云开发数据库重构:如何将字段抽离成单独的集合
关于作者
Eric KK

曾供职于云盾、简书,资深前端工程师,we-plugin开源项目组成员,现任潮办科技CTO,基于腾讯云开发转型全栈开发者,独立完成多个微信小程序从0到1全功能完整上线运行。
“使用云开发之后,一个小程序可以快速的从无到有上线运行,这个速度是传统开发不能比的,特别适合初创团队快速上线产品抢占市场或试错。而使用云开发,我们通常要做的第一件事就是设计数据库,云开发的数据库使用结构化的文档来存储数据,不再是关系型数据库里每个行列交汇处都必须有且只有一个值,它可以是一个数组、一个对象,或者更加复杂的嵌套。
在初期产品需要快速出可用原型,上线时间紧迫的情况下,数据库设计难免会有欠考虑的地方,等产品开始进入迭代期就可能会有重构需求。团队最近对项目进行了重构,写一篇文章分享我们在做重构的一些心得。”
目的
这次数据库重构只有一个目的,把一个最初内嵌的字段提取出来,单独创建一个集合来管理。也就是把反范式化设计的数据库结构转成范式化的设计。
关于范式化和反范式化,你可以看云开发布道师东哥的文章:
https://club.cloudbase.net/handbook/tcb/1203.html
旧数据方案的痛点
在产品上线的第一个版本时,bagList字段是内嵌在一个user文档里的,如下:
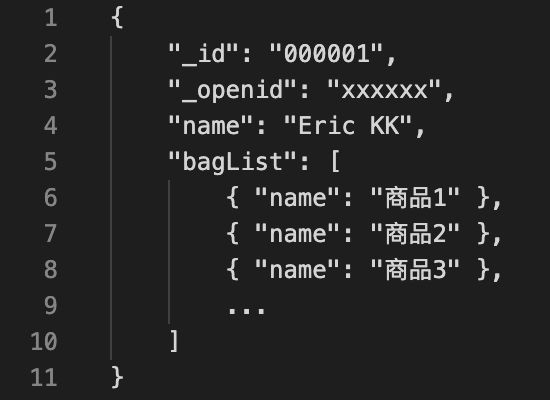
这里的数据是精简版,真实情况还会有很多商品信息、用户信息等,此处只是举例说明。
这样的反范式化设计在最初上线的版本中并没有什么问题,因为商品价格较高,早期也认为用户并不会大量购买。然而没想到的是,在经过一波运营宣传后,用户量开始猛增,其中也出现了一些土豪用户,他们的购买数量已经不是个位数了,有的都超过了100件以上,此时bagList字段的数组长度就变得非常大。
在这个时候,数据分页、商品发货、修改商品信息就已经很难维护,一直使用了层层的聚合操作先查询出来,然后再修改。犹豫不决之际,新的开发需求出现,要求可以让用户之前互换数据,原有的数据结构想要实现类似的功能存在较高的实现成本。因此,决定干脆重构数据库,提升开发效率。
重构步骤
