京东2019春招Java开发类笔试题
京东2019春招Java开发类笔试题
1. (单选题) 在对问题的解空间树进行搜索的方法中,一个结点有多次机会成为活结点的是 ( B )
A. 动态规划
B. 回溯法
C. 分支限界法
D. 回溯法和分支限界法
回溯法:
1)(求解目标)回溯法的求解目标是找出解空间中满足约束条件的一个解或所有解。
2)(搜索方式 深度优先 )回溯法会搜索整个解空间,当不满条件时,丢弃,继续搜索下一个儿子结点,如果所有儿子结点都不满足,向上回溯到它的父节点。
分支限界法:
1)(求解目标)分支限界法的目标一般是在满足约束条件的解中找出在某种意义下的最优解,也有找出满足约束条件的一个解。
2)(搜索方式)分支限界法以广度优先 或以最小损耗优先的方式搜索解空间。
3)常见的两种分支界限法
a.队列式(FIFO)分支界限法(广度优先):按照队列先进先出原则选取下一个结点为扩展结点
b.优先队列式分支限界法(最小损耗优先):按照优先队列规定的优先级选取优先级最高的结点成为当前扩展结点
2.(不定项选择题)在算法设计中,通常要注意理解其本质含义。算法的基本要素有( B C )
A. 算法对硬件的基本要求
B. 对数据对象的运算和操作
C. 算法的控制结构
D. 算法的数据结构
3. 递归算法x(8)需要调用几次函数x(int n) ( C )
class program
{
static void Main(string[] args)
{
int i;
i = x(x(8));
}
static int x(int n)
{
if (n <= 3)
return 1;
else
return x(n - 2) + x(n - 4) + 1;
}
}
A. 9
B. 12
C. 18
D. 24
x(8) = x(6)+ x(4) +1 = 9
x(6) = x(4)+ x(2) +1 = 5
x(4) = x(2)+ x(0) +1 = 3
以上共调用 x(int n) 函数 9 次,之后再计算 x(9)
x(9) = x(7)+ x(5) +1 = 9
x(7) = x(5)+ x(3) +1 = 5
x(5) = x(3)+ x(1) +1 = 3
同样,调用
x(int n) 函数 9 次
故,总共调用函数18次,选C。
4. 下列叙述中,有关线性链表叙述正确的是( D )
A. 线性链表中的表头元素一定存储在其他元素的前面
B. 线性链表中的各元素在存储空间中的位置不一定是连续的,但表头元素一定存储在其他元素的前面
C. 线性链表中的各元素在存储空间中的位置必须是连续的
D. 线性链表中的各元素在存储空间中的位置不一定是连续的,且各元素的存储顺序也是任意的
线性链表包括:单向链表,循环链表, 双向循环链表
数组在内存中是连续的空间 链表不是
5. 串的朴素模式匹配算法,主要思想是对主串(S)的每一个字符作为子串(T)开头,与要匹配的字符串进行匹配。主串(S)的长度为n,要匹配的子串的长度为m,那么朴素模式匹配算法的最坏时间复杂度为:( C )
A. O((n-m)*m)
B. O((n+1)*m)
C. O((n-m+1)*m)
D. O((m+1)*n)
最坏时间算法也就是每次都匹配到字串的最后一位,匹配次数为m;且匹配到主串的尾部,匹配次数为n-m+1.所以结果是m*(n-m+1)
也可以使用特殊值法 假设主串长度n为2,子串长度m为1 代入即可
