论文笔记:Eye In-Painting with Exemplar Generative Adversarial Networks

先发一张美美的图片!
这篇文章的工作出发点是补救那些人在拍照时不小心眼睛闭上而得到的照片,可以说是“开眼”啦~
这里先简要介绍这项工作:
1)目的:让照片中闭眼的人物睁开双眼;
2)网络框架:生成拮抗网络(GAN),本文提出了ExGANs.
3)基本思路:基于照片补全(Image Completion)的思想,将照片中人物的“闭眼”先定位出来,将其去除;基于另外一张该人物在不同环境、不同时间下的照片,将这个“空白”脑补填充出来;
4)实验步骤:我们先训练一个能够基于参照图完成对确实眼睛的照片进行填补的生成网络;在实际应用的时候,则只需要将闭眼的照片中的闭眼挖空,,即可应用我们的生成模型。
一、基本思想
(1)GAN在图像生成方面有突出的效果;
(2)但不加“参照”的GAN只能根据经验对人眼进行生成,而并不是针对照片中的特定人物进行生成;但我们知道每个人都是独一无二的,一般来说不同人的外貌、面部结构、比例等是不同,其中,人眼的shape、瞳孔color等也应该是不同的,这里我们称之为“Personality”;
(3)一个人物的原型exemplar作为参照reference是必要的,可以基于此参照学习这个人物的面部特征,进而引导眼睛的生成。
二、相关工作
1.这项工作主要涉及的是2017年这篇发表在SIGGRAPH上的文章:
Globally and Locally Consistent Image Completion.
其主要功能是:对不完整图片基于本身的特征进行修补Completion.

三、网络架构
1.基本模型(Base Model Framework)
对闭眼照片和参照图片先得到对应他们各自眼睛所在位置的mask,可以理解为一个与图片大小相同的0/1矩阵,其中对应眼睛的区域(矩形区域)内的元素为1,其余区域元素值为0.
我们对参照图片的使用方式有两种——
·Reference-image in-painting: 即将参照图片与其mask,输入图片与其mask,直接contact在一块,于是就有8个channels;之后我们再将其一块输入G。
 ,即:
,即: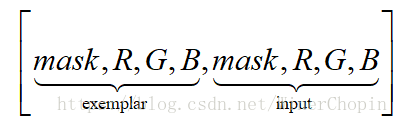
·Code-based in-painting: 考虑到这样一个事实,同一个人的不同照片差别是比较大的;但在意识形态上其能够指向同一个人,所以说我们应该考虑的不是简单的图片之间的pixel到pixel的相异性,而应该考虑其在更高维度空间即更抽象上的关系。譬如说,一个人开心和生气的时候眼睛表现是不同的,但在意识形态(即抽象概念)上是指向同一个人。于是我们选择将图片先进行一次特征抽取(C模块),这个特征指示了一个人脸在意识上是如何区别于其他人脸的。
(1)各个模块的作用如下:
·G:生成网络
·D:检测网络
·C:是一个感知特征的提取网络,用来将一张图片I进行映射:,它会将一张图片(或选定部分)经过一个CNN转换得到一个N维的向量(高维特征)。
(2)我们定义
a.Reference image: 原型参照图——![]()
b.Input image: 输入图片,即我们想要补救的闭眼图片;其中,闭眼的部分已经先经过一个网络被定位出来了——![]()
c.Groundtruth image: 目标图片——![]()
(3)下面我们分情况讨论
①Reference-image in-painting

a.这里分为5个步骤
a)Step 1: 用G生成目标图片
b)Step 2: 计算重构损失,即目标图片与生成图片的“差距”
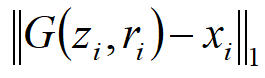
c)Step 3: 计算基于下的识别器D对于真实图片的得分
d)Step 4: 计算基于下的识别器D对于生成图片的得分
e)Step 5: 计算拮抗损失
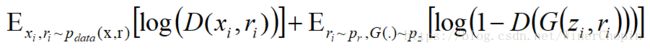
f)最后的目标函数是:
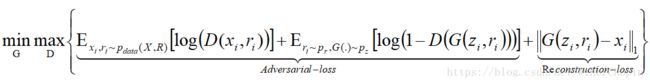
②Code-based in-painting

a.这里多了2个步骤,总共7个;此外多了一个C模块用来提取感知特征——
a)Step 1: 对参照图片提取感知特征![]() ;
;
b)Step 2: 用G生成目标图片![]()
c)Step 3: 计算重构损失,即目标图片与生成图片的“差距”:
d)Step 4: 计算基于![]() 下的识别器D对于真实图片的得分
下的识别器D对于真实图片的得分
e)Step 5: 计算基于![]() 下的识别器D对于生成图片的得分
下的识别器D对于生成图片的得分
f)Step 6: 计算拮抗损失
![]()
g)Step 7: 计算感知损失,即对生成图片做同样的感知特征提取。因为是来自于同一个人,所以我们期待生成图片与参考图片的感知特征应该是非常接近的。
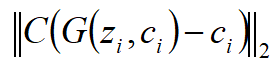
h)最后的目标函数是

四、最后我们不妨看一下实验结果



其中,每一列分别是:
1)原型参照
2)经需要修补的图片
3)Groundtruth(Local)
4)生成图片(Global)
5)Groundtruth(Local)
6)生成图片(Local)