--advertise-client-urls http://10.0.1.10:2379 \
--listen-client-urls http://0.0.0.0:2379 \
--initial-cluster etcd0=http://10.0.1.10:2380,etcd1=http://10.0.1.11:2380,etcd2=http://10.0.1.12:2380 \
--initial-cluster-state new \
--initial-cluster-token etcd-cluster-1
3.2 通过DNS进行服务发现
原理:
- ETCD集群与DNS服务器的集成:
- ETCD提供了一个名为etcd-dns的插件,该插件可以将ETCD中的数据自动同步到DNS服务器中。
- 当ETCD集群中的服务实例发生变化时(如新节点的加入或旧节点的离开),etcd-dns会自动更新DNS记录,确保客户端能够获取到最新的服务地址。
- 客户端的DNS查询:
- 客户端在需要调用ETCD集群中的服务时,会通过DNS查询服务的名称。
- DNS服务器会返回与该服务名称对应的服务实例地址列表。
- 客户端可以从返回的地址列表中选择一个或多个服务实例进行通信。
搭建步骤:
# 1、安装 dnsmasq 来提供 DNS服务
sudo yum install -y dnsmasq
# 2、编辑`/etc/dnsmasq.conf`文件,添加以下配置以支持SRV记录
cat > /etc/dnsmasq.conf << EOF
# SRV记录(核心发现机制)
_etcd-server-ssl._tcp.example.com. 300 IN SRV 0 0 2380 etcd-1.example.com.
_etcd-server-ssl._tcp.example.com. 300 IN SRV 0 0 2380 etcd-2.example.com.
_etcd-server-ssl._tcp.example.com. 300 IN SRV 0 0 2380 etcd-3.example.com.
# A记录(节点IP解析)
etcd-1.example.com. 300 IN A 10.0.1.10
etcd-2.example.com. 300 IN A 10.0.1.11
etcd-3.example.com. 300 IN A 10.0.1.12
EOF
# 3、启动 dnsmasq,且添加开机自启
sudo systemctl start dnsmasq
sudo systemctl enable dnsmasq
# 4、下载安装 etcd
ETCD_VER=v3.5.18
curl -L https://github.com/etcd-io/etcd/releases/download/${ETCD_VER}/etcd-${ETCD_VER}-linux-amd64.tar.gz -o /tmp/etcd-${ETCD_VER}-linux-amd64.tar.gz
tar xzvf /tmp/etcd-${ETCD_VER}-linux-amd64.tar.gz -C /tmp/etcd-download-test --strip-components=1
# 5、启动ectd节点
etcd \
--name etcd-1 \
--discovery-srv example.com \ # 指定DNS域名
--initial-cluster-token etcd-cluster \ # 集群唯一标识
--initial-advertise-peer-urls https://etcd-1.example.com:2380 \
--listen-peer-urls https://0.0.0.0:2380 \
--listen-client-urls https://0.0.0.0:2379 \
--advertise-client-urls https://etcd-1.example.com:2379 \
--cert-file=/etc/etcd/ssl/etcd.pem \ # TLS证书
--key-file=/etc/etcd/ssl/etcd-key.pem \
--peer-cert-file=/etc/etcd/ssl/etcd.pem \
--peer-key-file=/etc/etcd/ssl/etcd-key.pem \
--trusted-ca-file=/etc/etcd/ssl/ca.pem \
--peer-trusted-ca-file=/etc/etcd/ssl/ca.pem
# 6、查看集群成员列表
ETCDCTL_API=3 etcdctl \
--endpoints=https://etcd-1.example.com:2379 \
--cacert=/etc/etcd/ssl/ca.pem \
--cert=/etc/etcd/ssl/etcd.pem \
--key=/etc/etcd/ssl/etcd-key.pem \
member list
注意事项:
- DNS TTL设置
- 建议SRV记录TTL ≤ 300秒(5分钟),确保节点变更快速生效。
- 网络要求
- 开放端口:2379(客户端通信)、2380(节点间通信)
- 确保所有节点间双向可达,且DNS解析一致。
- TLS强制要求
- DNS自发现模式必须启用TLS加密,否则etcd会拒绝启动。
- 集群扩展
- 新增节点时,只需配置相同–discovery-srv和–initial-cluster-token即可自动加入。
常见故障排查:
- DNS解析失败
# 检查SRV记录解析 dig +short SRV _etcd-server-ssl._tcp.example.com # 检查A记录解析 dig +short etcd-1.example.com - 证书错误
- 错误日志:x509: certificate signed by unknown authority
- 解决方法:确保所有节点使用相同的CA证书,且证书包含正确的主机名(SAN扩展)。
- 节点无法加入集群
- 检查日志:
journalctl -u etcd - 确认参数
--initial-advertise-peer-urls与SRV记录中的地址完全一致。
- 检查日志:
3.3 etcd自身服务发现
原理:新的etcd节点在启动时不会直接指定集群中其他节点的地址,而是通过一个预先存在的etcd集群(通常称为“bootstrap集群”或“辅助集群”)来获取这些信息。这个预先存在的etcd集群充当了服务发现的媒介,新的节点通过向它发送请求来获取集群的当前状态和其他节点的地址。
注意:etcd v3版本之后,官方推荐使用etcd的DNS SRV记录或静态配置(通过命令行参数或配置文件)来进行服务发现,而不是discovery URL。即discovery URL的方式在etcd v3版本中已经不再是推荐的做法,且可能在未来的版本中被移除。
ectd 启动命令:
# etcd1 启动
$ /opt/etcd/bin/etcd --name etcd1 \
--data-dir /opt/etcd/data \
--initial-advertise-peer-urls http://10.0.1.10:2380 \
--listen-peer-urls http://10.0.1.10:2380 \
--listen-client-urls http://10.0.1.10:2379,http://127.0.0.1:2379 \
--advertise-client-urls http://10.0.1.10:2379 \
--discovery https://discovery.etcd.io/3e86b59982e49066c5d813af1c2e2579cbf573de
--discovery 参数来指定一个discovery URL。
discovery URL的格式通常是 https://
启动etcd服务前,需先在 discovery服务上设置一个特定的键(key),该键用于配置 discovery 服务中某个集群的大小。
完整示例:
# 生成一个新的discovery令牌
uuid=$(uuidgen)
cluster_size=3
# 指定预期的集群大小
curl -X PUT "http://:2379/v2/keys/_etcd/registry/${uuid}/_config/size" -d value=${cluster_size}
# 启动etcd节点时使用discovery URL
etcd --discovery "http:///v2/keys/${uuid}" --name <node-name> --initial-advertise-peer-urls <peer-url>
三、ETCD 架构
