微信小程序——图片识别
我的微信小程序 期末大作业——基于百度大脑API的图片识别小程序
具体实现了动物识别、植物识别、车辆识别 三个功能
实验源码已经放到了我的GitHub,欢迎测试修改 (项目地址:https://github.com/ZHJ0125/ImageMaster)
下面给大家分享该项目的实验报告
目录
- 1 概述
- 1.1 课程大作业目的与要求
- 1.2 课程大作业简介
- 2 设计思路
- 2.1 图片识别API
- 2.2 微信小程序UI框架
- 3 设计方案
- 4 设计过程
- 4.1 百度开放平台注册
- 4.2 获取asscee_token
- 4.3 图片上传
- 4.4 图片格式转化
- 4.5 API请求
- 4.6 实现植物识别
- 4.7 实现车辆识别
- 4.8 Taro样式测试
- 4.9 WeUI样式测试
- 5 关键问题
- 6 使用说明
1 概述
1.1 课程大作业目的与要求
课程大作业的目的是:运用在本次课程中学到的知识来指导实践,了解程序设计其实现方法,学会解决实际问题。掌握微信小程序设计的具体步骤与基本方法,针对选定的程序做调研分析。通过课程大作业,提高实践动手技能,培养独立分析分析问题和解决问题的能力。
课程大作业的要求:本次课程大作业的选题比较灵活,可以是自主选题,也可以参考课本中的案例自行修改完善,题目要符合课程大作业的要求,并且具备一定的水平和深度。
1.2 课程大作业简介
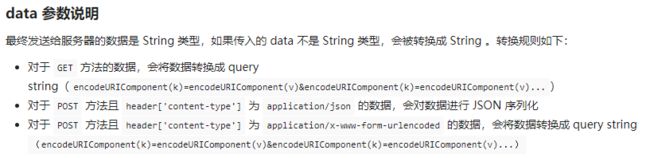
图像识别是指利用计算机对图像进行处理、分析和理解,以识别各种不同模式的目标和对像的技术。在众多的图像识别分支中,拍照识别是一个重要的应用。利用图像识别技术,识别拍摄到的图片内容,已经广泛应用于各类图像识别App中。
微信小程序是一种不需要下载安装即可使用的应用,它实现了应用的“触手可及”和“即用即走”,用户扫一扫或搜一下即可打开应用。利用微信小程序使用便捷的特点,结合图片识别应用,本次大作业选定了制作微信小程序的图片识别应用——ImageMaster。本应用实现了基于微信小程序的动植物识别和车辆识别,使用便捷,充分发挥了微信小程序“即用即走”的特点。
同时,本次大作业项目制作过程只用了Git进行进度跟踪,便于进行版本回退和功能更新。
2 设计思路
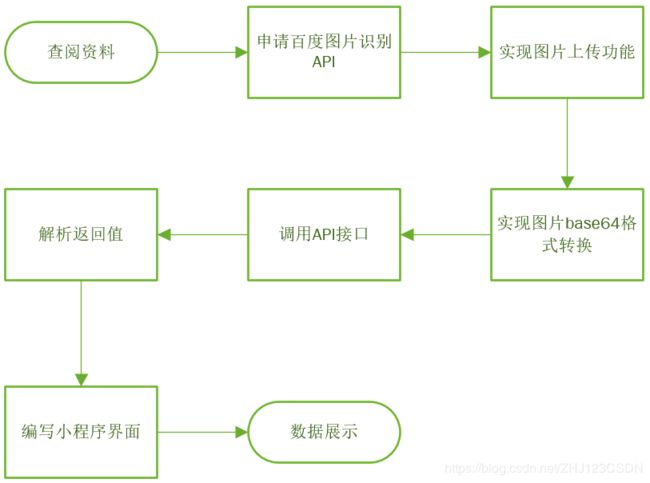
根据初步选定的设计题目,查找相关资料,针对系统所涉及内容,查阅相关背景知识,将设计思路在此做一个概括。
本课题需要实现一个基本的图片识别应用,实现动物识别、植物识别和车辆识别三种主要功能。查阅的资料主要包括两方面:图片识别API的选择以及微信小程序UI框架的选择。
2.1 图片识别API
首先需要查阅图片识别API的相关资料,以便确定课题最终使用哪个API。下面我将在接口能力、是否有参考例程、个人评价三方面简要分析一下常见的几种图片识别API。
百度大脑
- 接口能力
表2-1 百度图片识别API接口能力
| 接口名称 | 接口能力简要描述 |
|---|---|
| 图像主体检测 | 识别图像中的主体具体坐标位置。 |
| 通用物体和场景识别高级版 | 识别图片中的场景及物体标签,支持10w+标签类型。 |
| 菜品识别 | 检测用户上传的菜品图片,返回具体的菜名、卡路里、置信度信息。 |
| 自定义菜品识别 | 入库自定义的单菜品图,实现上传多菜品图的精准识别,返回具体的菜名、位置、置信度 |
| logo商标识别 | 识别图片中包含的商品LOGO信息,返回LOGO品牌名称、在图片中的位置、置信度。 |
| 动物识别 | 检测用户上传的动物图片,返回动物名称、置信度信息。 |
| 植物识别 | 检测用户上传的植物图片,返回植物名称、置信度信息。 |
| 果蔬食材识别 | 检测用户上传的果蔬类图片,返回果蔬名称、置信度信息。 |
| 地标识别 | 检测用户上传的地标图片,返回地标名称。 |
| 红酒识别 | 识别图像中的红酒标签,返回红酒名称、国家、产区、酒庄、类型、糖分、葡萄品种等信息。 |
| 货币识别 | 识别图像中的货币类型,返回货币名称、代码、面值、年份信息,可识别百余种国内外常见货币。 |
- 调用方式
API 和 SDK 两种方式,SDK文档包含 Java、PHP、Python、C#、C++、Node语言,有丰富的 Demo。
腾讯AI开放平台
接口包含OCR、人体与人脸识别、物体识别、图片特效、图片识别、敏感信息审核、闲聊机器人、基础文本分析、语义解析、语音识别 等等,有 PHP 参考例程。
华为HiAI
接口包含人脸识别、人体识别、图片识别、图像分辨率、场景识别、文档检测矫正、人像分割、视频语音等等。有详细的开发指南,但是其针对的是 Android 手机平台的开发。
