如何使用深度学习识别 UI 界面组件?
导读:智能生成代码平台 imgcook 以 Sketch、PSD、静态图片等形式的视觉稿作为输入,可以一键生成可维护的前端代码,但从设计稿中获取的都是 div、img、span 等元件,而前端大多是组件化开发,我们希望能从设计稿直接生成组件化的代码,这就需要能够将设计稿中的组件化元素,例如 Searchbar、Button、Tab 等识别出来。识别网页中的 UI 元素在人工智能领域是一个典型的的目标检测问题,我们可以尝试使用深度学习目标检测手段来自动化解决。
本文介绍了使用机器学习的方式来识别 UI 界面元素的完整流程,包括:现状问题分析、算法选型、样本准备、模型训练、模型评估、模型服务开发与部署、模型应用等。
应用背景
imgcook 以 Sketch、PSD、静态图片等形式的视觉稿作为输入,通过智能化技术一键生成可维护的前端代码,Sketch/Photoshop 设计稿的代码生成需要安装插件,在设计稿中通过 imgcook 插件导出视觉稿的 JSON 描述信息(D2C Schema)粘贴到 imgcook 可视化编辑器,在编辑器中可以进行视图编辑、逻辑编辑等来改变 JSON 描述信息。
我们可以选择 DSL 规范来生成对应的代码。例如生成 React 规范的代码,需要实现从 JSON 树转换成 React 代码 (自定义 DSL)。

如下图,左侧为 Sketch 中的视觉稿, 右侧为使用 React 开发规范生成的按钮部分的代码。

从 Sketch 视觉稿「导出数据」生成「React 开发规范」的代码,图为按钮部分代码片段。
生成的代码都是由 div、img、span 这些标签组成,但实际应用开发有这样的问题:
web页面开发为提升可复用性,页面组件化,例如:Searchbar、Button、Tab、Switch、Stepper
一些原生组件不需要生成代码,例如状态栏 Statusbar、Navbar、Keyboard
我们的需求是,如果想要使用组件库,例如 Ant Design,我们希望生成的代码能像这样:
// Antd Mobile React 规范
import { Button } from "antd-mobile";
"smart": { "layerProtocol": { "component": { "type": "Button" } }}
为此我们在 JSON 描述中添加了 smart 字段, 用来描述节点的类型。
我们需要做的,就是找到视觉稿中需要组件化的元素,用这样的 JSON 信息来描述它, 以便在 DSL 转换代码时, 通过获取 JSON 信息中的 smart 字段来生成组件化代码。
现在问题转化为:如何找到视觉稿中需要组件化的元素,它是什么组件,它在 DOM 树中的位置或者在设计稿中的位置。
解决方案
▐ 约定生成规则
通过指定设计稿规范来干预生成的 JSON 描述,从而控制生成的代码结构。例如在我们的 设计稿高级干预规范 中关于组件的图层命名规范:将图层中的组件、组件属性等显性标记出来。
#component:组件名?属性=值##component:Button?id=btn#
在使用 imgcook 的插件导出 JSON 描述数据时就通过规范解析拿到图层中的约定信息。
▐ 学习识别组件
人工约定规则的方式需要按照我们制定的协议规范来修改设计稿,一个页面上的组件可能会有很多,这种人工约定方式让开发者多了很多额外工作,不符合使用 imgcook 提高开发效率的宗旨,我们期望通过智能化手段自动识别视觉稿中的可组件化元素,识别的结果最终会转换并填充在 smart 字段中,与手动约定组件协议所生成的 json 中的 smart 字段内容相同。
这里需要完成两件事情:
找到组件信息:类别、位置、尺寸等信息。
找到组件中的属性, 例如 button 中的文字为“提交”
第二个事情我们可以根据 json 树来解析组件的子元素。第一个事情我们可以通过智能化来自动化的完成,这是一个在人工智能领域典型的的目标检测问题,我们可以尝试使用深度学习目标检测手段来自动化解决这个手动约定的流程。
学习识别 UI 组件
▐ 业界现状
目前业界也有一些使用深度学习来识别网页中的 UI 元素的研究和应用,对此有一些讨论:
Use R-CNN to detect UI elements in a webpage?
Is machine learning suitable for detecting screen elements?
Any thoughts on a good way to detect UI elements in a webpage?
How can I detect elements of GUI using opencv?
How to recognize UI elements in image?
讨论中的诉求主要有两种:
期望通过识别 UI 界面元素来做 Web 页面自动化测试的应用场景。
期望通过识别 UI 界面元素来自动生成代码。
既然是使用深度学习来解决 UI 界面元素识别的问题, 带有元素信息的 UI 界面数据集则是必须的。目前业界开放且使用较多的数据集有 Rico 和 ReDraw。
ReDraw
一组 Android 屏幕截图,GUI 元数据和标注了 GUI 组件图像,包含 RadioButton、ProgressBar、Switch、Button、CheckBox 等 15 个分类,14,382 个 UI 界面图片和 191,300 个带有标签的GUI组件,该数据集经过处理之后使每个组件的数量达到 5000 个。关于该数据集的详细介绍可查看 The ReDraw Dataset。
这是用于训练和评估 ReDraw 论文中提到的 CNN 和 KNN 机器学习技术的数据集,该论文于 2018 年在IEEE Transactions on Software Engineering上发布。该论文提出了一种通过三个步骤来实现从 UI 转换为代码自动化完成的方法:
1、检测 Detection
先从设计稿中提取或使用 CV 技术提取 UI 界面元信息,例如边界框(位置、尺寸)。
2、分类 Classification
再使用大型软件仓库挖掘、自动动态分析得到 UI 界面中出现的组件,并用此数据作为 CNN 技术的数据集学习将提取出的元素分类为特定类型,例如 Radio、Progress Bar、Button 等。
3、组装 Assembly
最后使用 KNN 推导 UI 层次结构,例如纵向列表、横向 Slider。