etcd v3 技术架构图:
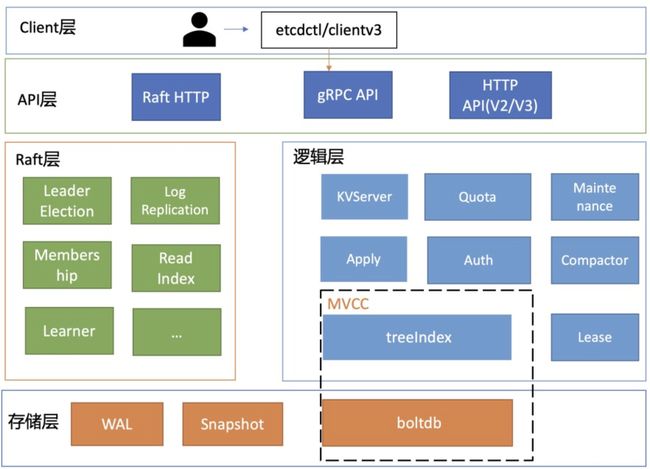
etcd的架构可以按照分层模型进行划分,主要包括以下几个层次:
- Client层:
- 提供client v2和v3两个大版本的API客户端库。
- 支持负载均衡和节点间故障自动转移,降低业务使用etcd的复杂度。
- 提供简洁易用的API,提升开发效率和服务可用性。
- API网络层:
- 包括client访问server和server节点之间的通信协议。
- client访问etcd server的API分为v2和v3两个版本,v2使用HTTP/1.x协议,v3使用gRPC协议,同时v3也支持通过etcd grpc-gateway组件使用HTTP/1.x协议。
- server节点之间通过Raft算法实现数据复制和Leader选举等功能时使用HTTP协议。
- Raft算法层:
- 实现Leader选举、日志复制、ReadIndex等核心算法特性。
- 保障etcd多个节点间的数据一致性,提升服务可用性。
- 是etcd架构的基石和亮点。
- 功能逻辑层:
- 实现etcd的核心特性,如KVServer模块、MVCC模块、Auth鉴权模块、Lease租约模块、Compactor压缩模块等。
- MVCC模块主要由treeIndex模块和boltdb模块组成,支持多版本并发控制。
- 存储层:
- 包含预写日志(WAL)模块、快照(Snapshot)模块、boltdb模块。
- WAL保障etcd崩溃后数据不丢失,boltdb保存集群元数据和用户写入的数据。
四、ETCD 数据处理
ETCD 作为高可用的分布式键值存储系统,其处理客户端请求的全过程严格遵循 Raft 协议,确保数据强一致性。
数据处理流程图解:
客户端请求
│
▼
ETCD 节点(Leader/Follower)
│
├─ 写请求 → Leader 处理:
│ 1. 写 WAL → 2. Raft 复制 → 3. Apply 到 BoltDB → 4. 响应客户端
│
└─ 读请求:
├─ 线性读:Leader 确认身份 → 读 BoltDB → 响应
└─ 串行读:直接读本地 BoltDB → 响应
详细的数据处理流程:
- 客户端发起请求
- 请求类型:客户端通过 gRPC/HTTP API 发起请求,分为写请求(Put/Delete)和读请求(Get)两类。
- 连接节点:客户端随机或通过负载均衡连接到 ETCD 集群中的某个节点。
- 节点角色判断 Leader/Follower
- 若客户端连接到 Follower:
- 写请求:Follower 返回重定向响应(HTTP 307 或 gRPC 错误),附上当前 Leader 的地址。
- 读请求:根据一致性模式处理(见下文)。
- 若客户端连接到 Leader:直接处理请求。
- 若客户端连接到 Follower:
- 写请求处理流程
- 预提交阶段(Propose)
- 日志封装:Leader 将写请求封装为 Raft 日志条目,包含操作类型(Put/Delete)、键值数据及任期号(Term)。
- 本地写入 WAL:Leader 将日志条目追加到 预写日志(Write-Ahead Log, WAL),确保数据持久化,防止节点崩溃后数据丢失。
- Raft 日志复制
- 广播日志条目:Leader 通过 Raft 模块将日志条目发送给所有 Follower。
- Follower 处理:
- Follower 验证日志条目的 Term 和索引是否连续。
- 验证通过后,将日志写入本地 WAL,返回确认(ACK)给 Leader。
- 多数派确认:Leader 收到超过半数节点的 ACK 后,标记日志条目为 已提交(Committed)。
- 应用日志到状态机
- Apply 到存储引擎:Leader 将已提交的日志条目应用到 BoltDB(存储引擎),更新键值数据。
- 通知客户端:应用成功后,Leader 返回响应(如 OK)给客户端。
- 响应客户端
- 只有在日志成功提交(多数派确认)并应用到 BoltDB 后,Leader 才会向客户端返回成功响应(如 HTTP 200 OK)。
- 若失败(如网络分区、节点宕机),客户端会收到超时或错误(如 context deadline exceeded)。
- 预提交阶段(Propose)
- 读请求处理流程
ETCD 支持两种一致性模式:- 线性一致性读(Linearizable Read)
- Leader 心跳确认:Leader 先向集群发送一次心跳,确认自己仍是合法 Leader(避免脑裂导致脏读)。
- 读取最新数据:直接从 Leader 的 BoltDB 中读取数据,确保结果是最新已提交的状态。
- 响应客户端
- 若 Leader 已失效但未自感知,可能因心跳失败触发选举,客户端最终会收到错误或重定向。
- 串行化读(Serializable Read)
- 本地读取:任意节点直接读取自身 BoltDB 的最新已提交数据,不保证强一致性(可能读到陈旧数据)。
- 立即响应客户端。
- 响应可能包含陈旧数据(未通过 Raft 确认最新状态)。
- 线性一致性读(Linearizable Read)
关键组件协作:
- Raft 模块:负责日志复制、Leader 选举和状态机应用。
- WAL:确保日志持久化,支持崩溃恢复。
- BoltDB:底层存储引擎,以 B+ 树结构管理键值数据。
- gRPC Server:处理客户端请求和集群节点间通信。
数据一致性保障:
- Raft 协议:通过 Leader 选举、日志复制和多数派提交机制,确保数据强一致性。
- ReadIndex 机制:用于线性一致性读,避免过期 Leader 返回脏数据。
- 租约(Lease):结合 TTL 机制自动删除过期键,保障数据的实时有效性。
性能优化:
- 批处理(Batching):合并多个写请求的日志条目,减少 RPC 次数。
- 流水线(Pipeline):并行发送日志条目,提升复制效率。
- 快照(Snapshot):定期压缩日志,减少磁盘占用和恢复时间。
五、ETCD gRPC Proxy
1、概述
ETCD gRPC Proxy 是一个面向高性能场景的智能代理层,通过请求合并、响应缓存、负载均衡等机制显著提升集群的读吞吐量,同时简化客户端逻辑。
适用于需要缓解 Leader 压力、优化高频读操作的场景(如 Kubernetes 大规模集群)。
结合监控和调优,可最大化发挥其性能优势。
2、gRPC Proxy 的核心功能
(1)请求合并(Request Coalescing)
- 场景:多个客户端同时请求同一个键(例如 /registry/pods)。
- 机制:Proxy 将多个相同请求合并为单个请求发送到 ETCD 集群,并将结果返回给所有客户端。
- 优势:减少对 ETCD 的重复请求,降低 Leader 负载,尤其适用于高频读场景(如 Kubernetes 的 List-Watch)。
(2)响应缓存(Caching)
- 缓存策略:Proxy 缓存频繁访问的键值数据(如 Get 和 Range 请求结果)。
- 缓存失效:
- 租约过期:与键关联的租约(Lease)到期时自动失效缓存。
- 写操作触发:监听到键的写操作(Put/Delete)时,主动清除相关缓存。
- 优势:减少对 ETCD 存储引擎的直接访问,提升读吞吐量。
(3)负载均衡
- 请求分发:
- 写请求:自动转发给当前 Leader。
- 读请求:根据配置分发到 Leader 或任意健康 Follower。
- 健康检查:定期检查后端节点状态,屏蔽不可用节点。
(4)透明重试与故障转移
- 自动重试:若请求失败(如网络抖动),Proxy 自动重试其他节点。
- Leader 切换感知:当 Leader 变更时,Proxy 自动更新转发目标,客户端无感知。
(5)指标与监控
- 暴露 Prometheus 指标:如请求延迟、缓存命中率、节点健康状态等。
- 集成监控:与 Prometheus + Grafana 无缝对接,便于性能分析和故障排查。
3、架构与工作原理
(1)架构示意图
+------------+ +------------+
| Client A | | Client B |
+-----+------+ +------+-----+
| |
| |
+-----+---------------------+-----+
| ETCD gRPC Proxy |
| (gRPC Layer, Cache, Load Balancer)|
+-----+---------------------+-----+
| |
+----------+----------+ +-----+--------+
| ETCD Node 1 | | ETCD Node 2 |
| (Leader/Follower) | | (Follower) |