旷世 Face++
接口包含人脸识别、人体识别、证件识别、图像识别,拥有详细的开发指南。
综合比较之后,决定采用百度大脑 API平台。
2.2 微信小程序UI框架
查阅各种微信小程序UI框架资料,决定使用哪种 UI 框架作为本项目的UI框架。
-
WeUI
- 项目地址
- 简介
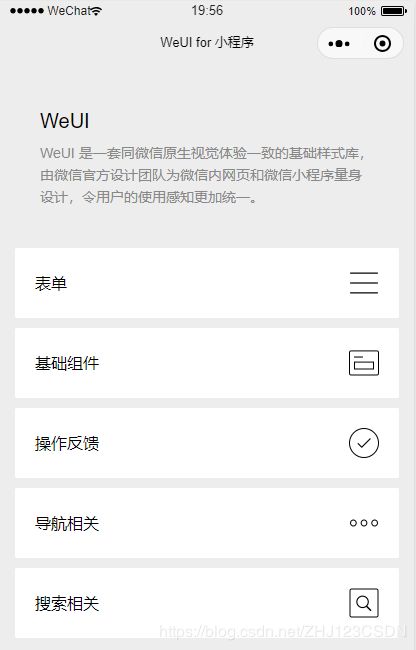
WeUI 是一套同微信原生视觉体验一致的基础样式库,由微信官方设计团队为微信内网页和微信小程序量身设计,令用户的使用感知更加统一。包含button、cell、dialog、 progress、 toast、article、actionsheet、icon等各式元素。 - 使用体验
毕竟是微信官方提供的UI框架,界面肯定是与微信小程序的适配度最好。但是感觉没有特别的亮点。
-
Vant Weapp
- 项目地址
- 简介
Vant Weapp 是有赞移动端组件库 Vant 的小程序版本,两者基于相同的视觉规范,提供一致的 API 接口,助力开发者快速搭建小程序应用。 - 使用体验
组件分类做得不错,样式也很简洁美观。
-
iView Weapp
- 项目地址
- 简介
一套高质量的微信小程序 UI 组件库 - 使用体验
界面简单,没亮点。
-
MinUI
- 项目地址
- 简介
MinUI 是基于微信小程序自定义组件特性开发而成的一套简洁、易用、高效的组件库,适用场景广。覆盖小程序原生框架,各种小程序组件主流框架等,并且提供了专门的命令行工具 - 使用体验
组件还算齐全,没有亮点。官方Demo还有广告链接。
-
Wux Weapp
- 项目地址
- 简介
Wux Weapp 是一套组件化、可复用、易扩展的微信小程序 UI 组件库。UI 样式可配置,拓展灵活,轻松适应不同的设计风格。60多个丰富的组件,能够满足移动端开发的基本需求。 - 使用体验
没有特别炫酷的效果,但组件齐全。
-
ColorUI
- 项目地址
- 简介
鲜亮的高饱和色彩,专注视觉的小程序组件库。 - 使用体验
功能齐全,各种组件分类明确。
-
Taro UI
- 项目地址
- 简介
一款基于 Taro 框架开发的多端 UI 组件库。基于 Taro 开发 UI 组件一套组件,可以在微信小程序,支付宝小程序,百度小程序,H5 多端适配运行(ReactNative 端暂不支持)。提供友好的 API,可灵活的使用组件。 - 使用体验
界面简介,功能丰富。
经过亲自体验各种UI框架的官方Demo,最后感觉 Taro UI 使我印象很深刻。界面简洁,组件分类明确。我起初决定使用 Taro UI 框架,但是在项目进行到UI设计阶段,发现Taro使用有些许难度,为简化开发过程,最终使用了微信小程序的官方UI框架——WeUI框架。
3 设计方案
在需求分析的基础上,查阅资料,对在小程序设计中可能用到的相关技术做一定的调研分析,做一个概要性的描述。
因为微信小程序本身就是联网的应用平台,因此在微信小程序平台进行图片识别,就不必担心网络连接问题。从源头上追溯,实现图片识别需要用户首先上传图片或拍摄图片,需要解决图片上传问题;之后发送API请求时,图片需要作为请求的参数,需要解决图片转码的问题;最后API请求调用成功后,需要将识别的数据输出,就涉及数据处理以及UI界面设计的问题。通过解决关键的“图片上传”、“图片转码”、“API调用”、“界面设计”这几个问题,就可以实现基本的图片识别小程序了。
4 设计过程
根据初步选定的课程大作业程序设计题目,查找相关资料,结合课本中的案例以及前期的学习,整理设计过程。
4.1 百度开放平台注册
首先登陆百度智能云平台,同意它的服务条款。
之后填写相关的信息,在控制台概览中创建应用。
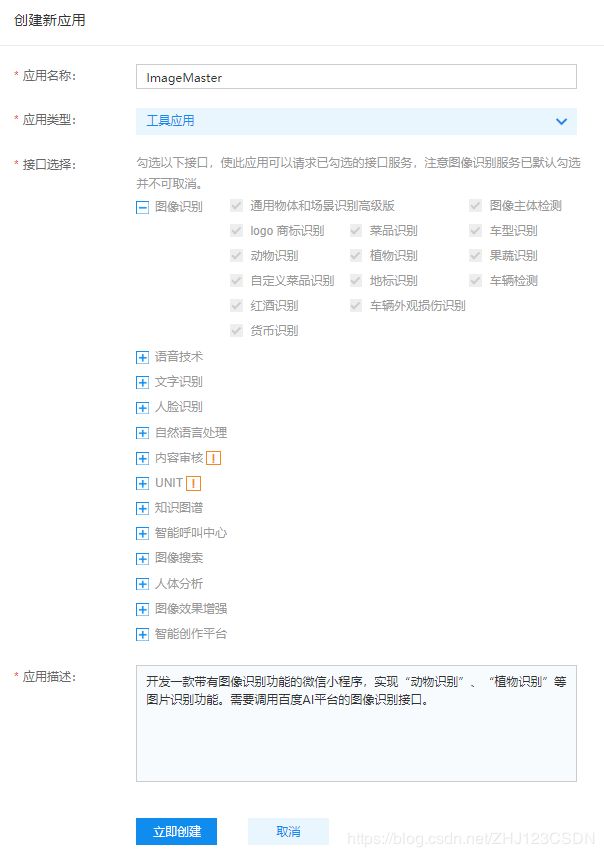
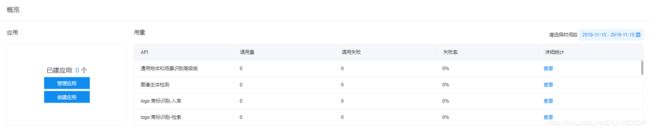
现在已经申请好了百度的API接口,下面尝试在微信小程序中进行调用。
4.2 获取asscee_token
在百度AI的官方文档中可以看到,这个API接口有两种调用方式,两种不同的调用方式有相同的接口URL地址,区别在于请求方式和鉴权方式不同。下面我将尝试使用微信小程序中常用的POST请求方式,调用该接口。
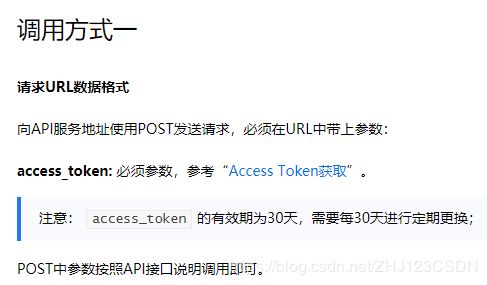
在官方文档中可以看到,使用post请求需要用到access_token,所以现在去查看如何获取access_token。
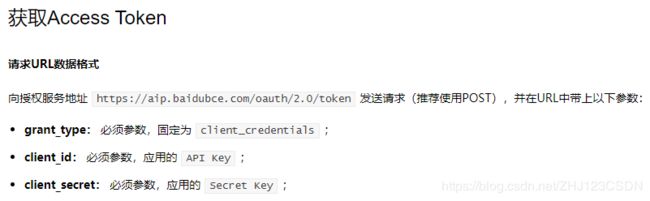
获取access_token需要下个授权的服务器地址发送post请求,使用固定的参数,即可得到服务器返回的json数据。