在 ReDraw 系统中使用这种方法生成了 Android 代码。评估表明,ReDraw 的 GUI 组件分类平均精度达到 91%,并组装了原型应用程序,这些应用程序在视觉亲和力上紧密地反映了目标模型,同时展现了合理的代码结构。

Rico
迄今为止最大的移动 UI 数据集,创建目的是支持五类数据驱动的应用程序:设计搜索,UI布局生成,UI代码生成,用户交互建模和用户感知预测。 Rico 数据集包含 27 个类别、1 万多个应用程序和大约 7 万个屏幕截图。
该数据集在 2017 年第30届ACM年度用户界面软件和技术研讨会上对外开放(RICO: A Mobile App Dataset for Building Data-Driven Design Applications)。
此后有一些基于 Rico 数据集的研究和应用。例如: Learning Design Semantics for Mobile Apps, 该论文介绍了一种基于代码和视觉的方法给移动 UI 元素添加语义注释。根据 UI 屏幕截图和视图层次结构可自动识别出 25
UI组件类别,197 个文本按钮概念和 99 个图标类。

▐ 应用场景
这里列举一些基于以上数据集的研究和应用场景。
智能生成代码
Machine Learning-Based Prototyping of Graphical User Interfaces for Mobile Apps | ReDraw Dataset
智能生成布局
Neural Design Network: Graphic Layout Generation with Constraints | Rico Dataset
用户感知预测
Modeling Mobile Interface Tappability Using Crowdsourcing and Deep Learning | Rico Dataset
UI 自动化测试
A Deep Learning based Approach to Automated Android App Testing | Rico Dataset
▐ 问题定义
在上述介绍的基于 Redraw 数据集生成 Android 代码的应用中,我们了解了它的实现方案, 对于第 2 步需要使用大型软件仓库挖掘和自动动态分析技术来获取大量组件样本作为 CNN 算法的训练样本,以此来得到 UI 界面中存在的特定类型组件,例如 Progress Bar、Switch 等。
对于我们 imgcook 的应用场景,其本质问题也是需要找到 UI 界面中这种特定类型的组件信息:类别和边界框,我们可以把这个问题定义为一个目标检测的问题,使用深度学习对 UI 界面进行目标检测。那么我们的目标是什么?
检测目标就是 Progress Bar、Switch、Tab Bar 这些可在代码中组件化的页面元素。
UI 界面目标检测
▐ 基础知识
机器学习
人类是怎么学习的?通过给大脑输入一定的资料,经过学习总结得到知识和经验,有当类似的任务时可以根据已有的经验做出决定或行动。

机器学习(Machine Learning)的过程与人类学习的过程是很相似的。机器学习算法本质上就是获得一个 f(x) 函数表示的模型,如果输入一个样本 x 给 f(x) 得到的结果是一个类别,解决的就是一个分类问题,如果得到的是一个具体的数值那么解决的就是回归问题。

机器学习与人类学习的整体机制是一致的,有一点区别是人类的大脑只需要非常少的一些资料就可以归纳总结出适用性非常强的知识或者经验,例如我们只要见过几只猫或几只狗就能正确的分辨出猫和狗,但对于机器来说我们需要大量的学习资料,但机器能做到的是智能化不需要人类参与。
深度学习
深度学习(Deep Learning)是机器学习的分支,是一种试图使用包含复杂结构或由多重非线性变换构成的多个处理层对数据进行高层抽象的算法。
深度学习与传统机器学习的区别可以看这篇 Deep Learning vs. Machine Learning,有数据依赖性、硬件依赖、特征处理、问题解决方式、执行时间和可解释性这几个方面。
深度学习对数据量和硬件的要求很高且执行时间很长,深度学习与传统机器学习算法的主要不同在于对特征处理的方式。在传统机器学习用于现实任务时,描述样本的特征通常需要由人类专家来设计,这称为“特征工程”(Feature Engineering),而特征的好坏对泛化性能有至关重要的影响,要设计出好特征并非易事。深度学习可以通过特征学习技术分析数据自动产生好特征。
目标检测
机器学习有很多应用,例如:
计算机视觉(Computer Vision,CV) 用于车牌识别和面部识别等的应用。
信息检索 用于诸如搜索引擎的应用 - 包括文本搜索和图像搜索。
市场营销 针对自动电子邮件营销和目标群体识别等的应用。
医疗诊断 诸如癌症识别和异常检测等的应用。
自然语言处理(Natural Language Processing, NLP) 如情绪分析和照片标记等的应用。
目标检测(Object Detection)就是一种与计算机视觉和图像处理有关的计算机技术,用于检测数字图像和视频中特定类别的语义对象(例如人,动物物或汽车)。

