5篇CVPR 各路大佬显身手 点云分割、姿态估计、物体检测、生成重建
点击上方“3D视觉工坊”,选择“星标”
干货第一时间送达

3D方向:港中文针对分割问题提出双重设置点分组模型;清华提出无需 PoseNet 的联合深度姿势学习;北理工和百度提出基于LiDAR的在线3D视频物体检测以及基于图的消息传递和时空变化注意机制;TU Kaiserslautern 提出基于深度体素的网络,可从单个深度图进行3D手形和姿势估计;明尼苏达大学提出单目相机具有全局相关深度的动态场景的新型视图合成的模型;百度和UCLA 提出用于3D生成、重构和分类的基于能量的无序点集学习模型;中科院提出从单视图图像中学习姿势不变的3D物体重建;斯坦福提出变形感知的3D模型嵌入和检索;名古屋大学提出使用正态分布变换表征多个3D LiDAR 的定位和制图模型 [ITSC20];巴黎高等理工提出通过双重潜在空间导航的本征点云插值;苏黎世联邦理工提出基于LiDAR的3D物体检测的量化数据增强模型。
图结构方向:德国卡尔斯鲁理工学院使用距离变换预测和运动估计以及基于图匹配进行细胞分割和跟踪。
题目为机器翻译,仅供参考。
[1] PointGroup: Dual-Set Point Grouping for 3D Instance Segmentation
用于3D实例分割的双重设置点分组 [CVPR20]
The Chinese University of Hong Kong: Li Jiang, Hengshuang Zhao, et al.
https://arxiv.org/pdf/2004.01658.pdf
Instance segmentation is an important task for scene understanding. Compared to the fully-developed 2D, 3D instance segmentation for point clouds have much room to improve. In this paper, we present PointGroup, a new end-to-end bottom-up architecture, specifically focused on better grouping the points by exploring the void space between objects. We design a two-branch network to extract point features and predict semantic labels and offsets, for shifting each point towards its respective instance centroid. A clustering component is followed to utilize both the original and offset-shifted point coordinate sets, taking advantage of their complementary strength. Further, we formulate the ScoreNet to evaluate the candidate instances, followed by the Non-Maximum Suppression (NMS) to remove duplicates. We conduct extensive experiments on two challenging datasets, ScanNet v2 and S3DIS, on which our method achieves the highest performance, 63.6% and 64.0%, compared to 54.9% and 54.4% achieved by former best solutions in terms of mAP with IoU threshold 0.5.

[2] Towards Better Generalization: Joint Depth-Pose Learning without PoseNet
迈向更好的概括:无需 PoseNet 的联合深度姿势学习 [CVPR20]
Tsinghua: Wang Zhao, et al.
https://arxiv.org/pdf/2004.01314.pdf
https://github.com/B1ueber2y/TrianFlow [Torch]
In this work, we tackle the essential problem of scale inconsistency for self-supervised joint depth-pose learning. Most existing methods assume that a consistent scale of depth and pose can be learned across all input samples, which makes the learning problem harder, resulting in degraded performance and limited generalization in indoor environments and long-sequence visual odometry application. To address this issue, we propose a novel system that explicitly disentangles scale from the network estimation. Instead of relying on PoseNet architecture, our method recovers relative pose by directly solving fundamental matrix from dense optical flow correspondence and makes use of a two-view triangulation module to recover an up-to-scale 3D structure. Then, we align the scale of the depth prediction with the triangulated point cloud and use the transformed depth map for depth error computation and dense reprojection check. Our whole system can be jointly trained end-to-end. Extensive experiments show that our system not only reaches state-of-the-art performance on KITTI depth and flow estimation, but also significantly improves the generalization ability of existing self-supervised depth-pose learning methods under a variety of challenging scenarios, and achieves state-of-the-art results among self-supervised learning-based methods on KITTI Odometry and NYUv2 dataset. Furthermore, we present some interesting findings on the limitation of PoseNet-based relative pose estimation methods in terms of generalization ability.

