利用netfilter抓包(一)----------netfilter介绍
Netfilter是Linux 2.4.x引入的一个子系统,它作为一个通用的、抽象的框架,提供一整套的hook函数的管理机制,使得诸如数据包过滤、网络地址转换(NAT)和基于协议类型的连接跟踪成为了可能。
Netfilter在内核中位置如下图所示:
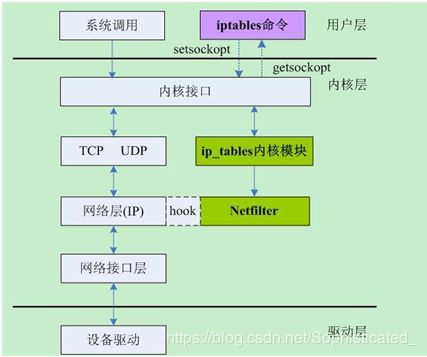
netfilter的架构就是在整个网络流程的若干位置放置了一些检测点(HOOK),而在每个检测点上登记了一些处理函数进行处理。
IP层的五个HOOK点的位置如下图所示
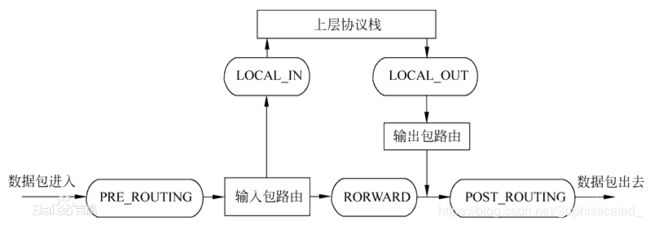
[1] NF_IP_PRE_ROUTING:刚刚进入网络层的数据包通过此点(刚刚进行完版本号,校验
和等检测), 目的地址转换在此点进行;
[2] NF_IP_LOCAL_IN:经路由查找后,送往本机的通过此检查点,INPUT包过滤在此点进行;
[3] NF_IP_FORWARD:要转发的包通过此检测点,FORWARD包过滤在此点进行;
[4] NF_IP_POST_ROUTING:所有马上便要通过网络设备出去的包通过此检测点,内置的源地址转换功能(包括地址伪装)在此点进行;
[5] NF_IP_LOCAL_OUT:本机进程发出的包通过此检测点,OUTPUT包过滤在此点进行。
在每个hook点上,有很多已经按照优先级预先注册了的回调函数(称为“钩子函数”)埋伏在这些关键点,形成了一条链。对于每个到来的数据包会依次被那些回调函数“调戏”一番再视情况是将其放行,丢弃还是怎么滴。但是无论如何,这些回调函数最后必须向Netfilter报告一下该数据包的死活情况,因为毕竟每个数据包都是Netfilter从人家协议栈那儿借调过来给兄弟们Happy的,别个再怎么滴也总得“活要见人,死要见尸”吧。每个钩子函数最后必须向Netfilter框架返回下列几个值其中之一:
NF_ACCEPT继续正常传输数据报。这个返回值告诉Netfilter:到目前为止,该数据包还是被接受的并且该数据包应当被递交到网络协议栈的下一个阶段。NF_DROP丢弃该数据报,不再传输。NF_STOLEN模块接管该数据报,告诉Netfilter“忘掉”该数据报。该回调函数将从此开始对数据包的处理,并且Netfilter应当放弃对该数据包做任何的处理。但是,这并不意味着该数据包的资源已经被释放。这个数据包以及它独自的sk_buff数据结构仍然有效,只是回调函数从Netfilter获取了该数据包的所有权。NF_QUEUE对该数据报进行排队(通常用于将数据报给用户空间的进程进行处理)NF_REPEAT再次调用该回调函数,应当谨慎使用这个值,以免造成死循环。
调用NF_HOOK宏进入对应的钩子点
static inline int NF_HOOK(uint8_t pf,
unsigned int hook,
struct net *net,
struct sock *sk,
struct sk_buff *skb,
struct net_device *in, struct net_device *out,
int (*okfn)(struct net *, struct sock *, struct sk_buff *))
NF_HOOK宏的参数分别为:
pf:协议族名,netfilter架构同样可以用于IP层之外,因此这个变量还可以有诸如PF_INET6,PF_DECnet等名字。
hook:HOOK点的名字,对于IP层,就是取上面的五个值;
net: 网络命名空间,默认&init_net;
skb:网络设备数据缓存区;
indev:进来的设备,以struct net_device结构表示;
outdev:出去的设备,以struct net_device结构表示;(后面可以看到,以上五个参数将传到用nf_register_hook登记的处理函数中。)
okfn:是个函数指针,当所有的该HOOK点的所有登记函数调用完后,转而走此流程。这些点是已经在内核中定义好的,除非你是这部分内核代码的维护者,否则无权增加或修改,而在此检测点进行的处理,则可由用户指定。像packet filter,NAT,connectiontrack这些功能,也是以这种方式提供的。正如netfilter的当初的设计目标,提供一个完善灵活的框架,为扩展功能提供方便。
如果我们想加入自己的代码,便要用nf_register_hook函数,其函数原型为:
int nf_register_hook(struct nf_hook_ops *reg)
void nf_register_net_hook(struct net *net, const struct nf_hook_ops *reg)
新版内核的钩子函数注册方法,增加了网络命名空间,默认可以使用&init_net
nf_hook_ops的结构体定义:
struct nf_hook_ops {
/* User fills in from here down. */
nf_hookfn *hook;
struct net_device *dev;
void *priv;
u_int8_t pf;
unsigned int hooknum;
/* Hooks are ordered in ascending priority. */
int priority;
};
hook:即为要注册的钩子处理函数
dev:网络设备
pf:协议簇,对于ipv4而言,是PF_INET
hooknum:要注册的钩子点,linux 网络协议栈中包含5个hook
priority:优先级,越小优先级越高
nf_hookfn钩子函数原型
typedef unsigned int nf_hookfn(void *priv,
struct sk_buff *skb,
const struct nf_hook_state *state);
nf_hook_state结构体定义
struct nf_hook_state {
unsigned int hook;
u_int8_t pf;
struct net_device *in;
struct net_device *out;
struct sock *sk;
struct net *net;
int (*okfn)(struct net *, struct sock *, struct sk_buff *);
};
在数据包流经内核协议栈的整个过程中,在一些已预定义的hook点上PRE_ROUTING、LOCAL_IN、FORWARD、LOCAL_OUT和POST_ROUTING会根据数据包的协议簇PF_INET到这些关键点去查找是否注册有钩子函数。如果没有,则直接返回okfn函数指针所指向的函数继续走协议栈;如果有,则调用nf_hook_slow函数,从而进入到Netfilter框架中去进一步调用已注册在该过滤点下的钩子函数,再根据其返回值来确定是否继续执行由函数指针okfn所指向的函数。