而我们在 UI 界面上的目标是一些设计元素, 可以是原子粒度的 Icon、Image、Text、或是可组件化的 Searchbar、Tabbar 等。

▐ 算法选型
用于目标检测的方法通常分为基于机器学习的方法(传统目标检测方法)或基于深度学习的方法(深度学习目标检测方法),目标检测方法经历了从传统目标检测方法到深度学习目标检测方法的变迁:

传统目标检测方法
对于基于机器学习的方法 ,需要先使用以下方法之一来定义特征,然后使用诸如支持向量机(SVM)的技术进行分类。
基于 Haar 功能的 Viola–Jones 目标检测框架
尺度不变特征变换(SIFT)
定向梯度直方图(HOG)特征
深度学习目标检测方法
对于基于深度学习的方法,无需定义特征即可进行端到端目标检测,通常基于卷积神经网络(CNN)。基于深度学习的目标检测方法可分为 One-stage 和 Two-stage 两类,还有继承这两种类方法优点的 RefineDet 算法。
✎ One-stage
基于 One-stage 的目标检测算法直接通过主干网络给出类别和位置信息,没有使用RPN网路。这样的算法速度更快,但是精度相对Two-stage目标检测网络了略低。典型算法有:
SSD(Single Shot MultiBox Detector)系列
YOLO (You Only Look Once)系列(YOLOv1、YOLOv2、YOLOv3)
RetinaNet
✎ Two-stage
基于 Two-stage 的目标检测算法主要通过一个卷积神经网络来完成目标检测过程,其提取的是 CNN 卷积特征,在训练网络时,其主要训练两个部分,第一步是训练 RPN 网络,第二步是训练目标区域检测的网络。
即先由算法生成一系列作为样本的候选框,再通过卷积神经网络进行样本分类。网络的准确度高、速度相对 One-stage 慢。典型算法有:
R-CNN,Fast R-CNN,Faster R-CNN
✎ 其他(RefineDet)
RefineDet (Single-Shot Refinement Neural Network for Object Detection) 是基于SSD算法的改进。继承了两种方法(例如,单一阶段设计方法,两阶段设计方法)的优点,并克服了它们的缺点。
目标检测方法对比
✎ 传统方法 VS 深度学习
基于机器学习的方法和基于深度学习的方法的算法流程如图所示,传统目标检测方法需要手动设计特征,通过滑动窗口获取候选框,再使用传统分类器进行目标区域判定,整个训练过程分成多个步骤。而深度学习目标检测方法则通过机器学习特征,通过更高效的 Proposal 或直接回归的方式获取候选目标,它的准确度和实时性更好。
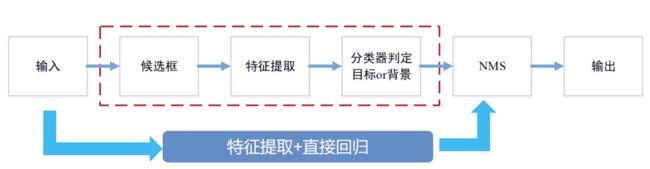
关于目标检测算法的研究现在基本都是基于深度学习的,传统的目标检测算法已经很少用到了,深度学习目标检测方法更适合工程化, 具体对比如下:

✎ One-stage VS Two-stage

✎ 算法优缺点
这里就不写各个算法的原理了,直接看下优缺点。

总结
由于对 UI 界面元素检测的精度要求比较高, 所以最终选择 Faster RCNN 算法。
▐ 框架选择
机器学习框架
这里简要列举下几个机器学习框架:Scikit Learn、TensorFlow、Pytorch、Keras。
Scikit Learn 是通用的机器学习框架,内部实现了各种分类,回归和聚类算法(包括支持向量机,随机森林,梯度增强,k-means 等); 还包括数据降维、模型选择和数据预处理等工具库,容易安装和使用,样例丰富,而且教程和文档也非常详细。
TensorFlow、Keras 和 Pytorch 是目前深度学习的主要框架, 提供各种深度学习算法调用。这里推荐个学习资源: 强烈推荐的TensorFlow、Pytorch和Keras的样例资源,特别同意这篇作者说的: 只要把以上资源运行一次,不懂的地方查官方文档,很快就能理解和运用这三大框架。
在后面的模型训练代码中可以看到实际任务中是怎么使用这些框架的。
目标检测框架
目标检测框架可以理解成是把目标检测算法整合在一起的一个库,例如深度学习算法框架 TensorFlow 不是一个目标检测框架,但它提供目标检测的 API:Object Detection API。
目标检测框架主要有:Detecn-benchmark、mmdetection、Detectron2。目前使用较广的是
Facebook AI 研究院于 2019 年 10 月 10 日开源的 Detectron2 目标检测框架。我们做 UI 界面组件识别也是用的 Detectron2, 后面会有使用示例代码。tron、maskrcn
可参考:如何评价FAIR于2019年10月10日开源的Detectron2目标检测框架?
前端机器学习框架 Pipcook
作为一个前端开发者,我们还可以选择 Pipcook,这是由阿里巴巴前端委员会智能化小组开源的一个帮助前端工程师使用机器学习的前端算法工程框架。
Pipcook 使用对前端友好的 JS 环境,基于 Tensorflow.js 框架作为底层算法能力并且针对前端业务场景包装了相应算法,从而让前端工程师可以快速简单的运用起机器学习的能力。
Pipcook 是基于管道的框架,为前端开发者封装了数据收集、数据接入、数据处理、模型配置、模型训练、模型服务部署、在线训练七个部分的机器学习工程链路。
关于 Pipcook 的原理和使用可查看:
Pipcook Github | Docs
pipcook - 让前端拥抱智能化的一站式算法框架
怎样基于 tfjs-node 构建一个高阶前端机器学习框架
▐ 样本准备
环境和模型准备好了,机器学习的大头还是数据集的收集和处理。我们的样本来源有两种:
阿里系应用的 UI 界面图片。目前移动端 UI 界面 25647 张图片,人工标注了 10 个分类共计 49120 个组件。
代码自动生成的图片。支持 10 个分类的样本生成,生成图片时自动标注。
组件类型定义
目前圈定的组件类型有 Statusbar、Navbar、Searchbar、Tabbar 等,不管是人工标注还是自动标注目标组件,都需要有明确的组件类型定义。
人工标注时需要根据明确定义的特征来标注组件
自动生成时需要根据明确定义的特征来编写样式代码。
例如,对手机状态栏 Status Bar 的定义:

例如,对选项卡 Tab Bar 的定义:

阿里系应用 UI 界面样本
阿里系 APP 和产品业务有很多,这个业务的视觉稿都有平台集中管理,我们可以拿到这些视觉稿作为样本来源。目前只选取了 Sketch 视觉稿, 因为 PSD 文件难以导出以页面为维度的图片。
收集样本
这里讲的比较细,因为我觉得有些地方可以还是给人启示的。
✎ 下载 Sketch 文件
从阿里内部平台下载 Sketch 文件是第一步,后面的每个步骤脚本都以序号开头,例如 1-download-sketch.ts。因为样本处理脚本很多,友好的命名更易理解。
/** * 【用途】下载 Sketch 文件 * 【命令】ts-node 1-download-sketch.ts */
✎ 使用 sketchtool 批量导出为图片
Sketch 自带一个命令行工具 sketchtool, 我们可以用 sketchtool 来批量导出为图片。点此查看更多 sketchtool 的用法。
# 【用途】使用 sketchtool 导出 Sketch 中的 Artboards 保存为 1x 的 png 图片# 【命令】sh 2-export-image-from-sketch.sh $inputDir $outputDir
for file in $1"/*"do sketchtool export artboards $file --output=$2 --formats='png' --scales=1.0done
样本预处理
设计师出的设计稿你懂得,淘宝直播4.0_v1、淘宝直播4.0_v2、淘宝直播4.0_v3..., 每个小版本改动可能不太大,每个 Sketch 文件中的页面可能还有:详情页初版、详情页2版、详情页终版,这在导出图片之后会有大量重复的图片。
另外还有一些不规范的设计稿,一个画板画一个 ICON 这种的,还有交互稿、PC 端视觉稿等都不是我们需要的。所以需要做一些处理。
✎ 按尺寸分类过滤
将图片分为移动端 和 PC 端, 按尺寸去除无效图片。
# 【用途】将图片按尺寸分类剔除# 【命令】python3 3-classify-by-size.py $inputDir $outputDir
# 删除尺寸不规范的图片,width_list 中是数量大于 100 的尺寸if width not in width_list: print('move {}'.format(img_name)) move_file(img_dir, other_img_dir, img_name)# 删除 高度小于 30 的图片elif height < 30: print('move {}'.format(img_name)) move_file(img_dir, other_img_dir, img_name)# 按尺寸归档else: width_dir = os.path.join(img_dir, str(width)) if not os.path.exists(width_dir): print('mkdir:{}'.format(width)) os.mkdir(width_dir) print('move {}'.format(img_name)) move_file(img_dir, width_dir, img_name)
✎ 图片去重
如果自己写图片去重的逻辑也可以,做一个图片相似度比较。这里偷个懒,直接用了现成的图片相似度检测工具 duplicate Photos Fixer Pro。这里简单说一下使用方法, 如图红框提示,支持调整检测条件和相似程度。
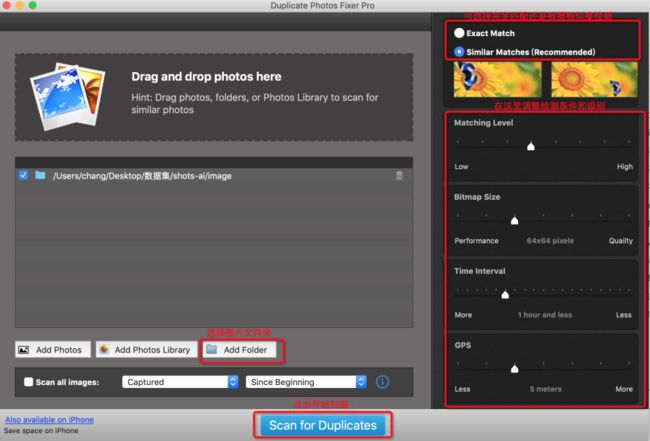
每张图片的 Hash 值计算完成之后,还可以再调整相似度来筛选。

