【Hadoop-2.7.2 入门 CentOS7】Hadoop 完全分布式集群部署_2019.9.25
完全分布式集群部署
- 完全分布式集群部署规划
- Linux配置+Hadoop环境配置
- 解压及环境配置(基础/单)
- 混合集群配置及其分发(真·完全)
- 配置文件简述
- 完全分布式集群配置
- ↓ 分发&&群起前提 ↓
- SSH免密登录
- SSH简介
- 核心:SSH-RSA配置
- ↓分发前提2↓
- 虚拟机间文件拷贝
- SCP远程拷贝命令
- RSYNC远程同步命令
- 核心:XSYNC集群分发脚本
- 配置分发流程
- 集群单起
- 集群群起
- 群起配置文件及分发
- 群起命令
- 启/停 命令总结
完全分布式集群部署规划
此模式称为——完全分布式(Fully-Distributed Operation)
注:此模式被分配到 hadoop102-104 三台虚拟机上,IP为192.168.x.102,103,104
| hadoop102 | hadoop103 | hadoop104 | |
|---|---|---|---|
| HDFS | NameNode DataNode |
DataNode |
SecondaryNameNode DataNode |
| YARN | NodeManager |
ResourceManager NodeManager |
NodeManager |
最极端的来看:
HDFS集群 ——》CPU+硬盘
YARN集群 ——》CPU+内存
也就是可以视为HDFS集群与YARN集群,它们是无绝对关联的两套集群,但一般情况下DN与NM运行在同一个服务器上。
注:hadoop100 虚拟机用于 Hadoop单节点部署实验,hadoop101 虚拟机用于 Hadoop伪分布式部署
Linux配置+Hadoop环境配置
【Linux 入门 Hadoop VM CentOS7】VM克隆 Hadoop单节点部署 Linux网络配置IP 主机名_2019.5.10
如果3台CentOS 7虚拟机已经配置好了,则可不看上博文,下文给出Hadoop环境配置(上博文也有)
解压及环境配置(基础/单)
此模式为——单节点模式(官方称为:Standalone Operation),亦是下面两种模式的基础前提。
其他模式是在这个基础上,对XML配置文件及shell脚本修改而来的。
注:此模式被分配到 hadoop100 虚拟机上,IP为192.168.x.100
注:本文此处仅为简版配置,适合已完成单节点部署的小白,如果没有完成的参看下面的博文
【Linux 入门 Hadoop-2.7.2 VM CentOS7】VM-Linux-Hadoop单节点部署 _2019.5.10
# java && hadoop 的压缩包tar.gz都存储在 /opt/software 目录
# 所有的软件都安装/解压在 /opt/module 目录
# 以 atguigu 非root 用户来解压,前提是 /opt/module与/opt/software目录 atguigu 用户均有777权限
# 一、解压
# 1.java
tar -zxvf jdk-8u144-linux-x64.tar.gz -C /opt/module/
# 2.hadoop
tar -zxvf hadoop-2.7.2.tar.gz -C /opt/module/
# 二、配置环境变量
sudo vi /etc/profile
>>>
##JAVA_HOME
export JAVA_HOME=/opt/module/jdk1.8.0_144
export PATH=$PATH:$JAVA_HOME/bin
##HADOOP_HOME
export HADOOP_HOME=/opt/module/hadoop-2.7.2
export PATH=$PATH:$HADOOP_HOME/bin
export PATH=$PATH:$HADOOP_HOME/sbin
<<<
# 三、验证
source /etc/profile
java -version
hadoop
混合集群配置及其分发(真·完全)
配置文件简述
四大默认配置文件:core-default.xml,hdfs-default.xml,yarn-default.xml,mapred-default.xml
对应的自定义配置文件:core-site.xml,hdfs-site.xml,yarn-site.xml,mapred-site.xml
【Hadoop(core),HDFS,YARN,MR】
默认配置文件所在Jar包
hadoop-common-2.7.2.jar/core-default.xml
