1. kNN
1.1 基本的kNN模型
kNN(k-nearest neighbor)的思想简单来说就是,要评价一个未知的东西U,只需找k个与U相似的已知的东西,并通过k个已知的,对U进行评价。假如要预测风炎君对一部电影M的评分,根据kNN的思想,我们可以先找出k个与风炎君相似的,并且对M进行过评分的用户,然后再用这k个用户的评分预测风炎君对M的评分。又或者先找出k个与M相似的,并且风炎君评价过的电影,然后再用这k部电影的评分预测风炎君对M的评分。在这个例子中,找相似用户的方法叫做user-based kNN,找相似物品的方法叫做item-based kNN。这两种方法的思想和实现都大同小异,因此下文只讨论item-based kNN,并且将其简称为kNN。
根据kNN的思想,我们可以将kNN分为以下三个步骤(假设预测用户u对物品i的评分):
(1)计算相似度
推荐系统中常用的相似度有:Pearson correlation,Cosine,Squared Distance,其中Pearson correlation的运用最为普遍,因此本文只介绍Pearson correlation。
Pearson correlation的取值范围为[-1,1],当值为-1时,表示两组变量负相关,为0时则表示两组变量不相关,为1时表示两组变量正相关,其计算公式如下:

(2)选择邻居
在用户u评过分的所有电影中,找出k个与电影m相似度最高的电影,并用N(u, m)表示这k个电影的集合。
(3)计算预测值
有了k个相似的电影后,就可以用以下公式预测评分:
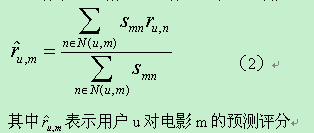
1.2 数据稀疏性与kNN的改进
现在待处理的推荐系统规模越来越大,用户和商品数目动辄百千万计,两个用户之间选择的重叠非常少。如果用用户和商品之间已有的选择关系占所有可能存在的选择关系的比例来衡量系统的稀疏性,那么平时研究最多的MovieLens数据集的稀疏度是4.5%,Netflix是1.2%,Bibsonomy是0.35%,Delicious是0.046%。
从Pearson correlation的计算公式上看,如果某两个电影的交集大小比其它电影的交集要小得多,那么这两个电影的相似度的可靠性就比较低。由上面描述的数据稀疏性可知,在推荐系统中出现某些交集的较小的情况将会十分平常。而这会大大加强相似度的不可靠性。为了预测结果的可靠性,有必要减轻这种不可靠性,因此我们要根据交集的大小对相似度进行一次压缩(shrinkage):

1.3 全局作用与kNN的改进
用户对电影评分有各种趋势,例如:有的用户是严格的评分者,因而倾向于给较低的分数;有的用户是宽松的评分者,因而倾向于给较高的分数;有的电影的表现即使一般也倾向于获得较高的分数。在推荐系统中,将这些趋势称为全局作用(global effect,简称GE)。
常用的GE有16种,这里只列出本文用到的3种:
| No. |
Global Effect |
Meaning |
| 0 |
Overall mean |
全部评分的平均值 |
| 1 |
Movie × 1 |
电影的被评分倾向 |
| 2 |
User × 1 |
用户的评分倾向 |
| 3 |
User × Time(user)1/2 |
用户第一次评分后到现在相距了多少时间 |
表格的第一列表示各个 GE 被考虑的顺序;第二列表示 GE 的名称;第三列表示GE的意义。其中第二列命名的意义为:在“×”之前的部分代表该 GE 是基于用户或基于电影的,在“×”之后的部分代表 xu,m(下文会提到)的取值形式。
GE的目标是为该GE估计一个特定的参数(第0号GE除外,因为全部评分的平均值能直接计算得到)。在估计参数时,一次只考虑一个GE,并且使用前面已得到的所有GE的预测残差(residual)作为本次估计的真实评分。估计第t+1个GE时的真实评分由以下公式得到:

在估计GE的特定参数时,也一样要考虑到前面提到的数据稀疏性问题,即该参数也要进行压缩,进行压缩后的参数估计公式如下:

其中表示这是第t个参数,并且是基于用户的,表示用户u评过分的所有电影的集合,表示第u个用户和第m部电影相关的解释变量(explanatory variable),且在计算第1,2号GE时为1,在计算第3号GE时为

kNN基本模型并没有将GE考虑在内,为了使预测结果更加精确,有必要将GE加到kNN的预测公式中,改进后的预测公式如下:
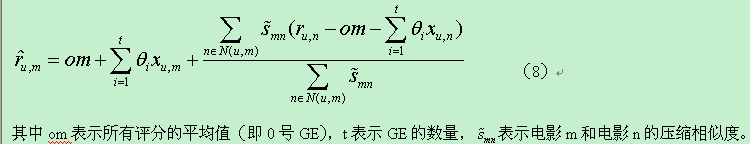
2. 实验
实验数据使用MovieLens 100k的数据。这份数据由1000个用户对1700部电影的100000个评分组成,其稀疏性为5.88%。评价指标使用RMSE(root mean squared error):

各算法在该数据集的表现如下所示,其中表中的数值指RMSE。
|
|
k=10 |
k=15 |
k=20 |
| 基本kNN模型 |
1.076 |
1.071 |
1.068 |
| 压缩相似度的kNN |
1.011 |
1.016 |
1.020 |
| 带GE的kNN |
0.987 |
0.988 |
0.989 |
| 压缩相似度并且带GE的kNN |
0.946 |
0.951 |
0.955 |
从上表可知,当k=10时,压缩相似度的改进效果为6%,GE的改进效果为8.2%,两者叠加的改进效果为12.1%。这说明:(1)数据的稀疏性对越粗糙的模型,影响越大。(2)GE的影响较大,原因是kNN的预测结果是相似度与用户评分的加权平均值。当用户评分包含与相似度无关的因素(即GE)越多时,最终结果越不可靠。
代码由于较多就不直接贴上,想要的可以在从以下地址下载(Python实现)
http://ishare.iask.sina.com.cn/f/34170290.html
3. 参考
[1] Scalable Collaborative Filtering with Jointly Derived Neighborhood Interpolation Weights
[2] Netflix Prize 中的协同过滤算法
[3] 个性化推荐技术中的协同过滤算法研究
[4] 大数据应用之个性化推荐的十大挑战
[5] MovieLens Data Sets