Python爬虫基础库-urllib、requests
一、urllib库
1.1 urllib库包含4个模块
- request:它是最基本的HTTP请求模块,可以用来模拟发送请求。就像在浏览器里输入网挝然后回车一样,只需要给库方法传入URL以及额外的参数,就可以模拟实现这个过程了。
- error:异常处理模块,如果出现请求错误 ,我们可以捕获这些异常,然后进行重试或其他操作以保证程序不会意外终止 。
- parse:一个工具模块,提供了许多 URL 处理方法,比如拆分、解析 、合并等 。
- robot parser :主要是用来识别网站的robots.txt文件,然后判断哪些网站可以爬,哪些网站不可以爬,它其实用得比较少。
1.1.1 使用urllib发起请求
import urllib.request
response = urllib.request.urlopen('http://www.baidu.com')
print(response.status) # 获取请求状态码
print(response.geturl()) # 获取访问的URL
print(response.getheaders()) # 获取响应头信息
print(response.read()) # 获取网址HTML原码
1.1.2 urllib请求使用参数data
data参数是可选的;如果要添加该参数,并且如果它是字节流编码格式的内容,即bytes类型,则需要通过bytes()方法转化。另外,如果传递了这个参数,则它的请求方式就不再是GET方式,而是POST方式 。
其他参数还有:timeout参数用于设置超时时间,单位秒;
import urllib.parse
import urllib.request
data = bytes(urllib.parse.urlencode({'word’:’ hello'}), encoding=’utf8')
# urlencode()方法来将参数字典转化为字符串; 传入参数需要被转码成 bytes(字节流)类型
response= urllib.request.urlopen('http://httpbin.org/post', data=data)
print(response.read())
urllib.request.Request (url, data=None, headers={}, origin_req_host=None, unverifiable=False, method=None)
import urllib.request
headers = {'User-Agent':'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/75.0.3770.142 Safari/537.36'}
request = urllib.request.Request('http://httpbin.org/get', headers=headers)
response = urllib.request.urlopen(request)
print(response.read().decode('utf-8'))
1.1.3 Handler 子类
各种 Handler 子类继承这个BaseHandler类,举例如下 。
- HTTPDefaultErrorHandler :用于处理HTTP响应错误,错误都会抛出HTTP Error类型的异常 。
- HTTPRedirectHandler: 用于处理重定向 。
- HTTPCookieProcessor: 用于处理Cookies。
- ProxyHandler: 用于设置代理, 默认代理为空。
- HTTPPasswordMgr: 用于管理密码, 它维护了用户名和密码的表。
- HTTPBasicAuthHandler: 用于管理认证,如果一个链接打开时需要认证,那么可以用它来解决认证问题。
有些网站在打开时就会弹出提示框,直接提示你输入用户名和密码,验证成功后才能查看页面;可以借助HTTPBasicAuthHandler就可以完成。
1、密码验证
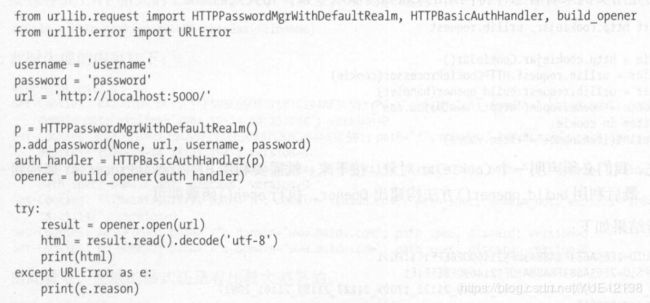
2、使用代理

3、Cookies获取或处理

1.2 异常处理
urllib的error模块定义了由 request 模块产生的异常。如果出现了问题,request模块便会抛州error模块中定义的异常 。
from urllib import request, error
try:
response = request.urlopen('https://cuiqingcai.com/index.htm')
except error.URLError as e:
print(e.reason) # reason属性返回错误原因
1.3 解析链接
urllib库里还提供了parse模块,它定义了处理URL的标准接口,例如实现URL各部分的抽取、合并以及链接转换。
- urlparse()/urlunparse():该方法可以实现URL的识别和分段/合并;
- urlsplit()/urlunsplit():这个方法和 urlparse()方法非常相似,只不过它不再单独解析params部分;
- urljoin():生成链接
- urlencode(): urlencode()方法将参数序列化为GET请求参数。
- parse_qs()/parse_qsl():有了序列化,必然就有反序列化。如果我们有一串GET请求参数,利用 parse_qs()方法,就可以将它转回字典;/ parse_qsl()方法将参数转化为元组组成的列表;
- quote()/ unquote():该方法可以将内容转化为URL编码的格式,URL中带有中文参数时,有时可能会导致乱码的问题,此时用这个方法可以将巾文字符转化为URL编码/解码。
二、requests库
在requests库中发起请求的方法就是get()方法:
分别用 post()、put()、delete()等方法实现了POST、PUT、DELETE等请求
import requests
headers = {'User-Agent':'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/75.0.3770.142 Safari/537.36'}
r = requests.get('http://httpbin.org/get', headers=headers)
print(type(r.text))
print(r.json())
print (type(r.json()))
2.1 会话维持
设想这样一个场景,第一个请求利用 post()方法登录了某个网站,第二次想获取成功登录后的自己 的个人信息,你又用了一次 get()方法去请求个人信息页面 。 实际上,这相当于打开了两个浏览器,是两个完全不相关的会话,能成功获取个人信息吗?那当然不能。
其实解决这个问题的主要方法就是维持同一个会话,也就是相当于打开一个新的浏览器选项卡而不是新开一个浏览器。但是我又不想每次设置 cookies,那该怎么办呢?这时候就有了新的利器——Session对象 。
import requests
s = requests.Session()
s .get('http://httpbin.org/cookies/set/number/123456789')
r = s.get('http://httpbin.org/cookies')
print(r.text)
'''
{
'cookies':{
'number':'123456789'
}
}
'''
2.2 设置代理
import requests
proxy = '180.122.148.102:9999'
proxies = {
'http': 'http://' + proxy,
'https': 'https://' + proxy
}
try:
response = requests.get('http://httpbin.org/get', proxies=proxies)
print(response.text)
except requests.exceptions.ConnectionError as e:
print('Error', e.args)