下面就开始进行小程序的编写,实现access_token的获取。
首先,在空的小程序中添加一个按钮,在按钮按下后,调用wx.request方法向服务器发送POST请求。
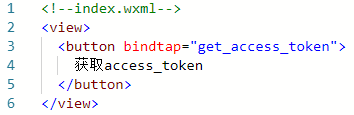
按钮绑定事件处理函数,这个事件处理函数就是用来发送POST请求的。
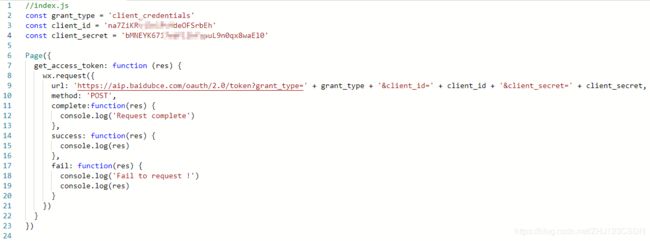
上面图片就是编写的事件处理函数,利用wx.request方法,请求百度API的URL地址,请求方式按要求是POST方式。然后分别编写了请求完成、请求成功、请求失败的回调函数,目的就是让我能在控制台中看到请求的状态。
下面就需要在微信小程序的后台添加合法域名,以便wx.request方法能够正确使用。
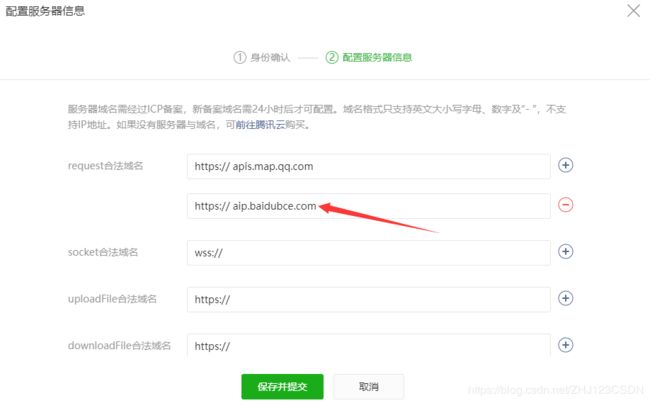
箭头所指的就是百度大脑的请求网址,上面那个URL是以前做地图API添加的,这里没有用到。运行模拟器之后成功获取到了access_token的值。
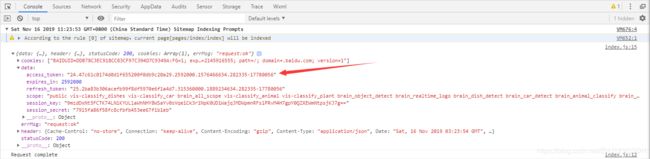
可以看到,控制台执行了success回调函数,成功返回了access_token。现在Access_token的问题已经解决了。接下来就要尝试去请求百度图片识别的API接口了。
通过阅读百度大脑API接口文档,我大概理解了百度API的接口使用方式。看一下下面的API文档的截图就可以了解其流程。
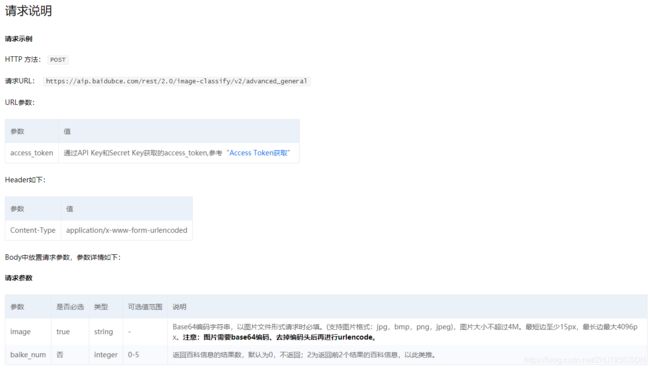
我们首先需要使用微信封装的request方法请求这个API的URL地址,注意要使用该POST方式。然后这个URL的具体内容就是文档中给出的地址,不同的API接口有不同的请求地址。URL地址需要添加一些参数,如access_token、Content-Type等等。同时,还需要一个image参数作为图片的标识,这个image是将图片转换成了base64编码的格式,也就是将图片传换成了一串字符。
再查阅微信小程序wx.request方法就可以知道,image这个参数可以通过小程序的data属性表示。这样,API接口的请求过程就可以在小程序中表示出来了。
下面尝试在小程序中进行程序编写。
首先添加一个变量“token”用来存储我获取到的access_token值,然后将success回调函数修改成下图中的代码。
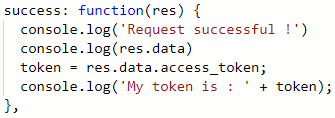
也就是将token从服务器返回的json数据中提取出来。现在,token已经存储到了变量中。
4.3 图片上传
现在有一个问题,微信小程序怎样获取图片数据呢?微信常用的方式是将用户的图片文件上传到微信开发者的服务器上,服务器接收到图片数据后再进行相关的处理。不管怎样,都首先需要使用微信提供的接口上传图片文件。那么首先研究一下怎样使用微信的图片上传接口。
微信提供了“从本地选择图片或使用相机拍照”的接口“wx.chooseImage”。
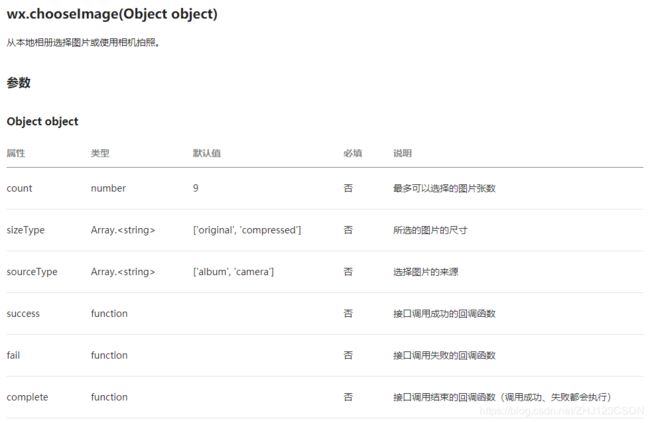
现在尝试使用该接口上传一下图片文件。在逻辑文件中编写图片上传按钮的事件处理函数。
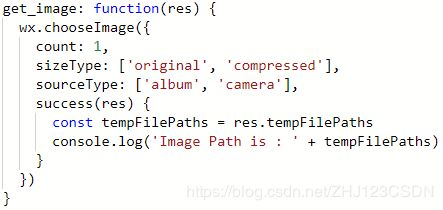
下面运行小程序,点击上传图片按钮,会弹出系统资源管理器,在里面选择图片文件点击确定,即可成功上传图片文件。在success回调函数中,把上传图片的文件路径放到变量中,再通过控制台显示出来即可。在控制台中显示了图片路径。