✎ 图片重命名
这里主要是想说一下怎么做样本管理,因为数据集是会逐步丰富的,可能会存在很多个版本的数据集。友好的命名便于管理,比如 generator-mobile-sample-10cate-20200101-1.png, 表明这是 2020.01.01 自动生成的第 1 个移动端样本,这一批数据集包含 10 个分类。
样本标注
✎ 半自动标注
有一些组件是可以自动标注的,比如 statusbar 和 navbar, 因为几乎每张图片都会有且位置和尺寸基本相同,所以可以为每张图片自动生成一个 VOC 格式的 xml, 包含两个目标组件分类。然后在人工标注其他组件时只有少部分需要调整,可以节省很多人力。
目前也在探索更多的半自动化标注方式以减少人工标注的成本。
✎ 人工标注
使用 labelImg 工具进行人工标注,按照链接中提供的安装步骤安装,这里简单介绍下用法。
// 下载 labelImggit clone https://github.com/tzutalin/labelImg.git
// 进入 labelImgcd labelImg-master
// 之后按照 github 中的提示安装环境
// 执行一下命令就会打开可视化界面python3 labelImg.py
可视化界面如下, 支持 Pascal VOC 和 Yolo 两种保存标注的格式。

界面怎么用就不说了,这里推荐一些提高标注效率的快捷键, 另外 选中 View > Auto Save mode 可以自动保存。
w 新建立一个矩形框
d 下个图片
a 上个图片
del/fn + del 删除选中的矩形框,我的电脑需要 fn + del
Ctrl/Command++ 放大
Ctrl/Command-- 缩小
↑→↓← 移动矩形框
▐ Puppeteer 自动生成样本
根据组件类型定义随机生成组件,这个组件的样式也是随机的。示例如下, 每个正样本都有一个 class 为 element-开头的选择器,例如 element-button 便于后续获取组件的类别信息。

随机生成页面
编写一个页面,随机选取一些组件展示。本地启动服务,打开页面,例如 http://127.0.0.1:3333/#/generator,示例页面如下:

但是这个的页面与实际的 UI 界面相差太大,只有正样本,背景太简单。这里通过裁剪出真实的 UI 界面中的片段与自动生成的目标组件组合的方式,来提高生成样本的质量, 示例样本如下,应该能看出来页面中自动生成的组件吧?