hadoop-hdfs-2.7.2.jar/hdfs-default.xml
hadoop-yarn-common-2.7.2.jar/yarn-default.xml
hadoop-mapreduce-client-core-2.7.2.jar/mapred-default.xml
自定义配置文件应处路径:/$HADOOP_HOME/etc/hadoop
Shell脚本运行环境配置文件:hadoop-env.sh,yarn-env.sh,mapred-env.sh
完全分布式集群配置
要修改的配置文件命令列表
[atguigu@hadoop101 ~]$ cd /opt/module/hadoop-2.7.2/etc/hadoop/
[atguigu@hadoop101 hadoop]$ vim core-site.xml
[atguigu@hadoop101 hadoop]$ vim hadoop-env.sh
[atguigu@hadoop101 hadoop]$ vim hdfs-site.xml
[atguigu@hadoop101 hadoop]$ vim yarn-site.xml
[atguigu@hadoop101 hadoop]$ vim yarn-env.sh
[atguigu@hadoop101 hadoop]$ cp mapred-site.xml.template mapred-site.xml
[atguigu@hadoop101 hadoop]$ vim mapred-site.xml
[atguigu@hadoop101 hadoop]$ vim mapred-env.sh
具体的配置文件修改内容
# 所有配置文件的所在目录为 $HADOOP_HOME/etc/hadoop/
$ cd /$HADOOP_HOME/etc/hadoop/
# 1.Hadoop核心配置(配置文件+命令脚本)
# ①配置文件:core-site.xml
$ vim core-site.xml
>> <configuration></configuration>
<!-- 指定HDFS中NameNode的地址 -->
<property>
<name>fs.defaultFS</name>
<!-- `改`真·集群指定NameNode为规划好的 hadoop102 主机 -->
<value>hdfs://hadoop102:9000</value>
</property>
<!-- 指定Hadoop(具体来说是HDFS的NameNode与DataNode等)运行时产生文件的存储目录 -->
<property>
<name>hadoop.tmp.dir</name>
<value>/opt/module/hadoop-2.7.2/data/tmp</value>
</property>
<<
# ②命令脚本:hadoop-env.sh
# 更改已存在的 export JAVA_HOME=${JAVA_HOME} 为
$ vim hadoop-env.sh
>>
export JAVA_HOME=/opt/module/jdk1.8.0_144
<<
# 2.HDFS配置(配置文件)
# ①配置文件:hdfs-site.xml
$ vim hdfs-site.xml
>> <configuration></configuration>
<!-- 指定HDFS副本的数量 -->
<property>
<name>dfs.replication</name>
<value>3</value>
</property>
<!-- `新增·`指定Hadoop辅助名称节点主机配置 -->
<property>
<name>dfs.namenode.secondary.http-address</name>
<value>hadoop104:50090</value>
</property>
<<
# 3.YARN配置(配置文件+命令脚本)
# ①配置文件:yarn-site.xml
$ vim yarn-site.xml
>> <configuration></configuration>
<!-- Reducer获取数据的方式 -->
<property>
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce_shuffle</value>
</property>
<!-- 指定YARN的ResourceManager的地址 -->
<property>
<name>yarn.resourcemanager.hostname</name>
<!-- `改`指定ResourceManager为规划好的 hadoop103 主机 -->