+----------------------+ +---------------+
(2)核心组件
- gRPC 服务端:接收客户端请求,解析协议内容。
- 缓存管理器:管理内存中的键值缓存及失效逻辑。
- 负载均衡器:动态维护 ETCD 节点列表并分发请求。
- 监控模块:收集性能指标并暴露给监控系统。
4、部署与配置
(1)启动命令示例
# 启动 gRPC Proxy,指定 ETCD 集群节点
etcd grpc-proxy start \
--endpoints=http://etcd-node1:2379,http://etcd-node2:2379 \
--listen-addr=0.0.0.0:23790 \
--cache-size=10000 \
--enable-caching=true \
--metrics=extensive
etcd grpc-proxy start \
--discovery-srv=example.com \ # 指定 DNS 域名
--listen-addr=0.0.0.0:23790 \ # Proxy 监听地址
--advertise-client-url=http://proxy.example.com:23790 \ # 客户端访问地址
--cluster-service-name=etcd-server \ # 服务名(与 SRV 记录中的 _etcd-server 对应)
--dns-tls=skip-verify \ # 可选:跳过 DNS 查询的 TLS 验证
--cache-size=10000 \ # 启用缓存
--metrics=extensive # 输出详细指标
etcd grpc-proxy start \
--discovery-srv=example.com \
--listen-addr=0.0.0.0:23790 \
--cluster-service-name=etcd-server \
--cert-file=/etc/etcd/proxy.crt \ # Proxy 的客户端证书
--key-file=/etc/etcd/proxy.key \ # Proxy 的私钥
--trusted-ca-file=/etc/etcd/ca.crt \ # ETCD 集群的 CA 证书
--client-cert-auth \ # 要求 ETCD 验证 Proxy 的证书
--dns-tls=secure # 启用 DNS-over-TLS
(2)关键参数
| 参数 | 说明 |
|---|---|
--endpoints |
ETCD 集群的初始节点列表(用于动态发现成员) |
--listen-addr |
Proxy 监听的地址和端口(默认 0.0.0.0:23790) |
--cache-size |
缓存的最大键值条目数(默认 0,即不启用缓存) |
--enable-caching |
启用读请求缓存(需配合 --cache-size) |
--metrics |
指标输出模式(basic/extensive) |
--retry-delay |
请求失败后的重试间隔(默认 1s) |
--advertise-client-url |
对外公布的客户端访问地址(用于集群内通信) |
--discovery-srv |
DNS 域名(如 example.com),用于查找 _etcd-server._tcp.example.com SRV 记录。 |
--cluster-service-name |
服务名称前缀(与 SRV 记录中的 _ 匹配,默认为 etcd-server)。 |
--dns-tls |
DNS 查询的 TLS 验证模式,可选值:none、skip-verify(跳过验证)、secure(需配置 CA)。 |
--advertise-client-url |
Proxy 对外公布的客户端访问地址(用于服务注册或客户端连接)。 |
(3)客户端连接示例
客户端直接连接 Proxy 地址(而非具体 ETCD 节点):
# 使用 etcdctl 客户端
ETCDCTL_API=3 etcdctl --endpoints=http://proxy:23790 get mykey
5、适用场景
(1)高频读场景
- Kubernetes 控制平面:大量组件(如 kube-apiserver)频繁 List-Watch 资源对象。
- 配置中心:高频读取全局配置项。
(2)提升读吞吐量
- 通过缓存和请求合并,显著降低 ETCD 集群的读负载。
(3)弱化客户端逻辑
- 客户端无需处理节点发现、重试、负载均衡等逻辑,由 Proxy 统一管理。
6、高级功能与优化
(1)线性一致性读优化
- ReadIndex 代理:Proxy 可代替客户端执行 ReadIndex 机制,确保线性一致性读的可靠性,同时减少客户端与集群的交互。
(2) 限流与熔断
- 请求限流:通过参数限制每秒请求量(需结合外部工具如 Istio)。
- 熔断机制:当后端 ETCD 节点不可达时,暂时拒绝请求防止雪崩。
(3)TLS 终止
- 客户端加密:Proxy 可终止 TLS 连接,将明文请求转发给 ETCD 集群(需配置证书):
etcd grpc-proxy start \ --listen-addr=0.0.0.0:23790 \ --endpoints=https://etcd-node:2379 \ --cert-file=client.crt \ --key-file=client.key \ --trusted-ca-file=ca.crt
7、性能调优建议
(1)缓存策略优化
- 调整缓存大小:根据内存容量和热点数据规模设置 --cache-size。
- 避免大键值缓存:过大值会挤占缓存空间,降低命中率。
(2)资源分配
- 内存:为 Proxy 分配足够内存以容纳缓存(建议缓存大小不超过可用内存的 50%)。
- CPU:高并发场景下,Proxy 的 CPU 可能成为瓶颈(需监控 grpc_proxy_cpu_usage)。
(3)监控指标关注
| 指标名称 | 说明 | 健康阈值 |
|---|---|---|
| grpc_proxy_cache_hits | 缓存命中次数 | 命中率 > 60% |
| grpc_proxy_request_duration | 请求处理延迟 | P99 < 100ms |
| grpc_proxy_upstream_errors | 后端 ETCD 节点错误次数 | 持续增长需报警 |
| grpc_proxy_coalesced_requests | 合并的请求数 | 值越高说明优化效果越好 |
8、与 ETCD Gateway 的对比
| 特性 | ETCD Gateway | ETCD gRPC Proxy |
|---|---|---|
| 协议层 | TCP 层代理 | gRPC 层代理(理解协议内容) |
| 动态成员发现 | 支持 | 支持 |
| 高级功能 | 无 | 支持缓存、请求合并、故障注入等 |
| TLS 终止 | 不支持 | 支持 |
| 适用场景 | 简单转发、隐藏集群拓扑 | 高频读、需要缓存和协议优化的场景 |
9、实际应用案例
(1)Kubernetes 集群优化
- 问题:kube-apiserver 频繁 List-Watch Pod/Service,导致 ETCD Leader 负载过高。
- 解决方案:
- 在 kube-apiserver 与 ETCD 之间部署 gRPC Proxy。
- 启用缓存(–cache-size=100000)和请求合并。
- 结果:ETCD 读 QPS 下降 70%,Leader CPU 使用率降低 50%。
六、ETCD Gateway
ETCD Gateway 是 ETCD 官方提供的一个轻量级代理组件,主要用于简化客户端与 ETCD 集群之间的连接管理和负载均衡。它的核心目标是降低客户端配置复杂度,并在集群节点变更时提供透明的连接重定向能力。
ETCD Gateway 功能较为基础,对于需要高级流量控制或协议优化的场景,建议结合 gRPC Proxy 使用。
1、ETCD Gateway 的核心作用
(1)解决的问题
- 客户端配置简化:客户端无需维护完整的 ETCD 集群节点列表,只需通过 Gateway 连接。
- 动态节点发现:当 ETCD 集群节点扩缩容或 IP 变更时,Gateway 自动感知并更新后端节点列表。
- 负载均衡:将客户端请求分发到多个 ETCD 节点,避免单点压力。
(2)适用场景
- 客户端无法动态感知 ETCD 集群节点变化(如静态配置的应用)。
- 需要对外隐藏 ETCD 集群内部拓扑(增强安全性)。
- 在客户端与 ETCD 集群之间增加一层代理,实现流量控制或监控。
2、Gateway 的工作模式
(1) 透明代理
- TCP 层代理:Gateway 工作在 TCP 层,不解析 ETCD 的 gRPC/HTTP 协议内容,仅转发原始字节流。