[3] LiDAR-based Online 3D Video Object Detection with Graph-based Message Passing and Spatiotemporal Transformer Attention
基于LiDAR的在线3D视频对象检测以及基于图的消息传递和时空变化注意机制 [CVPR20]
Beijing Institute of Technology & Baidu: Junbo Yin, et al.
https://arxiv.org/pdf/2004.01389.pdf
https://github.com/yinjunbo/3DVID [Coming soon]
Existing LiDAR-based 3D object detectors usually focus on the single-frame detection, while ignoring the spatiotemporal information in consecutive point cloud frames. In this paper, we propose an end-to-end online 3D video object detector that operates on point cloud sequences. The proposed model comprises a spatial feature encoding component and a spatiotemporal feature aggregation component. In the former component, a novel Pillar Message Passing Network (PMPNet) is proposed to encode each discrete point cloud frame. It adaptively collects information for a pillar node from its neighbors by iterative message passing, which effectively enlarges the receptive field of the pillar feature. In the latter component, we propose an Attentive Spatiotemporal Transformer GRU (AST-GRU) to aggregate the spatiotemporal information, which enhances the conventional ConvGRU with an attentive memory gating mechanism. AST-GRU contains a Spatial Transformer Attention (STA) module and a Temporal Transformer Attention (TTA) module, which can emphasize the foreground objects and align the dynamic objects, respectively. Experimental results demonstrate that the proposed 3D video object detector achieves state-of-the-art performance on the large-scale nuScenes benchmark.

[4] HandVoxNet: Deep Voxel-Based Network for 3D Hand Shape and Pose Estimation from a Single Depth Map
基于深度体素的网络,可从单个深度图进行3D手形和姿势估计 [CVPR20]
TU Kaiserslautern: Jameel Malik, et al.
https://arxiv.org/pdf/2004.01588.pdf
3D hand shape and pose estimation from a single depth map is a new and challenging computer vision problem with many applications. The state-of-the-art methods directly regress 3D hand meshes from 2D depth images via 2D convolutional neural networks, which leads to artefacts in the estimations due to perspective distortions in the images. In contrast, we propose a novel architecture with 3D convolutions trained in a weakly-supervised manner. The input to our method is a 3D voxelized depth map, and we rely on two hand shape representations. The first one is the 3D voxelized grid of the shape which is accurate but does not preserve the mesh topology and the number of mesh vertices. The second representation is the 3D hand surface which is less accurate but does not suffer from the limitations of the first representation. We combine the advantages of these two representations by registering the hand surface to the voxelized hand shape. In the extensive experiments, the proposed approach improves over the state of the art by 47.8% on the SynHand5M dataset. Moreover, our augmentation policy for voxelized depth maps further enhances the accuracy of 3D hand pose estimation on real data. Our method produces visually more reasonable and realistic hand shapes on NYU and BigHand2.2M datasets compared to the existing approaches.