<value>hadoop103</value>
</property>
<!-- 日志聚集功能设置(将程序运行日志信息上传到HDFS系统上) -->
<property>
<name>yarn.log-aggregation-enable</name>
<value>true</value>
</property>
<!-- 日志保留时间设置7天 -->
<property>
<name>yarn.log-aggregation.retain-seconds</name>
<value>604800</value>
</property>
<<
# ②命令脚本:yarn-env.sh
# 在原本存在的 # export JAVA_HOME=/home/y/libexec/jdk1.6.0/ 下面新增
$ vim yarn-env.sh
>>
export JAVA_HOME=/opt/module/jdk1.8.0_144
<<
# 4.MapReduce配置(配置文件+命令脚本)
# ①配置文件:mapred-site.xml(注意此文件,由 mapred-site.xml.template 复制而来)
$ cp mapred-site.xml.template mapred-site.xml
$ vim mapred-site.xml
>> <configuration></configuration>
<!-- 指定MR运行在YARN上 -->
<property>
<name>mapreduce.framework.name</name>
<value>yarn</value>
</property>
<!-- 历史服务器端地址(默认是secondaryNameNode?) -->
<property>
<name>mapreduce.jobhistory.address</name>
<value>hadoop104:10020</value>
</property>
<!-- 历史服务器web端地址 -->
<property>
<name>mapreduce.jobhistory.webapp.address</name>
<value>hadoop104:19888</value>
</property>
<<
# ②命令脚本:mapred-env.sh
# 在原本存在的 # export JAVA_HOME=/home/y/libexec/jdk1.6.0/ 下面新增
$ vim mapred-env.sh
>>
export JAVA_HOME=/opt/module/jdk1.8.0_144
<<
↓ 分发&&群起前提 ↓
SSH免密登录
SSH简介
Secure Shell(安全外壳协议,简称SSH)是一种加密的网络传输协议,SSH通过在网络中创建安全隧道来实现SSH客户端与服务器之间的连接,SSH最常见的用途是远程登录系统,人们通常利用SSH来传输命令行界面和远程执行命令。
SSH组件检测
SSH在Linux中共有openssh-client和openssh-server两个应用程序来实现SSH通讯
默认情况下都是缺省安装
# 检查 rpm -qa | grep ssh
[atguigu@hadoop101 ~]$ rpm -qa | grep ssh
openssh-clients-7.4p1-16.el7.x86_64
openssh-server-7.4p1-16.el7.x86_64
openssh-7.4p1-16.el7.x86_64
libssh2-1.4.3-12.el7.x86_64
语法
# 基础语法
ssh user@host
# 指定SSH端口
ssh -p 2222 user@host
# 如果目的地用户与当前用户同名,可省略 user
ssh host
SSH加密方式之RSA非对称加密原理
虎符一分为两,二者合一方为正身。
A与B建立可靠链接(非互信,只是A单方面信任B)前提是:A服务器将公钥授权给B服务器
之后的数据交互过程为:
A将信息以私钥加密——》发送给B,B通过已授权的A的公钥解密【私加,公解】
B将信息以公钥加密——》发送给A,A通过自己的私钥解密【公加,私解】
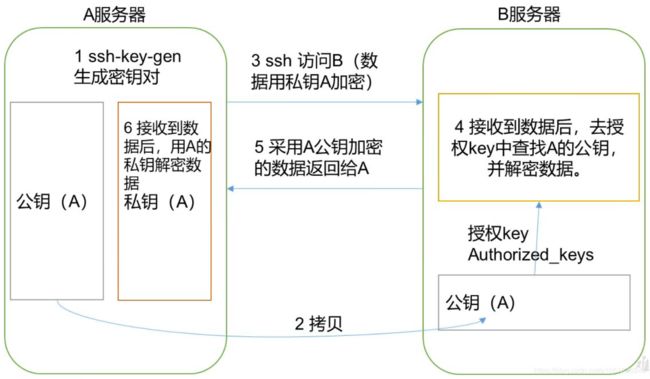
核心:SSH-RSA配置
# 1.为当前用户 生成RSA公私钥【三个回车结束,产生 公私钥 随机艺术图】
# 并检查生成公私钥文件,分别为
$ ssh-keygen -t rsa
The key's randomart image is:
+---[RSA 2048]----+
|=oE.. . |
|== + + . |
|B X O + |
|oO # @ o |