6. 广义表即我们通常所说的列表(lists)。它放松了对表元素的原子性限制,允许他们有自身结构。那么广义表E((a,(a,b),((a,b),c)))的长度和深度分别为:( B )
A. 2和4
B. 1和4
C. 1和3
D. 2和3
广义表长度的求法:长度的求法为最大括号中的逗号数加1。
广义表深度的求法:深度的求法为每个元素的括号匹配数加1的最大值。
7. 关于TCP协议的描述,以下错误的是?( B )
A. 面向连接
B. 可提供多播服务
C. 可靠交付
D. 报文头部长,传输开销大
广播和多播仅应用于UDP;TCP是一个面向连接的协议
8. 在 bash shell 环境下,当一命令正在执行时,按下 control-Z 会:( C )
A. 中止前台任务
B. 给当前文件加上EOF
C. 将前台任务转入后台
D. 注销当前用户
ctrl-c:发送 SIGINT 信号给前台进程组中的所有进程。常用于终止正在运行的程序;
ctrl-z:发送 SIGTSTP信号给前台进程组中的所有进程,常用于挂起一个进程;
ctrl-d:不是发送信号,而是表示一个特殊的二进制值,表示 EOF,作用相当于在终端中输入exit后回车;
ctrl-\:发送 SIGQUIT 信号给前台进程组中的所有进程,终止前台进程并生成 core 文件;
ctrl-s:中断控制台输出;
ctrl-q:恢复控制台输出;
ctrl-l:清屏
9. 对象间存在一对多关系,当一个对象被修改时,则会自动通知它的依赖对象,采用以下哪种设计模式最好? ( B )
A. 建造者模式
B. 观察者模式
C. 策略模式
D. 代理模式
观察者模式:对象间存在一对多关系,如果一个对象被修改时,会自动通知它的依赖对象。
建造者模式:使用对各简单的对象一步一步构建出一个复杂对象
代理模式:指一个类别可以作为其他东西的接口
策略模式:将每一个算法封装起来,使得每个算法可以相互替代,使得算法本身和使用算法的客户端分割开来相互独立
10. 文件目录data当前权限为rwx | - - - | - - - ,只需要增加用户组可读权限,但不允许写操作,具体方法为: ( A )
A. chmod+050 data
B. chmod+040 data
C. chmod+005 data
D. chmod+004 data
使用chomd命令改变文件权限。
Linux文件基本权限有9个,owner,group,others三种身份对应各自read,write,execute三种权限。
文件权限字符:“-rwxrwxrwx”三个一组。数字化r:4 w:2 x:1
增加用户组可读,但不可写,第一组和第三组默认为0,只在第二组中添加r-x即可 chomd +050
11. 执行以下shell语句,可以生成/test文件的是(假定执行前没有/test文件): ( A B C )
A. touch /test
B. a=`touch /test`
C. >/test
D. echo ‘touch /test’
B选项是表示转义,
中的的内容会被执行,即执行touch /test创建一个文件
C选项是输出重定向,将要输出的内容写入/test中,若是没有/test文件则创建再写入
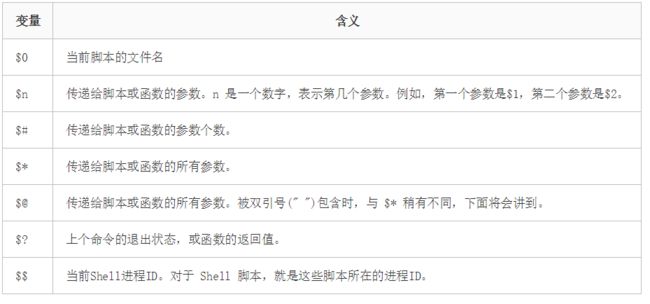
12. 以下语句可以用来获取shell脚本参数的是( A B )