Puppeter 截图生成样本
确定随机页面(http://127.0.0.1:3333/#/generator )可访问后,使用 Puppeteer 编写脚本自动打开页面、截图保存、并获取组件的类别和边界框。主要逻辑如下:
const pptr = require('puppeteer')// 存放 COCO 格式的样本数据const mdObj = {};const browser = await pptr.launch();const page = await browser.newPage();await page.goto(`http://127.0.0.1:3333/#/generator/${Date.now()}`)await page.evaluate(() => { const container: HTMLElement | null = document.querySelector('.container'); const elements = document.querySelectorAll('.element'); const msg: any = {bbox: []}; // 获取页面中所有带 .element 选择器的元素 elements.forEach((element) => { const classList = Array.from(element.classList).join(',') if (classList.match('element-')) { // 获取类别 const type = classList.split('element-')[1].split(',')[0]; // 计算边界框并保存至 msg pushBbox(element, type); } });});// 保存 COCO 格式样本数据logToFile(mdObj);// 保存 UI截图await page.screenshot({path: 'xxx.png'});// 关闭浏览器await browser.close();
▐ 样本评估
阿里系应用 UI 界面样本中,组件数量和丰富度不平衡,可通过自动生成样本来平衡每种组件的数量。对于自动生成的样本,如何来评估样本质量?如何自动生成目标组件的逻辑可枚举为 1 万种,自动生成 2 万个此类组件就没有意义。
如何评估自动生成的样本的丰富度和数量是否合理?这是目前我们在探索的问题。
▐ 模型训练
Detectron 2
使用 Facebook 开源的目标检测框架 Detectron 2, 通过 merge_from_file 指定使用 Faster R-CNN。
from detectron2.data import MetadataCatalogfrom detectron2.evaluation import PascalVOCDetectionEvaluator
from detectron2.engine import DefaultTrainer,hooksfrom detectron2.config import get_cfg
cfg = get_cfg()
cfg.merge_from_file("./lib/detectron2/configs/COCO-Detection/faster_rcnn_R_50_C4_3x.yaml")cfg.DATASETS.TRAIN = ("train_dataset",)cfg.DATASETS.TEST = ('val_dataset',) # no metrics implemented for this datasetcfg.DATALOADER.NUM_WORKERS = 4 # 多开几个worker 同时给GPU喂数据防止GPU闲置cfg.MODEL.WEIGHTS = "detectron2://ImageNetPretrained/MSRA/R-50.pkl" # initialize from model zoocfg.SOLVER.IMS_PER_BATCH = 4cfg.SOLVER.BASE_LR = 0.000025cfg.SOLVER.NUM_GPUS = 2cfg.SOLVER.MAX_ITER = 100000 # 300 iterations seems good enough, but you can certainly train longercfg.MODEL.ROI_HEADS.BATCH_SIZE_PER_IMAGE = 128 # faster, and good enough for this toy datasetcfg.MODEL.ROI_HEADS.NUM_CLASSES = 29 # only has one class (ballon)
# 训练集register_coco_instances("train_dataset", {}, "data/train.json", "data/img")# 测试集register_coco_instances("val_dataset", {}, "data/val.json", "data/img")
import osos.makedirs(cfg.OUTPUT_DIR, exist_ok=True)
class Trainer(DefaultTrainer): @classmethod def build_evaluator(cls, cfg, dataset_name, output_folder=None): ### 按需求重写
@classmethod def test_with_TTA(cls, cfg, model): ### 按需求重写
trainer = Trainer(cfg)trainer.resume_or_load(resume=True)trainer.train()
使用 Detectron 2 模型训练的产物是一个 .pth 格式的模型文件。这个 .pth 格式的模型文件长啥样可以看下这篇 Pytorch 中保存的模型文件.pth 深入解析。
Pipcook
Pipcook 已经帮我们封装好了从数据收集、数据接入、模型训练、模型评估的代码,我们无需写这些工程链路的 Python 脚本。目前 Pipcook 中的目标检测链路使用的是 Detectron 2 中的 Faster RCNN 算法,大家可以去 Pipcook Plugins 看下实现就明白了。
以下是使用 Pipcook 进行目标检测的示例代码。
const {DataCollect, DataAccess, ModelLoad, ModelTrain, ModelEvaluate, PipcookRunner} = require('@pipcook/pipcook-core');
const imageCocoDataCollect = require('@pipcook/pipcook-plugins-image-coco-data-collect').default;const imageDetectronAccess = require('@pipcook/pipcook-plugins-detection-detectron-data-access').default;const detectronModelLoad = require('@pipcook/pipcook-plugins-detection-detectron-model-load').default;const detectronModelTrain = require('@pipcook/pipcook-plugins-detection-detectron-model-train').default;const detectronModelEvaluate = require('@pipcook/pipcook-plugins-detection-detectron-model-evaluate').default;
async function startPipeline() { // collect detection data const dataCollect = DataCollect(imageCocoDataCollect, { url: 'http://ai-sample.oss-cn-hangzhou.aliyuncs.com/image_classification/datasets/autoLayoutGroupRecognition.zip', testSplit: 0.1, annotationFileName: 'annotation.json' }); const dataAccess = DataAccess(imageDetectronAccess); const modelLoad = ModelLoad(detectronModelLoad, { device: 'cpu' }); const modelTrain = ModelTrain(detectronModelTrain); const modelEvaluate = ModelEvaluate(detectronModelEvaluate);
const runner = new PipcookRunner( { predictServer: true }); runner.run([dataCollect, dataAccess, modelLoad, modelTrain, modelEvaluate])}startPipeline();
▐ 模型评估
评估指标
发现文章太长了,这里扔个学习资源吧, 强烈推荐这个视频课程 Python3入门机器学习经典算法与应用[慕课网] ,没有时间看的话直接看人家写的笔记吧,第 10 章详细讲了使用精准率和召回率评估分类结果。
啊, 还是简单解释下吧。
精准率可以理解成查准率,比如预测了 100 个是 Button, 其中 80 个是预测正确的, 精准率是 80 / 100。
召回率可以理解成查全率,比如实际有 60 个是 Button, 成功预测了 40 个, 召回率是 40 / 60。
在目标检测的性能评价指标是 mAP 和 FPS,mAP 计算的是所有类别的平均准确率, 但由于目标检测结果除了类别还有个边界框,如何评价这个边界框的预测准确性,又涉及到 IoU (Interp over Union)交并比的概念,用来表示预测的边界框与真实的边界框的交并比。
在后面的评估结果中可以看到这样的结果,当 IoU=0.50:0.95 即预测的边界框与真实的边界框的交并比在 0.5 到 0.95 之间时都算边界框预测正确,此时的精准率 AP 为 0.772。
Average Precision (AP) @[ IoU=0.50:0.95 | area= all | maxDets=100 ] = 0.772 Average Precision (AP) @[ IoU=0.50 | area= all | maxDets=100 ] = 0.951 Average Precision (AP) @[ IoU=0.75 | area= all | maxDets=100 ] = 0.915
评估代码
评估代码如下:
from pycocotools.cocoeval import COCOevalfrom pycocotools.coco import COCOannType = 'bbox'# 测试集 ground truthgt_path = '/Users/chang/coco-test-sample/data.json'# 测试集 预测结果dt_path = '/Users/chang/coco-test-sample/predict.json'
gt = COCO(gt_path)gt.loadCats(gt.getCatIds())
dt = COCO(dt_path)imgIds=sorted(gt.getImgIds())cocoEval = COCOeval(gt,dt,annType)
for cat in gt.loadCats(gt.getCatIds()): cocoEval.params.imgIds = imgIds cocoEval.params.catIds = [cat['id']] print '------------------------------ ' cat['name'] ' ---------------------------------' cocoEval.evaluate() cocoEval.accumulate() cocoEval.summarize()
评估结果
目前用阿里系 UI 界面与自动生成的样本组合训练, mAP 基本在 75% 左右。
------------------------------ searchbar ---------------------------------Running per image evaluation...Evaluate annotation type *bbox*DONE (t=2.60s).Accumulating evaluation results...DONE (t=0.89s). Average Precision (AP) @[ IoU=0.50:0.95 | area= all | maxDets=100 ] = 0.772 Average Precision (AP) @[ IoU=0.50 | area= all | maxDets=100 ] = 0.951 Average Precision (AP) @[ IoU=0.75 | area= all | maxDets=100 ] = 0.915 Average Precision (AP) @[ IoU=0.50:0.95 | area= small | maxDets=100 ] = -1.000 Average Precision (AP) @[ IoU=0.50:0.95 | area=medium | maxDets=100 ] = 0.795 Average Precision (AP) @[ IoU=0.50:0.95 | area= large | maxDets=100 ] = 0.756 Average Recall (AR) @[ IoU=0.50:0.95 | area= all | maxDets= 1 ] = 0.816 Average Recall (AR) @[ IoU=0.50:0.95 | area= all | maxDets= 10 ] = 0.830 Average Recall (AR) @[ IoU=0.50:0.95 | area= all | maxDets=100 ] = 0.830 Average Recall (AR) @[ IoU=0.50:0.95 | area= small | maxDets=100 ] = -1.000 Average Recall (AR) @[ IoU=0.50:0.95 | area=medium | maxDets=100 ] = 0.838 Average Recall (AR) @[ IoU=0.50:0.95 | area= large | maxDets=100 ] = 0.823
我们用非阿里系的 UI 界面看下预测结果, 可以看出一些容易被误识别的情况。