[5] Novel View Synthesis of Dynamic Scenes with Globally Coherent Depths from a Monocular Camera
单目相机具有全局相关深度的动态场景的新型视图合成 [CVPR20]
University of Minnesota & NVIDIA: Jae Shin Yoon, et al.
https://arxiv.org/pdf/2004.01294.pdf
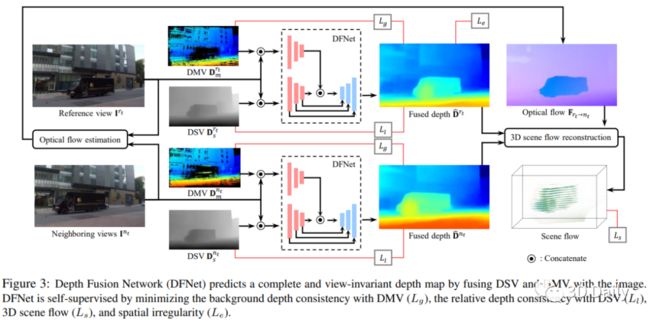
This paper presents a new method to synthesize an image from arbitrary views and times given a collection of images of a dynamic scene. A key challenge for the novel view synthesis arises from dynamic scene reconstruction where epipolar geometry does not apply to the local motion of dynamic contents. To address this challenge, we propose to combine the depth from single view (DSV) and the depth from multi-view stereo (DMV), where DSV is complete, i.e., a depth is assigned to every pixel, yet view-variant in its scale, while DMV is view-invariant yet incomplete. Our insight is that although its scale and quality are inconsistent with other views, the depth estimation from a single view can be used to reason about the globally coherent geometry of dynamic contents. We cast this problem as learning to correct the scale of DSV, and to refine each depth with locally consistent motions between views to form a coherent depth estimation. We integrate these tasks into a depth fusion network in a self-supervised fashion. Given the fused depth maps, we synthesize a photorealistic virtual view in a specific location and time with our deep blending network that completes the scene and renders the virtual view. We evaluate our method of depth estimation and view synthesis on diverse real-world dynamic scenes and show the outstanding performance over existing methods.
[6] Generative PointNet: Energy-Based Learning on Unordered Point Sets for 3D Generation, Reconstruction and Classification
生成PointNet:基于能量的无序点集学习,用于3D生成,重构和分类
Baidu & UCLA: Jianwen Xie, et al.
https://arxiv.org/pdf/2004.01301.pdf
We propose a generative model of unordered point sets, such as point clouds, in the forms of an energy-based model, where the energy function is parameterized by an input-permutation-invariant bottom-up neural network. The energy function learns a coordinate encoding of each point and then aggregates all individual point features into energy for the whole point cloud. We show that our model can be derived from the discriminative PointNet. The model can be trained by MCMC-based maximum likelihood learning (as well as its variants), without the help of any assisting networks like those in GANs and VAEs. Unlike most point cloud generator that relys on hand-crafting distance metrics, our model does not rely on hand-crafting distance metric for point cloud generation, because it synthesizes point clouds by matching observed examples in terms of statistical property defined by the energy function. Furthermore, we can learn a short-run MCMC toward the energy-based model as a flow-like generator for point cloud reconstruction and interpretation. The learned point cloud representation can be also useful for point cloud classification. Experiments demonstrate the advantages of the proposed generative model of point clouds.

[7] Learning Pose-invariant 3D Object Reconstruction from Single-view Images
从单视图图像中学习姿势不变的3D物体重建
CASIA: Bo Peng, et al.
https://arxiv.org/pdf/2004.01347.pdf
https://github.com/bomb2peng/learn3D [Torch]
Learning to reconstruct 3D shapes using 2D images is an active research topic, with benefits of not requiring expensive 3D data. However, most work in this direction requires multi-view images for each object instance as training supervision, which oftentimes does not apply in practice. In this paper, we relax the common multi-view assumption and explore a more challenging yet more realistic setup of learning 3D shape from only single-view images. The major difficulty lies in insufficient constraints that can be provided by single view images, which leads to the problem of pose entanglement in learned shape space. As a result, reconstructed shapes vary along input pose and have poor accuracy. We address this problem by taking a novel domain adaptation perspective, and propose an effective adversarial domain confusion method to learn pose-disentangled compact shape space. Experiments on single-view reconstruction show effectiveness in solving pose entanglement, and the proposed method achieves state-of-the-art reconstruction accuracy with high efficiency.