- 无状态设计:Gateway 本身不存储任何数据,仅维护 ETCD 节点的地址列表。
(2)节点发现机制
- 启动时配置:Gateway 启动时通过 --endpoints 参数指定 ETCD 集群的初始节点列表。
- 动态更新:定期通过 ETCD 的 Members API 获取最新的集群成员信息,自动更新代理目标。
(3)请求转发逻辑
- 客户端连接 Gateway:客户端向 Gateway 发起连接(默认端口 23790)。
- 选择后端节点:
- 如果是写请求:Gateway 将请求转发给当前 Leader 节点。
- 如果是读请求:可配置为转发给任意健康节点(默认随机选择)。
- 响应透传:ETCD 节点的响应直接返回给客户端,不经过 Gateway 处理。
3、Gateway 的架构与部署
(1)架构示意图
+------------+ +------------+
| Client A | | Client B |
+-----+------+ +------+-----+
| |
| |
+-----+---------------------+-----+
| ETCD Gateway |
| (Proxy Layer, Port 23790) |
+-----+---------------------+-----+
| |
+----------+----------+ +-----+--------+
| ETCD Node 1 | | ETCD Node 2 |
| (Leader/Follower) | | (Follower) |
+----------------------+ +---------------+
(2)高可用部署
- 多实例部署:可启动多个 Gateway 实例,结合负载均衡器(如 Nginx、HAProxy)实现高可用。
- 健康检查:负载均衡器需对 Gateway 实例进行健康检查(如 TCP 端口探测)。
4、Gateway 的配置与使用
(1)启动 Gateway
$ etcd gateway start --help
start the gateway
Usage:
etcd gateway start [flags]
Flags:
--discovery-srv string DNS domain used to bootstrap initial cluster
--discovery-srv-name string service name to query when using DNS discovery
--endpoints strings comma separated etcd cluster endpoints (default [127.0.0.1:2379])
-h, --help help for start
--insecure-discovery accept insecure SRV records
--listen-addr string listen address (default "127.0.0.1:23790") 默认监听端口
--retry-delay duration duration of delay before retrying failed endpoints (default 1m0s) 重试连接到失败的端点延迟时间,默认为 1m0s
--trusted-ca-file string path to the client server TLS CA file for verifying the discovered endpoints when discovery-srv is provided.
底层实现就是启动两个协程:一个定时监控etcd集群的服务器是否存活,一个负责处理请求。
在启动网关的时候,需要获取对应的ip地址(两种方式,一种是通过dns服务,一种是直接域名)。
(2)示例
etcd gateway start \
--endpoints=http://etcd-node1:2379,http://etcd-node2:2379 \
--listen-addr=0.0.0.0:23790
# 若 etcd 集群启用 TLS,需为网关配置相同的 CA 证书、客户端证书和密钥
etcd gateway start \
--discovery-srv example.com \ # 指定 DNS 域名(SRV 记录所在域)
--listen-addr 0.0.0.0:23790 \ # 网关监听地址(客户端连接此端口)
--cert-file /etc/etcd/ssl/client.pem \ # 客户端证书
--key-file /etc/etcd/ssl/client-key.pem \ # 客户端私钥
--cacert-file /etc/etcd/ssl/ca.pem \ # CA 根证书
--insecure-discovery=false \ # 强制启用 TLS 验证(默认 false)
--debug # 可选:开启调试日志
(3)关键参数
| 参数 | 说明 |
|---|---|
| –endpoints | ETCD 集群的初始节点地址列表(用于动态发现成员) |
| –listen-addr | Gateway 监听的地址和端口(默认 0.0.0.0:23790) |
| –retry-delay | 节点连接失败后的重试延迟(默认 1s) |
| –debug | 启用调试日志 |
| –discovery-srv | 指定用于查询 SRV 记录的 DNS 域名(如 example.com)。 |
| –listen-addr | 网关监听的客户端连接地址(默认 0.0.0.0:23790)。 |
| TLS 相关参数 | 与 etcd 集群通信所需的证书和密钥,需确保与集群配置一致。 |
| –insecure-discovery | 设置为 false 时强制验证 TLS 证书;若为 true 则禁用验证(仅测试环境使用)。 |
(4)检查网关日志
journalctl -u etcd-gateway -f
预期输出:
INFO: Resolved SRV records: [etcd-1.example.com:2380 etcd-2.example.com:2380 etcd-3.example.com:2380]
INFO: Updated endpoints: [https://etcd-1.example.com:2379 https://etcd-2.example.com:2379 https://etcd-3.example.com:2379]
(5)客户端连接示例
客户端直接连接 Gateway 地址(而非具体 ETCD 节点):
# 使用 etcdctl 客户端
ETCDCTL_API=3 etcdctl --endpoints=http://gateway:23790 get mykey
5、Gateway 的局限性
(1)功能限制
- 不支持协议解析:无法实现高级功能(如请求过滤、缓存、TLS 终止)。
- 无重试机制:若后端节点故障,Gateway 不会自动重试其他节点(依赖客户端重试)。
- 仅限 TCP 层:无法优化 gRPC 的 HTTP/2 多路复用特性。
(2)性能影响
- 额外网络跳数:所有流量经过 Gateway,可能增加延迟。
- 单点瓶颈:若 Gateway 实例不足,可能成为性能瓶颈。
6、Gateway 与 gRPC 代理的对比
| 特性 | ETCD Gateway | ETCD gRPC Proxy |
|---|---|---|
| 协议层 | TCP 层代理 | gRPC 层代理(理解协议内容) |
| 动态成员发现 | 支持 | 支持 |
| 高级功能 | 无 | 支持缓存、请求合并、故障注入等 |
| TLS 终止 | 不支持 | 支持 |
| 适用场景 | 简单转发、隐藏集群拓扑 | 需要高级流量控制的场景 |
7、实际使用建议
- 安全性:若需 TLS 加密,应在 Gateway 外层部署负载均衡器(如 Nginx)处理 TLS 终止。
- 监控:监控 Gateway 的连接数和吞吐量,避免代理层成为瓶颈。
- 替代方案:若需要更丰富的代理功能(如缓存、请求合并),应优先使用 ETCD gRPC Proxy。
七、Raft
- 【算法篇】CAP、Paxos、Raft
- 【etcd】raft源码解析
八、Watch 机制
1、Watch 机制的核心概念
Watch 机制 允许客户端实时监听键(Key)或键范围(Key Range)的变化事件(如 Put、Delete 等),并接收异步通知。其设计目标是:
- 实时性:客户端无需轮询即可感知数据变更。
- 高效性:基于事件驱动,减少网络和计算开销。
- 可靠性:确保事件不丢失、不重复,支持断线重连。
2、Watch 的工作流程
(1)客户端发起监听