|= X X * S |
|o= + o o . |
|o . . . |
| |
| |
+----[SHA256]-----+
# 进入当前用户家目录的.ssh目录
$ cd
$ cd .ssh/
$ ll
总用量 8
-rw-------. 1 atguigu atguigu 1675 9月 24 20:33 id_rsa
-rw-r--r--. 1 atguigu atguigu 399 9月 24 20:33 id_rsa.pub
# 2.授权免密
$ ssh-copy-id hadoop103
$ ssh-copy-id hadoop104
# 注意:ssh访问自己也需要输入密码,所以我们需要将公钥也拷贝给102
$ ssh-copy-id hadoop102
注1:第一个回车 “Enter file in which to save the key (/home/atguigu/.ssh/id_rsa):” 确定公私钥存储位置,一般都是在当前用户的家目录的.ssh目录下,id_ras为私钥,id_rsa.pub为公钥。
注2:第二个回车 “Enter passphrase (empty for no passphrase): ”是否采用密码短语对私钥进行加密,如果采用密码短语再加密,会导致不能免密登陆。所以建议使用回车即是——empty。第三个回车 “Enter same passphrase again:” 同。
注3:SSH如果配置失败,请观察一下当前用户目录权限,若是777,请考虑重新新建用户,参考系统生成的用户目录权限
注意:当前用户为 atguigu ,如果想要使用 root 来免密登录其他虚拟机,仍需再次重复上面的操作!!!
注意:当前主机为NameNode节点,如果是ResourceManager主机,则仍需再次重复上面的操作!!!
↓分发前提2↓
虚拟机间文件拷贝
SCP远程拷贝命令
scp(secure copy)安全拷贝,实现任意非本机服务器与一或多个服务器之间的数据拷贝
SCP基本语法
scp -r $pdir/ | /$filename $user@$host:$pdir/ | /$filename
命令 递归 本地被拷贝的目录/文件路径 目的用户@主机地址:目的目录/目的文件路径
SCP目标目录问题
# 实例:目标目录存在与否
前提:/opt/module/hadoop-2.7.2/拷贝到其他虚拟机上(且均有/opt/module/目录)
pwd:/opt/module,以下命令均为 [atguigu@hadoop102 module]$ 起始
# 情况1:将hadoop-2.7.2目录 拷贝到其他虚拟机 存在的/opt/module/目录下,并保留/hadoop-2.7.2/目录
scp -r hadoop-2.7.2/ root@hadoop101:/opt/module/
# 情况2:将hadoop-2.7.2目录 拷贝到其他虚拟机 不存在的/opt/module/test/目录下,不保留hadoop-2.7.2目录
scp -r hadoop-2.7.2/ root@hadoop103:/opt/module/test/
# 情况3:将hadoop-2.7.2目录内容 拷贝到其他虚拟机 存在的/opt/module/test/目录下,不保留hadoop-2.7.2目录
scp -r hadoop-2.7.2/* root@hadoop104:/opt/module/test/
SCP不同位置拷贝
# 本机 hadoop102 拷贝至 其他单个 hadoop101 虚拟机(默认已存在目标目录)【我推下】
# 为什么使用 hadoop101的root用户,因为要在/opt/目录下 创建新目录,必须使用root权限
scp -r hadoop-2.7.2/ root@hadoop101:/opt/module/
#注意:hadoop101新目录文件(hadoop-2.7.2)用户:用户组均为 root root
sudo chown atguigu:atguigu -R /opt/module
sudo chmod -R 777 /opt/module
# 本机 hadoop101 从其他单个 hadoop102 虚拟机(默认已存在来源目录)拷贝至本机【我拉取】
# 源目录/opt/module 拥有者是 atguigu
sudo scp -r atguigu@hadoop102:/opt/module ../
#注意:hadoop101新目录文件(hadoop-2.7.2)用户:用户组均为 root root
sudo chown atguigu:atguigu -R /opt/module
sudo chmod -R 777 /opt/module