将 bagList 字段单独拿出来形成一个集合的好处有很多,数据分页很方便,修改商品信息很简单,且很多云数据库的原子操作修改都可以直接使用,更重要的是新需求互换功能只需要修改对应商品的所有者 userid 就可以完成。但此时内嵌结构已经使用了很久,数据也已经记录了很多,如何把这些历史数据无缝衔接的拿出来成了问题,这里使用了一系列的聚合操作来完成。

这里用的是云开发管理控制台自带的高级操作脚本,首先第一步开启聚合模式,在聚合中单次limit最大数现为10000,因改版时用户数正好低于10000,所以这里直接拉到最大。然后使用match来删选user集合中bagList字段不为空数组的文档。紧接着使用project选定在下一阶段想要的展示的字段,_id字段默认存在,其余字段直接舍弃。此时的执行结果如下图:
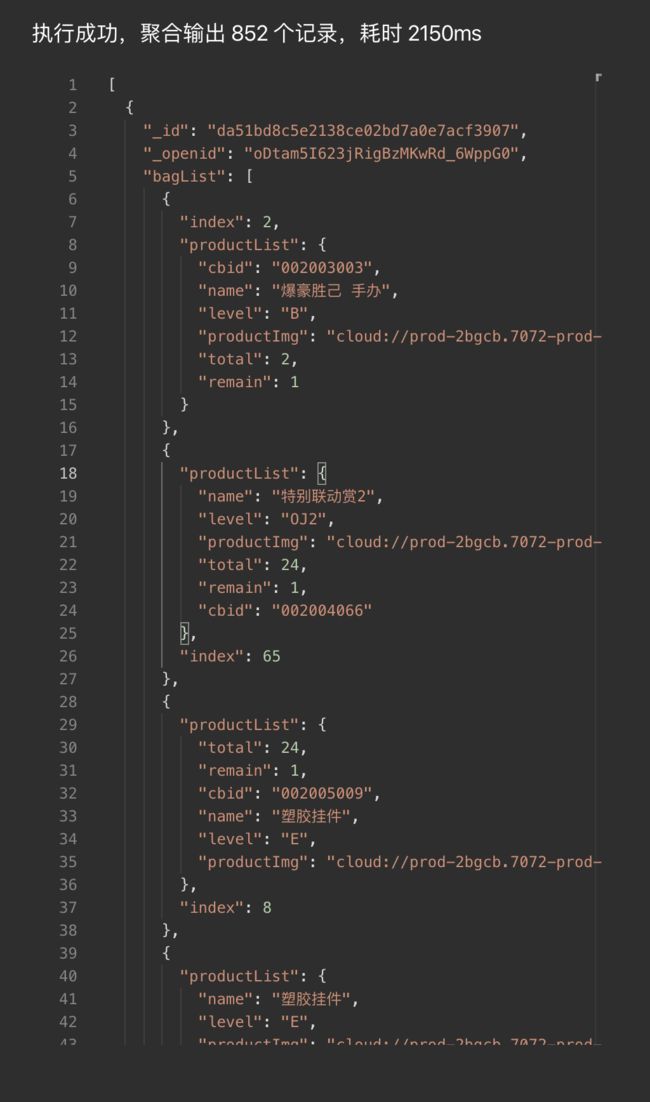
接下来我们就需要用unwind来拆分bagList,拆分完的数据结构如下:
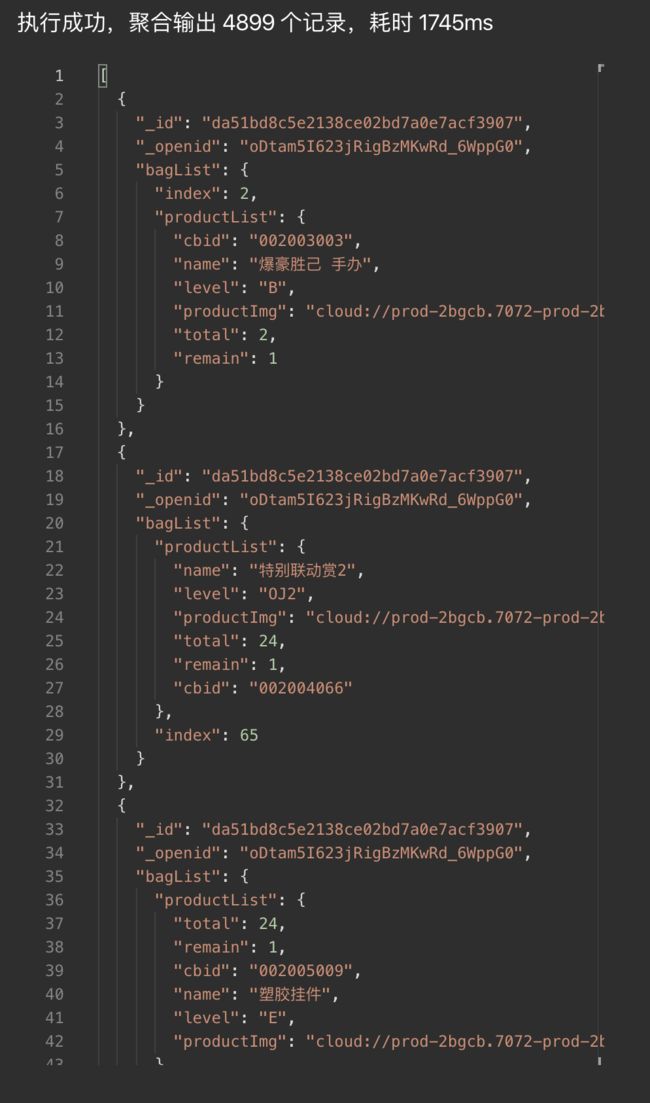
此时每一个商品已经单独抽离出来,如果此时的结构已经达到了想要的要求,那就可以直接使用现有数据,如果还想自定义一下,那就可以继续使用聚合操作来完成,如上面我因为还有其他需求,使用聚合再次改变了一些结构写法,聚合的操作可以去云开发文档聚合学习。
不过,聚合出来的数据并不是严格的json数据,虽然现在的云开发控制台的高级脚本可以批量添加数据,add方法中的data可以为数组,这在数据量小的情况下可以直接使用,但我们这次聚合出来几千条数据,经测试,云开发的高级脚本并不支持那么大的数据量一次性导入,那么我们可以使用数据库的json格式导入。
创建一个新集合products,这里使用vscode把我们聚合出来的数据复制粘贴到一个名为products.json的新文件中(名称随意),然后将最外层的[]包裹删除,全局搜索 },换行{ 替换为 }换行{ ,把每条数据之间的逗号去除(注意:在搜索的时候,换行也要,不然内嵌数据的逗号也会被替换),保存并使用 json方式把数据导入到products集合就大功告成啦。
总结
在开发的过程中,难免会遇到需要重构数据库的场景,我自己没有搜索到相关的文档,便将自己的实践经验分享出来,做第一个吃螃蟹的人,供大家参考。
如果你对重构方面有任何问题和想法,欢迎留言和一起讨论。