A. $1
B. $?
C. $*
D. $$
13. 以下属于Redis支持的数据类型是( A B C D )
A. String
B. List
C. Set
D. 集合排序
Redis支持五种数据类型:string(字符串),hash(哈希),list(列表),set(集合)及zset(sorted set:有序集合)。
14. 关于redis下面说法错误的是( B )
A. Redis主要消耗内存资源
B. Redis集群使用一致性hash
C. Redis集群之间是异步复制的
D. 分区可以让Redis管理更大的内存
Redis Cluster在设计中没有使用一致性哈希(Consistency Hashing),而是使用数据分片引入哈希槽(hash slot)来实现
15. 以下哪个区域不属于新生代?( C )
A. eden区
B. from区
C. 元数据区
D. to区
Java 中的堆是 JVM 所管理的最大的一块内存空间,主要用于存放各种类的实例对象。
在 Java 中,堆被划分成两个不同的区域:新生代 ( Young )、老年代 ( Old )。新生代 ( Young ) 又被划分为三个区域:Eden、From Survivor、To Survivor。
这样划分的目的是为了使 JVM 能够更好的管理堆内存中的对象,包括内存的分配以及回收。
堆的内存模型大致为:
从图中可以看出: 堆大小 = 新生代 + 老年代。其中,堆的大小可以通过参数 –Xms、-Xmx 来指定。
本人使用的是 JDK1.6,以下涉及的 JVM 默认值均以该版本为准。
默认的,新生代 ( Young ) 与老年代 ( Old ) 的比例的值为 1:2 ( 该值可以通过参数 –XX:NewRatio 来指定 ),即:新生代 ( Young ) = 1/3 的堆空间大小。
老年代 ( Old ) = 2/3 的堆空间大小。其中,新生代 ( Young ) 被细分为 Eden 和 两个 Survivor 区域,这两个 Survivor 区域分别被命名为 from 和 to,以示区分。
默认的,Edem : from : to = 8 : 1 : 1 ( 可以通过参数 –XX:SurvivorRatio 来设定 ),即: Eden = 8/10 的新生代空间大小,from = to = 1/10 的新生代空间大小。
JVM 每次只会使用 Eden 和其中的一块 Survivor 区域来为对象服务,所以无论什么时候,总是有一块 Survivor 区域是空闲着的。
因此,新生代实际可用的内存空间为 9/10 ( 即90% )的新生代空间。

16. 以下程序会输出什么( C )
int a =100,b=50,c=a---b,d=a---b;
System.out.println(a);
System.out.println(b);
System.out.println(c);
System.out.println(d);
A. 100 48 48 49
B. 100 49 48 52
C. 98 50 50 49
D. 98 50 50 48
该题可分为2种情况:a–或--b
当看成a–时,输出为98 50 50 49
当看成–b时,输出为100 48 51 52
对比发现只有C选项符合
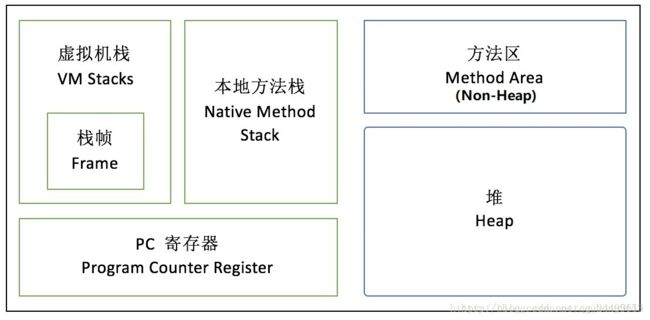
17. JVM内存不包含如下哪个部分( D )
A. Stacks
B. PC寄存器
C. Heap
D. Heap Frame
18. 后端获取数据,向前端输出过程中,以下描述正确的是( D )
A. 对于前端过滤过的参数,属于可信数据,可以直接输出到前端页面
B. 对于从数据库获得的数据,属于可信数据,可以直接输出到前端页面
C. 对于从用户上传的Excel等文件解析出的数据,属于可信数据,可以直接输出到前端页面
D. 其它选项都不属于可信数据,输出前应该采用信息安全部发布的XSSFilter做进行相应编码
19. java8中,下面哪个类用到了解决哈希冲突的开放定址法( C )
A. LinkedHashSet
B. HashMap
C. ThreadLocal
D. TreeMap
ThreadLocalMap中使用开放地址法来处理散列冲突,而HashMap中使用的是分离链表法。之所以采用不同的方式主要是因为:在ThreadLocalMap中的散列值分散得十分均匀,很少会出现冲突。并且ThreadLocalMap经常需要清除无用的对象,使用纯数组更加方便。
Hashset和Hashmap通常是使用分离链表法实现的。
20. 当我们需要所有线程都执行到某一处,才进行后面的的代码执行我们可以使用?( A/B )
