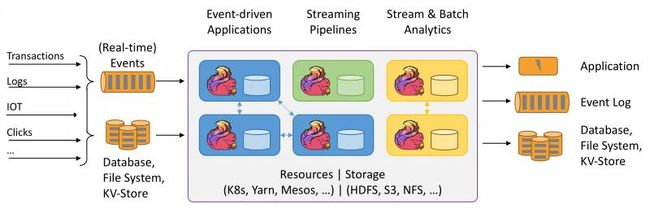
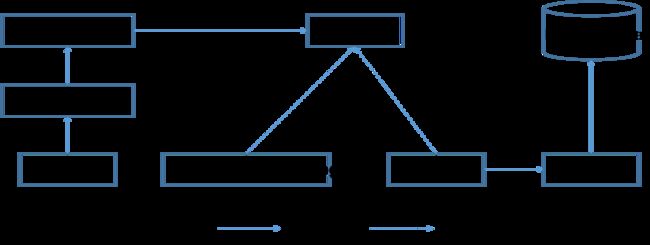
Flink 1.10.0应用场景,kakfa->flink->kafka/mysql/es/hive/hdfs

Flink 1.10通过开发将Hive集成到Flink,可用于生产环境。
Flink 1.10.0
部署文档:https://blog.csdn.net/RivenDong/article/details/104416464
应用场景:
1、kafka->flink->kafka:https://mp.weixin.qq.com/s/mokYFllNwvObW65d_6EQjQ
2、Kafka->flink->mysql:https://www.jianshu.com/p/30dc0e429374
3、Kafka->flink->es:https://www.jianshu.com/p/74d5ff1f9db6
4、Kafka->flink->hive:https://www.jianshu.com/p/330a682970c8
5、Kafka->flink->hdfs:https://blog.csdn.net/qq_33689414/article/details/95316664
Flink系列之1.10版流式SQL应用:http://www.gzywkj.com/post/9317.html
重要Flink SQL:
CREATE TABLE user_behavior (
userId BIGINT,
itemId BIGINT,
categoryId BIGINT,
behavior STRING,
ts TIMESTAMP(3),
proctime as PROCTIME(),
WATERMARK FOR ts as ts - INTERVAL '5' SECOND
) WITH (
'connector.type' = 'kafka',
'connector.version' = 'universal',
'connector.topic' = 'user_behaviors',
'connector.startup-mode' = 'earliest-offset',
'connector.properties.zookeeper.connect' = '**.**.**.**:2181',
'connector.properties.bootstrap.servers' = '**.**.**.**:6667',
'format.type' = 'json'
);
CREATE TABLE pvuv_sink (
dt STRING,
pv BIGINT,
uv BIGINT
) WITH (
'connector.type' = 'jdbc',
'connector.url' = 'jdbc:mysql://**.**.**.**:3306/flink-test',
'connector.table' = 'pvuv_sink',
'connector.username' = 'root',
'connector.password' = 'admin',
'connector.write.flush.max-rows' = '1'
);
INSERT INTO pvuv_sink
SELECT
DATE_FORMAT(ts, 'yyyy-MM-dd HH:00') dt,
COUNT(*) AS pv,
COUNT(DISTINCT userId) AS uv
FROM user_behavior
GROUP BY DATE_FORMAT(ts, 'yyyy-MM-dd HH:00')
CREATE TABLE mykafka(name String, age Int)
WITH('connector.type'='kafka',
'connector.version'='universal',
'connector.topic'='flinktest',
'connector.properties.zookeeper.connect'='**.**.**.**:2181',
'connector.properties.bootstrap.servers'='**.**.**.**:6667',
'format.type'='csv',
'update-mode'='append');