为了确定图片真的已经上传到了微信小程序中,我现在把上传的图片显示在小程序界面中。小程序文档中指出,tempFilePaths可以作为组件的src地址,所以显示图片就很方便了。
经过一番调试,该功能终于实现了。首先,在页面布局中添加组件,该组件的src设置为动态变量imageUrl,以便在图片上传后动态改变。之后编写相应的事件处理函数,首先添加一个默认的图片索引地址,将该图片放到向程序工程目录下,使用data属性保存其路径信息。

然后在原有的图片上传事件处理函数的基础上,编写增加代码如下:

画横线的代码是图片动态显示的关键代码。这样,就是实现了图片的上传和动态更新。PS:这部分内容参考课本P132“上传头像”部分。
4.4 图片格式转化
好的,现在就可以看一下怎样把图片转换成base64格式的数据了。
经过查找资料,发现将图片转换成base64格式的方式也有不少。我是用一种微信提供的文件管理接口实现的。在上传图片的成功回调函数中(此时已经得到了本地图片地址),使用文件系统管理方法,读取本地文件的内容。这里指定读取文件的编码格式为base64,然后通过控制台显示出来就可以了。
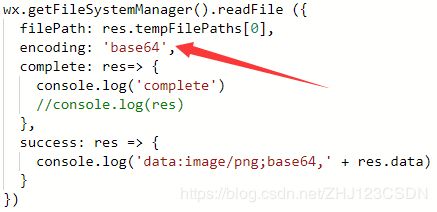
上面截了一下关键位置的代码,这部分代码是放在success回调函数中,因为回调函数中已经获取到了上传图片的本地地址。
看一下控制台的信息:

可以看到,控制台输出了图片的base64编码值。稍微了解一下base64编码,该编码可以用于HTML环境下的较长信息的标识,只要用于canvas画布的图片显示。它的好处在于,可以在没有上传图片文件的情况下,使用该编码在HTML中插入该图片。这种编码有固定的表示形式:“data:image/jpeg;base64, …”,也有固定的格式转换格式。具体的内容就不再详细研究了。在我的测试中,上传的原图片大小是20.5KB,转换成base64编码之后的数据大小为54.7KB。
4.5 API请求
图片已经准备好了,现在已经可以去调用百度图片识别的API了。下面需要对包括“access_token”、“base64编码”等数据进行整合,并以动物识别为例尝试该API的调用。
首先添加识别按钮,然后编写相应的事件处理函数。

事件处理函数就是要进行API接口调用了。
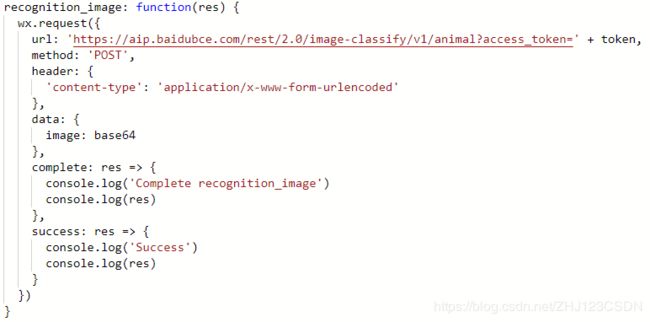
上面就是按照百度动物识别API文档的要求,结合小程序wx.request方法的属性写出来的事件处理函数。
我在网上搜了一个狗的图片,添加到了小程序文件夹中作为测试图片。运行模拟器进行测试。依次点击“获取access_token”、“上传图片”以及“识别该图片”按钮,在控制台看到API返回的数据。

可以看到,在API返回的JSON数据中,标注了识别结果,其中置信度最高的结果是“威尔士柯基”。我特意搜了一下这个“威尔士柯基”,识别结果还是挺准的。
还要测试一下非动物图片的识别情况。现在我继续上传一个头像图片进行测试,看看测试结果。可以看到,非动物也是可以被识别出来的,识别结果只有一个高置信度的“非动物”结果。

程序做到这里,可以说最大的障碍已经被克服了。目前已经实现了“动物识别”,下面就是逐步实现“植物识别”、“车型识别”等功能就可以了,他们的基本流程是一样的。
4.6 实现植物识别
现在来整理一下代码,尝试实现“植物识别”功能。
通过阅读API文档可以看出,其实这几种不同的图像识别的接口,只是URL地址不同,其他参数都是一样的。所以我设置了一个变量apiUrl用来存放不同接口的URL地址,为“植物识别”编写一个新的事件处理函数。这个事件处理函数与“动物识别”唯一的不同就是apiUrl不一样罢了。
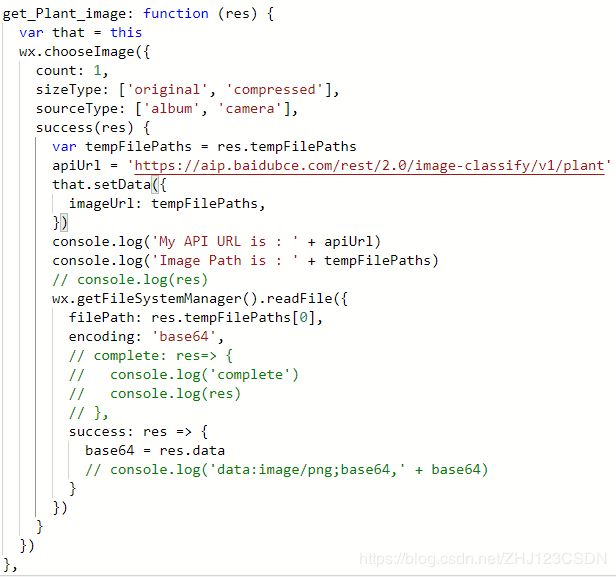
可以看到,我把请求接口的URL放到了apiUrl变量中。同时精简了控制台显示的数据,只保留关键的数据。
至于图像识别的事件处理函数,只需要把之前的POST请求地址改成用apiUrl表示就可以了。
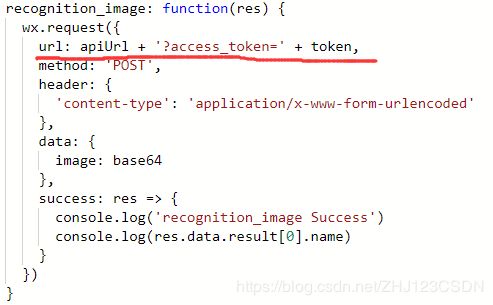
可以看到画横线的那句话,就是把POST地址改了一下,使程序的使用范围更广了。同时还要注意到,我精简了控制台的输出信息,只保留置信度最高的结果。
现在就可以识别植物了。
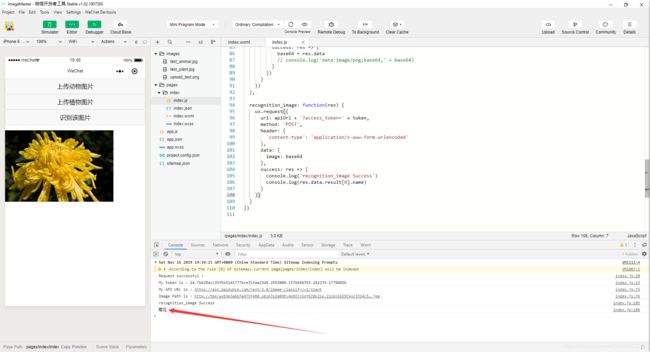
现在控制台简洁多了,而且也能正确显示置信度最高的识别结果了。
4.7 实现车辆识别
现在继续做车型识别。现在添加功能就比较简单了,只需修改apiUrl。
这时遇到了一个问题,上传图片的大小错误。