A. CountDownLatch
B. CyclicBarrier
C. Semaphore
D. Future
CountDownLatch 允许一个线程或多个线程等待特定情况,同步完成线程中其他任务。举例:百米赛跑,就绪运动员等待发令枪发动才能起步。
CyclicBarrier 和CountDownLatch一样都可以协同多个线程,让指定数量的线程等待期他所有的线程都满足某些条件之后才继续执行。举例:排队上摩天轮时,每到齐四个人,就可以上同一个车厢。
21. 下列说法正确的是( C )
A. volatile,synchronized 都可以修改变量,方法以及代码块
B. volatile,synchronized 在多线程中都会存在阻塞问题
C. volatile能保证数据的可见性,但不能完全保证数据的原子性,synchronized即保证了数据的可见性也保证了原子性
D. volatile解决的是变量在多个线程之间的可见性、原子性,而sychroized解决的是多个线程之间访问资源的同步性
synchronized关键字和volatile关键字比较:
1、volatile关键字是线程同步的轻量级实现,所以volatile性能肯定比synchronized关键字要好。但是volatile关键字只能用于变量而synchronized关键字可以修饰方法以及代码块。synchronized关键字在JavaSE1.6之后进行了主要包括为了减少获得锁和释放锁带来的性能消耗而引入的偏向锁和轻量级锁以及其它各种优化之后执行效率有了显著提升,实际开发中使用 synchronized 关键字的场景还是更多一些。
2、多线程访问volatile关键字不会发生阻塞,而synchronized关键字可能会发生阻塞
3、volatile关键字能保证数据的可见性,但不能保证数据的原子性。synchronized关键字两者都能保证。
4、volatile关键字主要用于解决变量在多个线程之间的可见性,而 synchronized关键字解决的是多个线程之间访问资源的同步性。
5、synchronized: 具有原子性,有序性和可见性;(三个都有)
volatile:具有有序性和可见性(缺一个原子性)
22. 关于Java中参数传递的说法,哪个是错误的?( D )
A. 在方法中,修改一个基础类型的参数不会影响原始参数值
B. 在方法中,改变一个对象参数的引用不会影响到原始引用
C. 在方法中,修改一个对象的属性会影响原始对象参数
D. 在方法中,修改集合和Maps的元素不会影响原始集合参数
A、在方法中,修改一个基础类型的参数永远不会影响原始参数值。
B、在方法中,改变一个对象参数的引用永远不会影响到原始引用。然而,它会在堆中创建了一个全新的对象。(译者注:指的是包装类和immutable对象)
C、在方法中,修改一个对象的属性会影响原始对象参数。
D、在方法中,修改集合和Maps会影响原始集合参数。
23. spring默认使用jdk动态代理,那么下面哪个配置是开启强制使用cglib代理( A )
A.
B.
C.
D.
Spring2.0:
Spring AOP部分使用JDK动态代理或者CGLIB来为目标对象创建代理。(建议尽量使用JDK的动态代理)
如果被代理的目标对象实现了至少一个接口,则会使用JDK动态代理。所有该目标类型实现的接口都将被代理。若该目标对象没有实现任何接口,则创建一个CGLIB代理。
如果你希望强制使用CGLIB代理,(例如:希望代理目标对象的所有方法,而不只是实现自接口的方法)那也可以。但是需要考虑以下问题:
无法通知(advise)Final 方法,因为他们不能被覆写。
你需要将CGLIB 2二进制发行包放在classpath下面,与之相较JDK本身就提供了动态代理
强制使用CGLIB代理需要将 |aop:config| 的 proxy-target-class 属性设为true:
|aop:config proxy-target-class=“true”|
…
|/aop:config|
当需要使用CGLIB代理和@AspectJ自动代理支持,请按照如下的方式设置 |aop:aspectj-autoproxy| 的 proxy-target-class 属性:
|aop:aspectj-autoproxy proxy-target-class=“true”/|
参考链接
https://blog.csdn.net/scholar_man/article/details/80900212
https://www.jianshu.com/p/c738c8262087
https://www.nowcoder.com/profile/4821886/test/27867260/369684