- 指定监听目标:单键(如 /key)、键前缀(如 /prefix/)或范围(如 [key1, key2))。
- 选择监听模式:
- 从当前版本监听:仅接收后续变更。
- 从历史版本监听:指定起始修订版本号(start_revision),获取所有后续变更。
示例命令(etcdctl):
# 监听键 /foo 的变更(仅新事件)
etcdctl watch /foo
# 监听前缀 /service/ 下的所有键,从修订版本 1000 开始
etcdctl watch --prefix /service/ --rev=1000
(2) 服务端处理监听
- 注册 Watcher:服务端为每个监听请求创建一个 Watcher 对象,记录监听范围和起始修订版本。
- 事件匹配:当键值变更时,ETCD 生成事件(Event),匹配所有关联的 Watcher。
- 事件推送:通过 gRPC 流(Stream)将事件实时推送给客户端。
(3)客户端处理事件
- 流式接收:客户端通过 gRPC 流持续接收事件。
- 事件确认:无需显式 ACK,ETCD 保证事件至少传递一次(at-least-once)。
3、Watch 的事件类型与数据结构
(1) 事件类型
| 类型 | 触发条件 | 说明 |
|---|---|---|
| PUT | 键被创建或更新 | 包含新值(KeyValue) |
| DELETE | 键被删除 | 包含被删除的键及其最后版本信息 |
(2)事件数据结构(protobuf)
message Event {
enum EventType {
PUT = 0;
DELETE = 1;
}
EventType type = 1;
KeyValue kv = 2; // 仅 PUT 事件有效
KeyValue prev_kv = 3; // 仅当监听时指定 prev_kv 时有效
}
4、Watch 的底层实现
(1) MVCC(多版本并发控制)
- 键值历史版本:ETCD 为每个键维护版本链,每个修改生成新的修订版本(revision)。
- 事件生成:基于版本链生成事件,确保客户端能按顺序消费变更。
(2) Watcher 注册与事件分发
- Watcher 存储:所有 Watcher 按监听范围和起始修订版本组织,存储在内存中。
- 事件匹配逻辑:
- 键变更时,遍历所有 Watcher,检查键是否匹配监听范围。
- 若匹配,将事件加入 Watcher 的发送队列。
- 发送队列异步处理:通过 gRPC 流异步发送事件,避免阻塞主线程。
(3)历史事件回放
- 基于 BoltDB 的索引:通过 B+ 树索引按修订版本快速定位历史事件。
- 压缩优化:定期压缩(Compact)旧版本数据,释放存储空间(被压缩的版本无法监听)。
5、Watch 的关键特性
(1)可靠事件传递
- 持久化存储:事件基于 MVCC 持久化在 BoltDB 中,即使节点重启也不丢失。
- 断线重连:客户端可通过指定 start_revision 恢复监听,确保事件连续性。
- 至少一次投递:网络中断可能导致事件重复,需客户端处理幂等性。
(2)过滤与条件监听
- 事件过滤:可指定仅监听特定类型事件(如只接收 DELETE)。
- 前缀监听:通过 --prefix 监听某一前缀下的所有键变更。
- 范围监听:通过 --range 监听指定区间内的键。
(3)性能优化
- 流式传输:通过 gRPC 流减少连接开销。
- 事件合并:同一键的多次修改可能在一次推送中合并(取决于客户端处理速度)。
- 压缩控制:合理设置 --auto-compact 参数,避免历史版本过多影响性能。
6、Watch 的应用场景
(1)服务发现与健康检查
- 服务注册:服务启动时注册自身地址(如 /services/web/10.1.1.1:8080)。
- 实时下线检测:监听服务地址,若键被删除(Lease 过期),触发服务摘除逻辑。
(2)配置中心
- 动态配置更新:监听配置键(如 /config/app),实时推送新配置到所有实例。
(3)分布式协同
- 分布式锁:监听锁键释放事件,实现锁等待队列。
- 任务队列:监听任务键的创建事件,触发任务执行。
7、Watch 的 API 与客户端使用
(1)gRPC 接口
- Watch Service:提供 Watch 方法,建立双向流。
- 请求格式:
message WatchRequest { oneof request_union { WatchCreateRequest create_request = 1; // 创建监听 WatchCancelRequest cancel_request = 2; // 取消监听 } }
(2)Go 客户端示例
import (
"context"
"go.etcd.io/etcd/clientv3"
)
func main() {
cli, _ := clientv3.New(clientv3.Config{Endpoints: []string{"localhost:2379"}})
defer cli.Close()
// 监听前缀 /service/ 的所有变更
watchChan := cli.Watch(context.Background(), "/service/", clientv3.WithPrefix())
for resp := range watchChan {
for _, ev := range resp.Events {
switch ev.Type {
case clientv3.EventTypePut:
fmt.Printf("PUT: %s -> %s\n", ev.Kv.Key, ev.Kv.Value)
case clientv3.EventTypeDelete:
fmt.Printf("DELETE: %s\n", ev.Kv.Key)
}
}
}
}
8、注意事项与最佳实践
(1)监听性能优化
- 减少监听范围:尽量缩小监听键范围或使用精确匹配。
- 合理设置历史版本:避免从过旧的版本监听,减少历史数据扫描压力。
- 压缩策略:定期执行 etcdctl compact 清理旧版本,但需确保所有客户端不再需要这些版本。
(2)错误处理
- 网络中断:客户端需处理 gRPC 流错误,并重新建立监听(指定正确的 start_revision)。
- 事件重复:设计幂等处理逻辑,应对可能的重复事件投递。
(3)安全与权限
- RBAC 控制:为监听操作配置最小权限,如:
etcdctl role add watch-role etcdctl role grant-permission watch-role --prefix read /data/ etcdctl user add user1 etcdctl user grant-role user1 watch-role
9、Watch 与 Kubernetes 的集成
Kubernetes 重度依赖 ETCD 的 Watch 机制实现组件协同:
- kube-apiserver:监听 Pod、Service 等资源变化,实时更新集群状态。
- Controller Manager:通过 Watch 事件触发控制循环(如副本数修正)。
- Scheduler:监听未调度的 Pod,执行调度逻辑。
九、Lease 机制
1、Lease 的核心概念
Lease(租约) 是 ETCD 中用于管理键值对(Key-Value)生命周期的机制。
通过为键值对绑定 Lease,可以自动删除过期的键,实现以下功能:
- 自动清理:无需客户端主动删除,避免数据残留。
- 资源回收:防止因客户端崩溃或网络问题导致的无效数据堆积。
- 心跳保活:结合续约(KeepAlive)机制,用于服务注册与发现、分布式锁等场景。
2、Lease 的核心操作
(1)创建 Lease
# 创建一个 TTL 为 60 秒的 Lease
etcdctl lease grant 60
输出:lease 32695410dcc0ca06 granted with TTL(60s)
返回值:唯一 Lease ID(如 32695410dcc0ca06)。
(2)将键绑定到 Lease
# 将键 /service/node1 绑定到 Lease
etcdctl put /service/node1 10.1.1.1 --lease=32695410dcc0ca06
效果:当 Lease 过期时,所有绑定的键会被自动删除。
(3)续约(KeepAlive)
- 手动续约:
etcdctl lease keep-alive 32695410dcc0ca06 - 自动续约:客户端库(如 Go 的 clientv3)支持自动周期性续约,确保 Lease 永不过期(除非显式撤销)。
(4)查看 Lease 信息
- 检查 Lease 剩余时间:
输出:lease 32695410dcc0ca06 granted with TTL(60s), remaining(52s)etcdctl lease timetolive 32695410dcc0ca06 - 查看绑定的键:
输出:… attached keys: [/service/node1]etcdctl lease timetolive 32695410dcc0ca06 --keys
(5)撤销 Lease
主动释放:
etcdctl lease revoke 32695410dcc0ca06
效果:立即删除所有绑定的键,并释放 Lease。
3、Lease 的工作原理
(1)存储结构
- Lease 元数据:存储在 ETCD 的 内存中,包括 Lease ID、TTL、到期时间、绑定的键列表。
- 键的关联信息:键值对的元数据(Metadata)中记录其绑定的 Lease ID,持久化在 BoltDB 中。
(2)过期检测
- 基于时间的淘汰机制:
- Leader 节点维护一个 最小堆(Min-Heap),按 Lease 到期时间排序。
- 定期扫描堆顶,若当前时间超过到期时间,则触发删除所有绑定的键。
- 删除操作通过 Raft 日志复制到所有节点,确保一致性。
(3)续约逻辑
- 续约请求:客户端发送 LeaseKeepAlive 请求到 Leader。
- 更新到期时间:Leader 将 Lease 的到期时间延长(当前时间 + TTL),并同步到所有节点。
- 续约响应:返回新的 TTL 给客户端,确认续约成功。
4、Lease 的 API 接口
(1)gRPC 服务
ETCD 通过 LeaseService 提供 gRPC 接口:
- LeaseGrant:创建 Lease。
- LeaseRevoke:撤销 Lease。
- LeaseKeepAlive:续约(支持单次或流式续约)。
- LeaseTimeToLive:查询 Lease 状态。
(2)客户端库示例(Go)
import (
"context"
"time"
"go.etcd.io/etcd/clientv3"
)
func main() {
cli, _ := clientv3.New(clientv3.Config{
Endpoints: []string{"localhost:2379"},
DialTimeout: 5 * time.Second,
})
defer cli.Close()
// 创建 Lease(TTL=10秒)
lease, _ := cli.Grant(context.TODO(), 10)
// 绑定键
cli.Put(context.TODO(), "/service/node1", "10.1.1.1", clientv3.WithLease(lease.ID))
// 自动续约(每 5 秒一次)
keepAlive, _ := cli.KeepAlive(context.TODO(), lease.ID)
go func() {
for range keepAlive {
// 续约成功
}
}()
}
5、Lease 的应用场景
(1)服务注册与发现
- 注册服务:服务启动时创建 Lease 并绑定自身地址(如 /services/web/10.1.1.1:8080)。
- 心跳保活:通过自动续约维持 Lease 有效期,若服务崩溃,地址自动过期删除。
- 示例:Kubernetes 的 Node 心跳机制。
(2)分布式锁
- 锁获取:创建临时键(如 /lock/resource1)并绑定 Lease。
- 自动释放:若客户端崩溃,锁因 Lease 过期自动释放,避免死锁。
(3)临时配置项
- 动态配置:临时配置(如会话令牌)绑定 Lease,确保不用时自动清理。
6、Lease 的注意事项
(1)TTL 设置
- 最小值:ETCD 要求 TTL ≥ 1秒(通过参数 --min-lease-ttl 可调整)。
- 合理值:根据网络延迟和业务需求设置,避免因续约不及时导致误删。
(2)性能影响
- 内存开销:每个 Lease 在内存中占用约 100字节,大规模使用需监控内存。
- 续约频率:高频续约会增加 Leader 负载,建议 TTL ≥ 5秒。
(3)一致性与容错
- Leader 切换:Lease 信息通过 Raft 日志复制,新 Leader 会继承所有 Lease 状态。
- 时钟同步:依赖节点间时钟大致同步(误差应远小于 TTL)。
7、Lease 的底层实现细节
(1)Lease 存储结构
- 内存数据结构:
type Lease struct { ID int64 // Lease ID TTL int64 // 初始 TTL(秒) Expiry time.Time // 到期时间 KeyToHash map[string]struct{}// 绑定的键(哈希集合) } - 持久化信息:键值对的元数据中记录 Lease ID,存储于 BoltDB。
(2)过期键删除流程
- 检测过期 Lease:Leader 定期扫描 Lease 最小堆。
- 生成删除操作:将绑定的键加入待删除队列。
- 提交 Raft 日志:通过 Raft 协议同步删除操作到所有节点。
- 应用删除:各节点从 BoltDB 中删除键,并清理内存中的 Lease 信息。
(3)续约的 Raft 流程
- 客户端发送续约请求到 Leader。
- Leader 更新内存中 Lease 的 Expiry 时间。
- 生成 LeaseKeepAlive 日志条目,通过 Raft 同步到多数节点。
- Follower 应用日志,更新本地 Lease 的到期时间。
8、Lease 的监控与调试
(1)关键监控指标
| 指标名称 | 说明 | 健康阈值 |
|---|---|---|
| etcd_server_lease_expired_total | 已过期的 Lease 总数 | 突增可能表示客户端异常 |
| etcd_server_lease_renewed_total | 续约次数 | 反映客户端活跃度 |
| etcd_server_lease_ttl_buckets | Lease TTL 分布直方图 | 检查 TTL 设置是否合理 |
(2)调试命令
- 查看所有 Lease:
etcdctl lease list
- 检查特定 Lease 的详细信息:
etcdctl lease timetolive <LEASE_ID> --keys
十、mvcc
十一、etcd事务
分布式系统领域,etcd 事务是保障数据一致性的核心机制。
1、事务模型本质
etcd的事务是基于乐观锁实现的,它的事务调用方式是经典的CAS,不支持回滚,即要么全部成功要么全部失败。
- 原子性三阶段模型:Compare-If / Then-Else 结构形成原子操作单元,请求中携带的多个条件会进行全真判断
- 版本驱动机制:基于 revision 的 MVCC 控制,每个键值对携带 create_revision/mod_revision 等元数据
2、事务执行流程
语法:
Txn().If(cond1, cond2, ...).Then(op1, op2, ...,).Else(op1, op2)
Txn(): 开始一个事务If(cond1, cond2, ...): 定义事务的提交条件。这些条件通常是关于某个 key 的比较操作,例如检查 key 是否存在,或者当前的值是否等于预期的值。Then(op1, op2, ...): 如果所有条件都满足,那么就执行这里的操作。操作可以是 put、delete 或者 get 等。Else(op1, op2): 如果条件不满足,那么就执行这里的操作。
示例:
client.Txn(ctx).If(
clientv3.Compare(clientv3.Value("/registry/pods/nginx"), "=", "v1"),
clientv3.Compare(clientv3.Version("/registry/locks"), "=", 2)
).Then(
clientv3.OpPut("/registry/config", "updated"),
clientv3.OpDelete("/registry/temp")
).Else(
clientv3.OpGet("/registry/status")
).Commit()
▶ 服务端执行阶段:
- 内存锁保护事务执行过程
- 遍历比较树进行全量条件验证
- 生成事务执行计划(then/else 分支)
- Raft 日志提交与状态机应用
3、stm
为了简化 etcd 事务实现的过程,etcd v3 提供了 STM,会自动处理冲突以及重试。
// STM is an interface for software transactional memory.
type STM interface {
// Get returns the value for a key and inserts the key in the txn's read set.