为了方便调试,我将控制台信息输出添加了条件判断语句,如果发生错误就输出错误信息,没有错误就输出识别结果。首先测试了图片大小错误的情况,然后测试了正常的图片,控制台输出的信息如下:
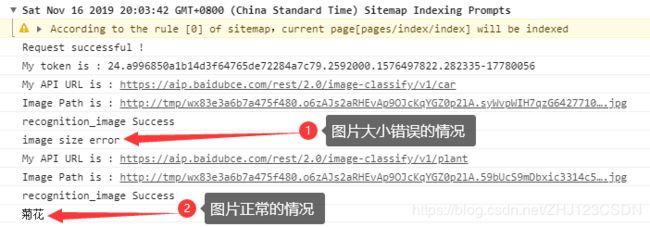
这样调试就方便多了。现在来解决图片size的问题。以“车型识别”为例,其图片要求如下:

我刚才上传的“image size error”的图片,其像素为1920px*1080px,符合文档中图片长宽的要求。原图大小为460KB,其编码为base64之后的大小为1.2MB,同样符合要求。这就奇怪了,因为这些参数都是符合文档要求的。
之后我又进行了其他测试,换了一张1920px × 1080px的图片,不会报错。所以看起来图片不合适的原因应该是图片大小的问题。然而,当我继续测试使用2048px × 1335px,原图大小为1.5MB的图片时,竟然可以正常识别。所以这张图片报错的原因暂时没有搞清楚。
先不管这里了,因为我测试了其他图片,都没有出现问题,只有这一张出现图片大小的问题。就先放一下吧。下面整理一下小程序,优化一下界面。

上图是初始化界面,调整了“识别图片”按钮和图片之间的相对位置,同时添加了文本框显示提示信息。下面以“动物识别”为例,展示识别效果。可以看到,通过添加文本框,可以直观地显示识别结果,非常方便。

下面就来编写一下样式文件吧。
4.8 Taro样式测试
- (1)Taro样式介绍
样式文件我想尝试使用UI框架编写,经过对比多种UI框架,最终决定使用Taro UI作为我的UI框架使用。以下是Taro官网介绍:
Taro 是由京东凹凸实验室打造的多端开发解决方案。现如今市面上端的形态多种多样,Web、ReactNative、微信小程序等各种端大行其道,当业务要求同时在不同的端都要求有所表现的时候,针对不同的端去编写多套代码的成本显然非常高,这时候只编写一套代码就能够适配到多端的能力就显得极为需要。使用 Taro,我们可以只书写一套代码,再通过 Taro 的编译工具,将源代码分别编译出可以在不同端(微信小程序、H5、RN等)运行的代码。
下面就按照官网的教程,尝试在本地小程序中使用该框架进行练习。为了防止原有的小程序结构被破坏,首先新建一个小程序作为练习使用。
Taro需要使用Node.js,要求版本在v8.x 或以上。但我之前安装的版本是v4.4.3,所以现在先重新安装新版本的Node.js。
![]()
经过重新安装,现在已经升级到了最新的长期支持版本V12.13.1。
![]()
下面开始项目初始化安装。
- (2)使用前的准备
首先安装Taro脚手架工具,这里需要使用npm包管理工具进行安装。
之后需要使用Yarn依赖管理工具安装相应的依赖,先来安装Yarn。对于Windows系统,可以下载官方提供的安装器进行安装。安装Taro完成后,可以使用命令安装相应的依赖。

- (3) 安装项目模板
现在到小程序工程目录下,进行Taro模板的创建。这里注意,需要提前安装python2版本。
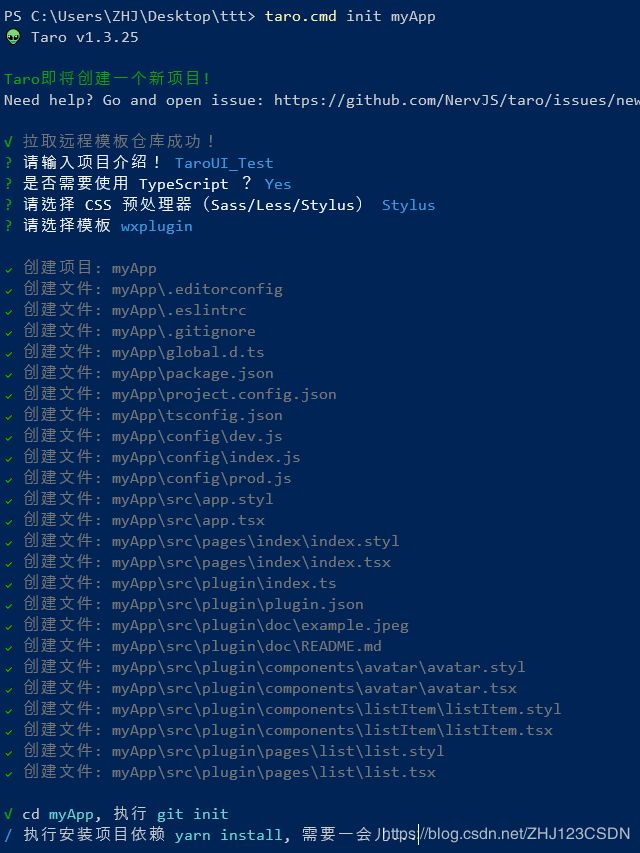
现在模板安装完成了,可以进行模块引入了。
- (4) 引入Taro模块
下面进行taro模块的导入,需要使用npm本地编译taro模块。