[8] Deformation-Aware 3D Model Embedding and Retrieval
变形感知的3D模型嵌入和检索
Stanford: Mikaela Angelina Uy, et al.
https://arxiv.org/pdf/2004.01228.pdf
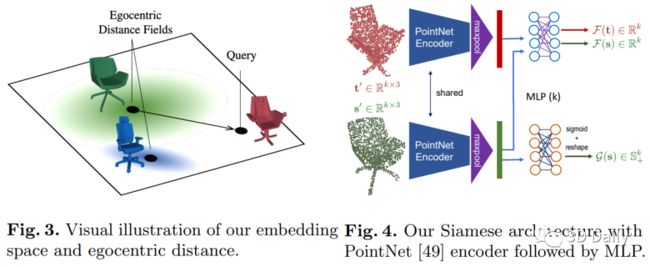
We introduce a new problem of retrieving 3D models that are not just similar but are deformable to a given query shape. We then present a novel deep deformation-aware embedding to solve this retrieval task. 3D model retrieval is a fundamental operation for recovering a clean and complete 3D model from a noisy and partial 3D scan. However, given a finite collection of 3D shapes, even the closest model to a query may not be a satisfactory reconstruction. This motivates us to apply 3D model deformation techniques to adapt the retrieved model so as to better fit the query. Yet, certain restrictions are enforced in most 3D deformation techniques to preserve important features of the original model that prevent a perfect fitting of the deformed model to the query. This gap between the deformed model and the query induces asymmetric relationships among the models, which cannot be dealt with typical metric learning techniques. Thus, to retrieve the best models for fitting, we propose a novel deep embedding approach that learns the asymmetric relationships by leveraging location-dependent egocentric distance fields. We also propose two strategies for training the embedding network. We demonstrate that both of these approaches outperform other baselines in both synthetic evaluations and real 3D object reconstruction.
[9] Characterization of Multiple 3D LiDARs for Localization and Mapping using Normal Distributions Transform
使用正态分布变换表征多个3D LiDAR 的定位和制图模型[ITSC20]
Nagoya University: Alexander Carballo, et al.
https://arxiv.org/pdf/2004.01374.pdf
https://sites.google.com/g.sp.m.is.nagoya-u.ac.jp/libre-dataset [Dataset]
In this work, we present a detailed comparison of ten different 3D LiDAR sensors, covering a range of manufacturers, models, and laser configurations, for the tasks of mapping and vehicle localization, using as common reference the Normal Distributions Transform (NDT) algorithm implemented in the self-driving open source platform Autoware. LiDAR data used in this study is a subset of our LiDAR Benchmarking and Reference (LIBRE) dataset, captured independently from each sensor, from a vehicle driven on public urban roads multiple times, at different times of the day. In this study, we analyze the performance and characteristics of each LiDAR for the tasks of (1) 3D mapping including an assessment map quality based on mean map entropy, and (2) 6-DOF localization using a ground truth reference map.