▐ 模型服务部署
我们期望的是当输入一张图片时能返回给模型预测的结果。所以拿到模型文件之后,需要写一个模型服务,接收一个样本,并返回模型预测的结果。
from detectron2.config import get_cfgfrom detectron2.engine.defaults import DefaultPredictor
with open('label.json') as f: mp = json.load(f)
cfg = get_cfg()cfg.merge_from_file("./config/faster_rcnn_R_50_C4_3x.yaml")cfg.MODEL.WEIGHTS = "./output/model_final.pth" # initialize from model zoocfg.MODEL.ROI_HEADS.NUM_CLASSES = len(mp) # only has one class (ballon)cfg.MODEL.DEVICE='cpu'
model = DefaultPredictor(cfg)
def predict(image): im2 = cv2.imread(image) out = model(x) data = {'status': 200} data['content'] = trans_data(out)
# EAS python sdkimport spark
num_io_threads = 8endpoint = '' # '127.0.0.1:8080'
spark.default_properties().put('rpc.keepalive', '60000')context = spark.Context(num_io_threads)queued = context.queued_service(endpoint)
while True: receive_data = srv.read() try: msg = json.loads(receive_data.decode()) ret = predict(msg["image"]) srv.write(json.dumps(ret).encode()) except Exception as e: srv.error(500, str(e))
模型部署后拿到访问链接即可直接调用例如 http://example.com/api/predict/detect 来预测。
▐ 模型应用
模型部署之后就可以在我们的应用中调用获取预测结果(视觉稿中的组件类别和边界框),与从视觉稿中导出的 JSON 树比对,从而获得一个带有组件信息(D2C Schema 中的 smart.layerProtocol.component 字段)的 JSON 描述(处理后的最终 JSON 作为 DSL 的输入生成代码)。
const detectUrl = 'http://example.com/api/predict/detect';const res = await request(detectUrl, { method: 'post', dataType: 'json', timeout: 1000 * 10, content: JSON.stringify({ image: image, }),});const json = res.content;
关于模型服务的部署和调用可以去 PAI 的阿里云文档查看。
未来展望
由于选择的是深度学习算法, 需要大量的训练集样本,所以样本数量和质量是亟需解决的问题。
目前我们已经拥有 2.5万+ 的 UI 界面样本,包含 10 个分类,自动生成的样本支持 10 个分类。但人工标注的 UI 界面样本均为阿里系产品,虽然样本图片不同但设计风格会有相似且设计规范较统一,使得组件样式的丰富度不够,对阿里系之外的设计稿泛化能力较阿里系的要差。另外遵循一定的随机化规则自动生成的样本还存在版式和样式与实际样本有差异的地方,自动生成的样本质量无法评估。
未来在数据集方面,会考虑加入业界样本数量较大的数据集,并优化样本自动生成逻辑,同时探索评估自动生成的样本质量的方法。
One More Thing
我们是阿里巴巴-淘系技术部-频道与D2C智能团队,致力于前端智能化领域的探索和实践,赋能淘宝、天猫、聚划算等日常与大促(如双 11 )业务,是淘系前端智能化实践的领路人,也是阿里经济体前端委员会智能化方向的核心团队。
目前团队有较多高校和海外背景的技术小二,专业领域涉及前端、算法、全栈等。我们在 D2C(Design to Code) 领域开放了 Imgcook(https://www.imgcook.com) 平台,在逐步释放阿里生态的前端生产力;我们也与 Google 的 tensorflow 团队保持长线合作,基于 tfjs-node 之上,开源了我们的前端算法工程框架 Pipcook(https://github.com/alibaba/pipcook),在引领前端行业向智能化时代迈进。
简历投递至????:[email protected]
或加微信:onlychang92, 备注:淘系技术公众号-招聘
欢迎加入我们的社区群,钉钉群号:32918052
✿ 拓展阅读