// If Get fails, it aborts the transaction with an error, never returning.
Get(key ...string) string
// Put adds a value for a key to the write set.
Put(key, val string, opts ...v3.OpOption)
// Rev returns the revision of a key in the read set.
Rev(key string) int64
// Del deletes a key.
Del(key string)
// commit attempts to apply the txn's changes to the server.
commit() *v3.TxnResponse
reset()
}
stm后两个级别第一次都是是线性读,后面才是串行读。
每次读写请求都会创建事务,只有写事务会导致全局的事务版本号增加,串行读不会导致版本号增加。
stm的事务隔离级别,分为四种:
- ReadCommitted: 读已提交隔离级别,不作任何检查,每次的Get请求都是串行读,也就是不用raft集群同步,直接返回结果的读,所以每次get结果版本号可能不一致。读已提交能接受读过的key发生变化。
- RepeatableReads :可重复读隔离级别,会缓存所有读过的key,提交时会检查所有的读过key版本是否发生过变化,所有的读都是串行读。可重复读不能接受读过的key发生变化。
- Serializable : 串行化隔离级别,因为第一次是线性读,会经过raft集群同步,第一个get获取到事务的版本号,后面的获取都会带上对应的版本号(带上版本号的读只有读到这个版本号之前的数据),同时会检查对应的读过key版本是否发生变化。串行化隔离级别只能读到这个事务开启之前和这个事务过程中更新的key的数据,且读到的key在事务提交时不能发生变化。
- SerializableSnapshot:串行化快照隔离级别,会同时检查所有的读key版本是否发生过变化和检查写的key的版本是不是事务开始的版本+1,即在事务期间要求写的key没有被修改过。串行化快照隔离级别只能读到这个事务开启之前和这个事务过程中更新的key的数据,读到的key在事务提交时不能发生变化,要写的key没有被更后的事务修改过。
Serializable和SerializableSnapshot 一个对读进行检查,一个对读写都进行检查。
上面的检查不通过,会进行重试,直到通过为止。
stm的读请求都是一次事务,写请求是放在一起进行提交的。
func (s *stm) Get(keys ...string) string {
if wv := s.wset.get(keys...); wv != nil {
return wv.val
}
return respToValue(s.fetch(keys...))
}
func (ws writeSet) get(keys ...string) *stmPut {
for _, key := range keys {
if wv, ok := ws[key]; ok {
return &wv
}
}
return nil
}
func (s *stm) fetch(keys ...string) *v3.GetResponse {
if len(keys) == 0 {
return nil
}
ops := make([]v3.Op, len(keys))
for i, key := range keys {
if resp, ok := s.rset[key]; ok {
return resp
}
ops[i] = v3.OpGet(key, s.getOpts...)
}
txnresp, err := s.client.Txn(s.ctx).Then(ops...).Commit()
if err != nil {
panic(stmError{err})
}
s.rset.add(keys, txnresp)
return (*v3.GetResponse)(txnresp.Responses[0].GetResponseRange())
}
func (s *stm) commit() *v3.TxnResponse {
txnresp, err := s.client.Txn(s.ctx).If(s.conflicts()...).Then(s.wset.puts()...).Commit()
if err != nil {
panic(stmError{err})
}
if txnresp.Succeeded {
return txnresp
}
return nil
}
4、高级事务模式
- 乐观锁模式:通过 mod_revision 实现 CAS 操作
- 复合事务:单事务内混合多种操作类型(Put/Get/Delete)
- 租约事务:绑定 leaseID 实现自动过期控制
- 大事务优化:使用事务分片 + 异步提交处理批量操作
5、性能优化策略
条件索引优化:优先使用版本比较而非值比较
操作合并技巧:将多个 key 更新合并到单个事务
事务大小控制:建议单个事务不超过 1MB 数据量
线性读优化:通过 quorum read 提升读性能
6、典型异常处理
# 事务冲突检测
ERROR: rpc error: code = Aborted desc = etcdserver: request timed out
# 处理建议:
1. 指数退避重试策略
2. 事务拆分(将非必要操作移出事务)
3. 增加 etcd 集群时钟同步精度
4. 监控 metrics: etcd_server_slow_apply_total
5. 内核级增强特性
7、内核级增强特性
- 并行事务处理:基于 boltDB 的 bucket 分片锁
- 事务压缩:通过定期 compaction 回收历史版本
- watch 事务集成:通过 PostTransactionHook 触发事件
etcd 事务机制深度集成了 Raft 共识算法与 MVCC 存储模型,在 Kubernetes 等云原生系统中实现了以下关键功能:
- 服务发现元数据的原子更新
- 配置信息的版本化回滚
- 分布式锁服务的精准控制
- 集群状态的一致性快照
建议在生产环境中结合 etcdctl 的 txn 命令进行事务调试,并通过 grafana 监控 etcd_txn_total 等关键指标,实现事务性能的持续优化。
十、wal
十、backend
十、数据库引擎boltdb
十九、etcd 应用场景
1、服务发现
服务发现(Service Discovery)要解决的是分布式系统中最常见的问题之一,即在同一个分布式集群中的进程或服务如何才能找到对方并建立连接。从本质上说,服务发现就是想要了解集群中是否有进程在监听udp或tcp端口,并且通过名字就可以进行查找和连接。
要解决服务发现的问题,需要有下面三大支柱,缺一不可。
- 一个强一致性、高可用的服务存储目录。基于Raft算法的etcd天生就是这样一个强一致性高可用的服务存储目录。
- 一种注册服务和监控服务健康状态的机制。用户可以在etcd中注册服务,并且对注册的服务设置key TTL,定时保持服务的心跳以达到监控健康状态的效果。
- 一种查找和连接服务的机制。通过在etcd指定的主题下注册的服务也能在对应的主题下查找到。为了确保连接,我们可以在每个服务机器上都部署一个proxy模式的etcd,这样就可以确保能访问etcd集群的服务都能互相连接。
2、消息发布与订阅
在分布式系统中,最为适用的组件间通信方式是消息发布与订阅机制。具体而言,即构建一个配置共享中心,数据提供者在这个配置中心发布消息,而消息使用者则订阅他们关心的主题,一旦相关主题有消息发布,就会实时通知订阅者。通过这种方式可以实现分布式系统配置的集中式管理与实时动态更新。