编译完成后,我发现taro工程的目录结构与微信小程序的工程结构不一样。而且taro的样式文件编写的格式也不是wxss格式,这就导致我还要学习一些其他的样式格式规则才能上手编写taro。为了尽快完成小程序,我转向了使用WeUI框架。
4.9 WeUI样式测试
- (1) WeUI介绍
WeUI 是一套与微信原生 UI 一致的 UI 库,核心文件是 weui.css,只需要获取到该文件,然后在页面中引入,即可使用 WeUI 的组件。首先到其GitHub网站下载源代码,新建一个工程文件用来进行测试和修改。在微信开发者工具中打开该工程。
此时模拟器中就可以查看到WeUI框架的各种组件样式。
- (2) 样例编写
下面来研究一下WeUI是怎样组织样式编写的。
以Grid样式为例,先看一下他的效果。
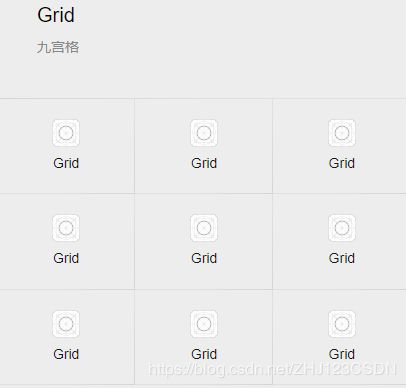
再看一下它的布局文件。
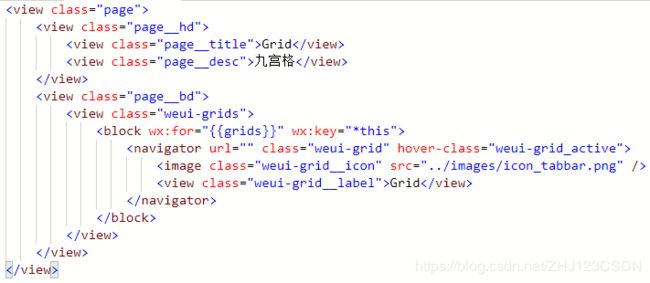
可以看到,他是直接使用了WeUI提供的class,利用wx:for循环实现Grid组件的控制。而逻辑文件中给出了grids变量数组的数据,从0到8表示循环9次,显示9个Grid宫格。

现在尝试将该样式移植到我的小程序中。移植样式最关键的就是它的weui.wxss,按照教程,可以使用外联样式引入的方式将改样式文件引入到项目中。
首先将style文件夹整体复制到我的工程目录中,然后在全局样式中导入weui的样式文件。
![]()
之后创建一个新的页面用来测试样式内容,并将其页面作为默认显示的页面。
之后就可以分别在新创建的页面中编写grid布局和逻辑文件,内容与示例代码一样。这样效果就与示例代码相似了。
官方例程中Grid的九个组件,是由组件组成的。组件用于实现页面之间的跳转,而我想要通过button组件实现用户选择不同类型图片的功能,所以需要使用button组件。下面再测试一下button组件的使用。
首先是从官方历程中抽取出我们需要的组件。
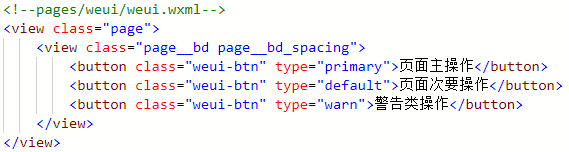
现在就需要移植一下样式文件了。在例程样式文件中找到”weui-btn”、”class”、”page__bd”、”page__bd__spacing”的文件内容,复制到本页面的样式文件中即可。最后实现的效果如下图所示。

下面尝试将原先的逻辑功能与样式结合起来。首先将样式文件复制到index.wxss文件中,然后将原先的button组件的样式改成测试时的样式。
于是模拟器中的样式就改为如下图所示:

下面修改标题文本样式,将WeUI的标题文本样式移植到我的程序中。

下面我想将这三个上传图片的按钮进行水平均匀排布,找到按钮样式相关的样式文件,修改后的样式如下图所示。

之后,我又修改了上传按钮和文字输出按钮的样式,添加了提示图片和提示信息。最终的样式如下图所示。
5 关键问题
针对完成大作业过程中遇到的问题,分析描述在此过程中的关键问题,如重点难点等。
本次大作业“微信小程序的图片识别”程序实现过程中,重点问题是“图片上传”、“图片转码”、“API调用”以及“界面设计”。其中图片上传主要使用了微信小程序中的wx.chooseImage方法;图片转码使用wx.getFileSystemMangaer方法解决;API调用使用wx.request方法实现;界面设计使用了微信小程序的官方UI框架实现。
6 使用说明
提供微信小程序体验版的访问方式(小程序码)。
下面给出完成的微信小程序的使用说明。使用体验版微信小程序,在自己的手机上进行测试。下面将测试过程及截图展示如下。
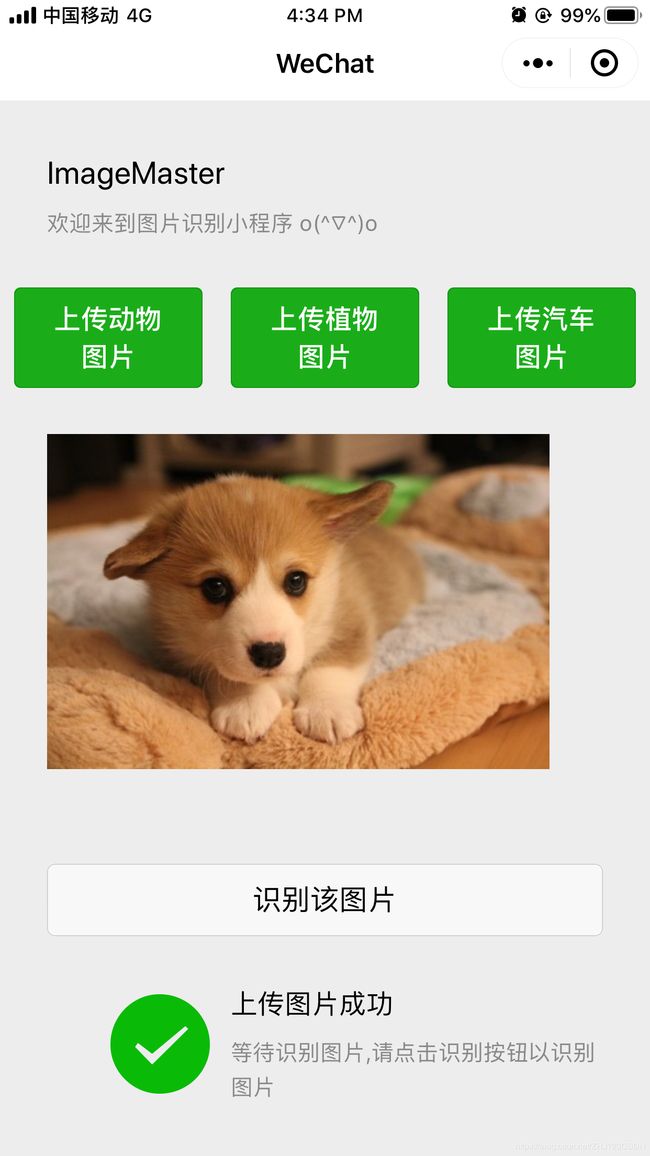
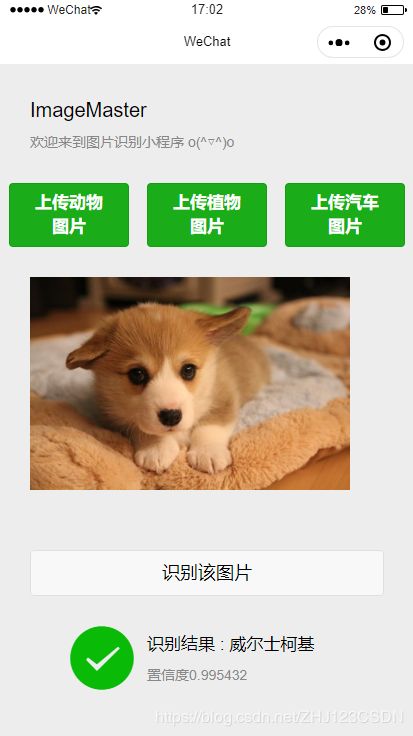
(1)上传图片
用户进入小程序后,首先需要通过相册或拍照,上传需要识别的图片。
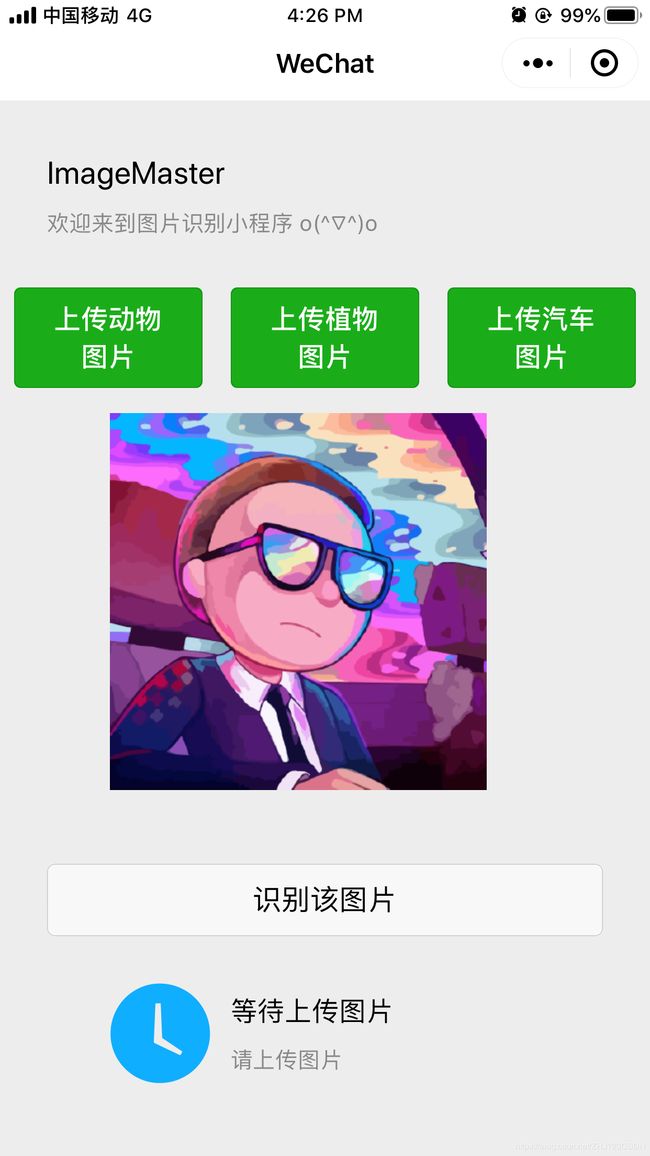
以“动物识别”为例,点击“上传动物图片”按钮,进行图片上传。
(2)选择图片
以从相册上传图片为例,点击从相册上传图片按钮,在相册中选择想要识别的图片。

(3)识别图片
上传图片完成后,点击小程序界面的“识别该图片”按钮,进行图片识别。经过短时间的等待,即可显示识别结果。
(4)识别结果
界面下方可以展示图片识别的结果。