作者|常艳芳(苏川)
编辑|橙子君
出品|阿里巴巴新零售淘系技术部
![]()
文中链接
1 https://www.imgcook.com/
2 https://www.imgcook.com/docs?slug=install-plugin
3 https://www.imgcook.com/docs?slug=d2c-json-info
4 https://www.imgcook.com/docs?slug=dsl-dev
5 https://www.imgcook.com/docs?slug=advanced-rules
6 https://www.reddit.com/r/computervision/comments/88xz6g/use_rcnn_to_detect_ui_elements_in_a_webpage/
7 https://datascience.stackexchange.com/questions/16159/is-machine-learning-suitable-for-detecting-screen-elements
8 https://www.reddit.com/r/computervision/comments/cmw35r/any_thoughts_on_a_good_way_to_detect_ui_elements/
9 https://dsp.stackexchange.com/questions/1657/how-can-i-detect-elements-of-gui-using-opencv
10 https://stackoverflow.com/questions/19948702/how-to-recognize-ui-elements-in-image
11 https://zenodo.org/record/2530277#.XmtaRJMzbOR
12 https://arxiv.org/pdf/1802.02312.pdf
13 https://arxiv.org/abs/1802.02312
14 https://experts.illinois.edu/en/publications/rico-a-mobile-app-dataset-for-building-data-driven-design-applica
15 https://www.youtube.com/watch?v=bVKgsNazl7w
16 http://ranjithakumar.net/resources/mobile-semantics.pdf
17 https://arxiv.org/pdf/1802.02312.pdf
18 https://arxiv.org/pdf/1912.09421.pdf
19 https://arxiv.org/pdf/1902.11247.pdf
20 https://arxiv.org/pdf/1901.02633.pdf
21 https://dzone.com/articles/deep-learning-vs-machine-learning-the-hottest-topi
22 https://en.wikipedia.org/wiki/Machine_learning#applications
23 https://en.wikipedia.org/wiki/Object_detection
24 https://github.com/facebookresearch/Detectron
25 https://github.com/facebookresearch/maskrcnn-benchmark
26 https://github.com/open-mmlab/mmdetection
27 https://github.com/facebookresearch/detectron2
28 https://www.zhihu.com/question/350117858/answer/854376239
29 https://github.com/alibaba/pipcook
30 https://www.tensorflow.org/js
31 https://juejin.im/post/5e154082e51d45411a0ebda1
32 https://developer.sketchapp.boltdoggy.com/guides/sketchtool/
32 https://www.duplicatephotosfixer.com/
33 https://github.com/tzutalin/labelImg
34 https://zhuanlan.zhihu.com/p/84797438
35 https://github.com/alibaba/pipcook/tree/master/packages/plugins
36 https://coding.imooc.com/class/chapter/169.html
37 https://github.com/chang20159/liu_yu_bo_play_with_machine_learning/tree/master/Chapter10
38 https://help.aliyun.com/document_detail/69223.html