[10] Intrinsic Point Cloud Interpolation via Dual Latent Space Navigation
通过双重潜在空间导航的本征点云插值
Ecole Polytechnique: Marie-Julie Rakotosaona and Maks Ovsjanikov.
https://arxiv.org/pdf/2004.01661.pdf
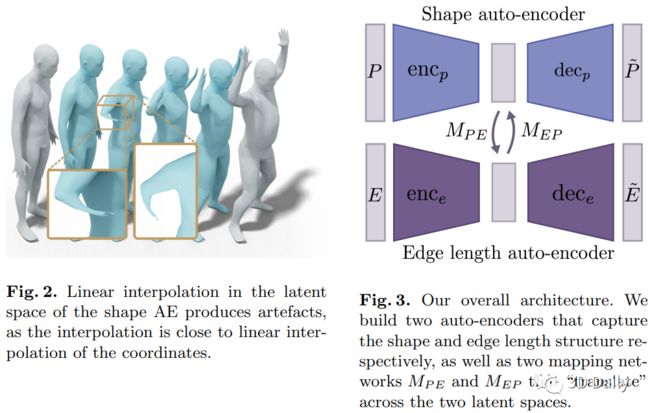
We present a learning-based method for interpolating and manipulating 3D shapes represented as point clouds, that is explicitly designed to preserve intrinsic shape properties. Our approach is based on constructing a dual encoding space that enables shape synthesis and, at the same time, provides links to the intrinsic shape information, which is typically not available on point cloud data. Our method works in a single pass and avoids expensive optimization, employed by existing techniques. Furthermore, the strong regularization provided by our dual latent space approach also helps to improve shape recovery in challenging settings from noisy point clouds across different datasets. Extensive experiments show that our method results in more realistic and smoother interpolations compared to baselines.
[11] Quantifying Data Augmentation for LiDAR based 3D Object Detection
基于LiDAR的3D物体检测的量化数据增强
ETH: Martin Hahner, et al.
https://arxiv.org/pdf/2004.01643.pdf
https://www.trace.ethz.ch/publications/2020/data_augmentation/ [Coming soon]
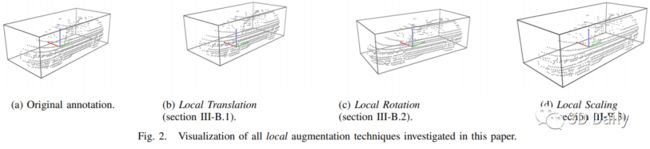
In this work, we shed light on different data augmentation techniques commonly used in Light Detection and Ranging (LiDAR) based 3D Object Detection. We, therefore, utilize a state of the art voxel-based 3D Object Detection pipeline called PointPillars and carry out our experiments on the well established KITTI dataset. We investigate a variety of global and local augmentation techniques, where global augmentation techniques are applied to the entire point cloud of a scene and local augmentation techniques are only applied to points belonging to individual objects in the scene. Our findings show that both types of data augmentation can lead to performance increases, but it also turns out, that some augmentation techniques, such as individual object translation, for example, can be counterproductive and can hurt overall performance. We show that when we apply our findings to the data augmentation policy of PointPillars we can easily increase its performance by up to 2%.
[12] Cell Segmentation and Tracking using Distance Transform Predictions and Movement Estimation with Graph-Based Matching
使用距离变换预测和运动估计以及基于图的匹配进行细胞分割和跟踪
Karlsruhe Institute of Technology: Tim Scherr, et al.
https://arxiv.org/pdf/2004.01486.pdf
In this paper, we present the approach used for our IEEE ISBI 2020 Cell Tracking Challenge contribution (team KIT-Sch-GE). Our method consists of a segmentation and a tracking step that includes the correction of segmentation errors (tracking by detection method). For the segmentation, deep learning-based predictions of cell distance maps and novel neighbor distance maps are used as input for a watershed post-processing. Since most of the provided Cell Tracking Challenge ground truth data are 2D, a 2D convolutional neural network is trained to predict the distance maps. The tracking is based on a movement estimation in combination with a matching formulated as a maximum flow minimum cost problem.

上述内容,如有侵犯版权,请联系作者,会自行删文。
推荐阅读:
吐血整理|3D视觉系统化学习路线
那些精贵的3D视觉系统学习资源总结(附书籍、网址与视频教程)
超全的3D视觉数据集汇总
大盘点|6D姿态估计算法汇总(上)
大盘点|6D姿态估计算法汇总(下)
机器人抓取汇总|涉及目标检测、分割、姿态识别、抓取点检测、路径规划
汇总|3D点云目标检测算法
汇总|3D人脸重建算法
那些年,我们一起刷过的计算机视觉比赛
总结|深度学习实现缺陷检测
深度学习在3-D环境重建中的应用
汇总|医学图像分析领域论文
大盘点|OCR算法汇总
汇总|3D点云目标检测算法
重磅!3DCVer-知识星球和学术交流群已成立
3D视觉从入门到精通知识星球:针对3D视觉领域的知识点汇总、入门进阶学习路线、最新paper分享、疑问解答四个方面进行深耕,更有各类大厂的算法工程人员进行技术指导,700+的星球成员为创造更好的AI世界共同进步,知识星球入口:
学习3D视觉核心技术,扫描查看介绍,3天内无条件退款

圈里有高质量教程资料、可答疑解惑、助你高效解决问题
欢迎加入我们公众号读者群一起和同行交流,目前有3D视觉、CV&深度学习、SLAM、三维重建、点云后处理、自动驾驶、CV入门、三维测量、VR/AR、3D人脸识别、医疗影像、缺陷检测、行人重识别、目标跟踪、视觉产品落地、视觉竞赛、车牌识别、硬件选型、学术交流、求职交流等微信群,请扫描下面微信号加群,备注:”研究方向+学校/公司+昵称“,例如:”3D视觉 + 上海交大 + 静静“。请按照格式备注,否则不予通过。添加成功后会根据研究方向邀请进去相关微信群。原创投稿也请联系。

▲长按加群或投稿