- 应用中用到的一些配置信息存放在etcd上进行集中管理。这类场景的使用方式通常是这样的:应用在启动的时候主动从etcd获取一次配置信息,同时,在etcd节点上注册一个Watcher并等待,以后每次配置有更新的时候,etcd都会实时通知订阅者,以此达到获取最新配置信息的目的。
- 分布式搜索服务中,索引的元信息和服务器集群机器的节点状态信息存放在etcd中,供各个客户端订阅使用。使用etcd的key TTL功能可以确保机器状态是实时更新的。
- 分布式日志收集系统。这个系统的核心工作是收集分布在不同机器上的日志。收集器通常按照应用(或主题)来分配收集任务单元,因此可以在etcd上创建一个以应用(或主题)命名的目录P,并将这个应用(或主题)相关的所有机器ip,以子目录的形式存储在目录P下,然后设置一个递归的etcd Watcher,递归式地监控应用(或主题)目录下所有信息的变动。这样就实现了在机器IP(消息)发生变动时,能够实时通知收集器调整任务分配。
- 系统中信息需要动态自动获取与人工干预修改信息请求内容的情况。通常的解决方案是对外暴露接口,例如JMX接口,来获取一些运行时的信息或提交修改的请求。而引入etcd之后,只需要将这些信息存放到指定的etcd目录中,即可通过HTTP接口直接被外部访问。
3、负载均衡
在分布式系统中,为了保证服务的高可用以及数据的一致性,通常都会把数据和服务部署多份,以此达到对等服务,即使其中的某一个服务失效了,也不影响使用。这样的实现虽然会导致一定程度上数据写入性能的下降,但是却能实现数据访问时的负载均衡。因为每个对等服务节点上都存有完整的数据,所以用户的访问流量就可以分流到不同的机器上。
- etcd本身分布式架构存储的信息访问支持负载均衡。etcd集群化以后,每个etcd的核心节点都可以处理用户的请求。所以,把数据量小但是访问频繁的消息数据直接存储到etcd中也是个不错的选择,如业务系统中常用的二级代码表。二级代码表的工作过程一般是这样,在表中存储代码,在etcd中存储代码所代表的具体含义,业务系统调用查表的过程,就需要查找表中代码的含义。所以如果把二级代码表中的小量数据存储到etcd中,不仅方便修改,也易于大量访问。
- 利用etcd维护一个负载均衡节点表。etcd可以监控一个集群中多个节点的状态,当有一个请求发过来后,可以轮询式地把请求转发给存活着的多个节点。类似KafkaMQ,通过Zookeeper来维护生产者和消费者的负载均衡。同样也可以用etcd来做Zookeeper的工作。
4、分布式通知与协调
不同系统都在etcd上对同一个目录进行注册,同时设置Watcher监控该目录的变化(如果对子目录的变化也有需要,可以设置成递归模式),当某个系统更新了etcd的目录,那么设置了Watcher的系统就会收到通知,并作出相应处理。
- 通过etcd进行低耦合的心跳检测。检测系统和被检测系统通过etcd上某个目录关联而非直接关联起来,这样可以大大减少系统的耦合性。
- 通过etcd完成系统调度。某系统有控制台和推送系统两部分组成,控制台的职责是控制推送系统进行相应的推送工作。管理人员在控制台做的一些操作,实际上只需要修改etcd上某些目录节点的状态,而etcd就会自动把这些变化通知给注册了Watcher的推送系统客户端,推送系统再做出相应的推送任务。
- 通过etcd完成工作汇报。大部分类似的任务分发系统,子任务启动后,到etcd来注册一个临时工作目录,并且定时将自己的进度进行汇报(将进度写入到这个临时目录),这样任务管理者就能够实时知道任务进度。
5、分布式锁
因为etcd使用Raft算法保持了数据的强一致性,某次操作存储到集群中的值必然是全局一致的,所以很容易实现分布式锁。锁服务有两种使用方式,一是保持独占,二是控制时序。
- 保持独占,即所有试图获取锁的用户最终只有一个可以得到。etcd为此提供了一套实现分布式锁原子操作CAS(CompareAndSwap)的API。通过设置prevExist值,可以保证在多个节点同时创建某个目录时,只有一个成功,而该用户即可认为是获得了锁。
- 控制时序,即所有试图获取锁的用户都会进入等待队列,获得锁的顺序是全局唯一的,同时决定了队列执行顺序。etcd为此也提供了一套API(自动创建有序键),对一个目录建值时指定为POST动作,这样etcd会自动在目录下生成一个当前最大的值为键,存储这个新的值(客户端编号)。同时还可以使用API按顺序列出所有当前目录下的键值。此时这些键的值就是客户端的时序,而这些键中存储的值可以是代表客户端的编号。
6、分布式队列
分布式队列的常规用法与场景五中所描述的分布式锁的控制时序用法类似,即创建一个先进先出的队列,保证顺序。
另一种比较有意思的实现是在保证队列达到某个条件时再统一按顺序执行。这种方法的实现可以在/queue这个目录中另外建立一个/queue/condition节点。
- condition可以表示队列大小。比如一个大的任务需要很多小任务就绪的情况下才能执行,每次有一个小任务就绪,就给这个condition数字加1,直到达到大任务规定的数字,再开始执行队列里的一系列小任务,最终执行大任务。
- condition可以表示某个任务在不在队列。这个任务可以是所有排序任务的首个执行程序,也可以是拓扑结构中没有依赖的点。通常,必须执行这些任务后才能执行队列中的其他任务。
- condition还可以表示其它的一类开始执行任务的通知。可以由控制程序指定,当condition出现变化时,开始执行队列任务。
7、集群监控与LEADER竞选
通过etcd来进行监控实现起来非常简单并且实时性强,用到了以下两点特性。
前面几个场景已经提到Watcher机制,当某个节点消失或有变动时,Watcher会第一时间发现并告知用户。。
节点可以设置TTL key,比如每隔30s向etcd发送一次心跳使代表该节点仍然存活,否则说明节点消失。
这样就可以第一时间检测到各节点的健康状态,以完成集群的监控要求。
另外,使用分布式锁,可以完成Leader竞选。对于一些长时间CPU计算或者使用IO操作,只需要由竞选出的Leader计算或处理一次,再把结果复制给其他Follower即可,从而避免重复劳动,节省计算资源。
Leader应用的经典场景是在搜索系统中建立全量索引。如果每个机器分别进行索引的建立,不但耗时,而且不能保证索引的一致性。通过在etcd的CAS机制竞选Leader,由Leader进行索引计算,再将计算结果分发到其它节点。
8、为什么用ETCD而不用ZOOKEEPER?
etcd实现的这些功能,Zookeeper都能实现。那么为什么要用etcd而非直接使用Zookeeper呢?
Zookeeper 缺点:
- 复杂。Zookeeper的部署维护复杂,管理员需要掌握一系列的知识和技能;而Paxos强一致性算法也是素来以复杂难懂而闻名于世;另外,Zookeeper的使用也比较复杂,需要安装客户端,官方只提供了java和C两种语言的接口。
- Java编写。Java本身就偏向于重型应用,它会引入大量的依赖。而运维人员则普遍希望机器集群尽可能简单,维护起来也不易出错。
- 发展缓慢。Apache基金会项目特有的“Apache Way”在开源界饱受争议,其中一大原因就是由于基金会庞大的结构以及松散的管理导致项目发展缓慢。
etcd 优点:
- 简单。使用Go语言编写部署简单;使用HTTP作为接口使用简单;使用Raft算法保证强一致性让用户易于理解。
- 数据持久化。etcd默认数据一更新就进行持久化。
- 安全。etcd支持SSL客户端安全认证。
二十、资料
- ECTD 官方文档
- ETCD 简介 + 使用
- 彻底搞懂 etcd 系列文章(三):etcd 集群运维部署
- 深入理解etcd(三)— etcd 的架构是怎么样的?