Python处理Excel,读取、行列输出、预览、透视、可视化
学习更多,欢迎关注微信公众号:Excel办公小技巧
Python在这几年的热度居高不下,众所周知对初学者友好、免费、大量第三方库等。总之,对Python了解越多,你就越能看到它展示给你的更多的优点。

今天通过对pandas库的使用,让大家感受下Python如何很好的操作Excel数据:
1. 读取及预览
今天的示例数据文件是xlsx格式,所以我们使用read_excel函数读取(重要参数encoding、header、sliprows等),并通过head()默认返回前5行数据,tail返回后几行。
import pandas as pdcasedata=pd.read_excel(r'C:\Users\guofeng\Desktop\示例数据.xlsx')print(casedata.head(5))#或使用行索引实现print(casedata.iloc[0]

2. 查看统计项摘要
print(casedata.describe())从统计结果看, 可以初步对数据有个大致了解:
比如我们从计数项可以看到近一个月发生77次地震,从分位数可知出现最大震级6.6级、中位数4级,最小2.1级,以及震源深度中位数10千米,75%以上的震源深度小于19千米等等。
3. 数据筛选
3.1 输出指定列
3.1.1 直接使用列名输出
print(casedata['发震时刻(UTC+8)'])
3.1.2 使用行标签输出
结果同3.1.1
print(casedata.loc['发震时刻(UTC+8)'])3.1.3 使用行索引输出
结果同3.1.1
print(casedata.iloc[:,1])3.2 输出指定行
3.2.1 获取指定行索引
比如我们要获取表内最大震级的的全部信息,先通过idxmax获取震级的最大值的索引,然后通过iloc使用索引获取整行数据。
print(casedata['震级(M)'].idxmax()27
3.2.2 获取索引对应行数据
print(casedata.iloc[casedata['震级(M)'].idxmax()])
3.3 排序后输出指定行
比如输出震级top6 的详细数据,我们需要对震级降序后,再通过head(10)或是使用索引输出。
print(casedata.sort_values(by='震级(M)',ascending=False).head(6))print(casedata.sort_values(by='震级(M)',ascending=False).iloc[:6]
4. 常规应用
之前已经分别介绍过如何合并多文件、两个数据文件进行匹配及多文件输出不同sheet表等,这里直接看历史文章即可。
4.1 数据合并与数据匹配
Python处理Excel-大量数据表如何汇总到同一张表上
Python处理Excel-如何根据某一字段快速匹配大量字段数据
4.2 数据输出
Python处理Excel-多文件整理到同一工作簿不同工作表上显示
5. 数据透视表
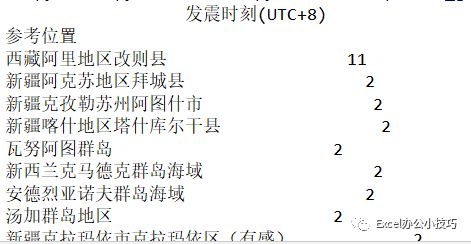
应用透视表,获取不同位置的发阵次数,并降序输出:
print(pd.pivot_table(casedata,index='参考位置',aggfunc='count',values=['发震时刻(UTC+8)']).sort_values('发震时刻(UTC+8)',ascending=False))
6. 可视化
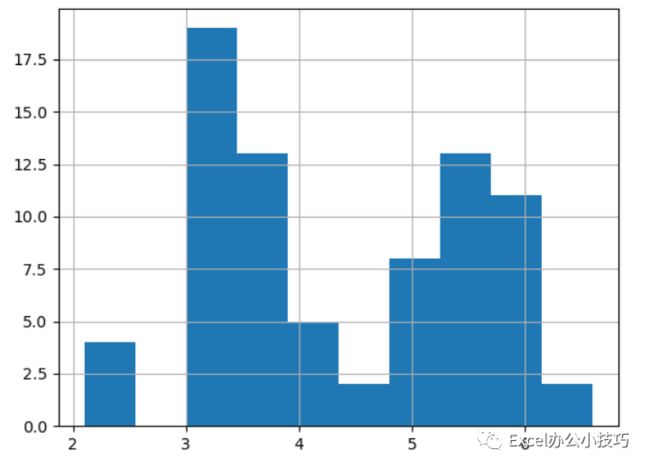
pandas自带的可视化函数的快速实现,如果追求可视化效果,最好还是用其他绘图包。
casedata['震级(M)'].hist()plt.show()
以上列举的仅为pandas的一些常用功能展示,比较简单,后续更新关注微信公众号:Excel办公小技巧