# 本机 hadoop101 从其他单个 hadoop102 虚拟机 拷贝到 其他单个 hadoop103 虚拟机【我帮忙】
scp -r atguigu@hadoop101:/opt/module root@hadoop103:/opt/module
#总结:完整的SCP语法
scp -r $user@$host:$pdir/ | /$filename $user@$host:$pdir/ | /$filename
子文件递归 用户@IP地址:被拷贝目录 或 文件路径 用户@IP地址:目标目录 或 目标文件路径
注意:目标虚拟机,必须使用 有权限新建目录的用户,通常是root用户
RSYNC远程同步命令
rsync主要用于备份和镜像。具有速度快、避免复制相同内容和支持符号链接的优点。
rsync和scp区别:用rsync做文件的复制要比scp的速度快,rsync只对差异文件做更新。scp是把所有文件都复制过去。
RSYNC基本语法
rsync -rvl $pdir/$fname $user@$host:$pdir/$fname
命令 选项参数 要拷贝的文件路径/名称 目的用户@主机地址:目的路径/名称
选项参数说明
-r:递归复制,-v:显示全面various过程/view可见过程,-l:拷贝符号链接
RSYNC不同虚拟机位置同步
# 本机 hadoop101 同步到 其他单个 hadoop102 虚拟机(默认已存在目标目录)【我推下】
rsync -rvl /opt/module/hadoop-2.7.2/ root@hadoop102:/opt/module/hadoop-2.7.2/
# 本机 hadoop103 从 其他单个 hadoop101 虚拟机(默认已存在目标目录) 同步至 本机【我拉取】
sudo rsync -rvl atguigu@hadoop101:/opt/module/hadoop-2.7.2/ /opt/module/hadoop-2.7.2/
# 不存在三方同步
#总结:完整的RSYNC语法
rsync -r $user@$host:$pdir/ | /$filename $user@$host:$pdir/ | /$filename
子文件递归 用户@IP地址:被拷贝目录 或 文件路径 用户@IP地址:目标目录 或 目标文件路径
注意:目标虚拟机,必须使用 有权限新建目录的用户,通常是root用户
核心:XSYNC集群分发脚本
循环 rsync指定文件到 所有虚拟机s 的相同目录下【XSYNC= X * RSYNC(X为未知量)】
1.在 /home/$whoami/ 创建bin 目录,并创建xsync脚本
[atguigu@hadoop101 ~]$ mkdir bin
[atguigu@hadoop101 ~]$ cd bin/
[atguigu@hadoop101 ~]$ vi xsync
>>
见xsync脚本内容代码块
<<
[atguigu@hadoop101 ~]$ chmod 777 xsync
# 实例:从hadoop101 同步 至 hadoop102、103、104
[atguigu@hadoop101 ~]$ xsync /home/atguigu/bin
2.编写 xsync 脚本内容
#!/bin/bash
#1 获取输入参数个数,如果没有参数,直接退出
pcount=$#
if((pcount==0)); then
echo no args;
exit;
fi
#2 获取文件名称
p1=$1
fname=`basename $p1`
echo fname=$fname
#3 获取上级目录到绝对路径 –P指向实际物理地址,防止软连接
pdir=`cd -P $(dirname $p1); pwd`
echo pdir=$pdir
#4 获取当前用户名称
user=`whoami`
#5 循环
for((host=102; host<105; host++)); do
echo ------------------- hadoop$host --------------
rsync -rvl $pdir/$fname $user@hadoop$host:$pdir
done
注意:如果将xsync放到/home/atguigu/bin目录下仍然不能实现全局使用,可以将xsync移动到/usr/local/bin目录下
配置分发流程
第一步:配置SSH免密登录
NameNode 所在主机配置访问其他 DataNode 主机的 SSH免密登陆
ResourceManager 所在主机配置访问其他 NodeManager 主机的 SSH免密登陆
第二步:使用 XSYNC 脚本执行配置分发
直接分发 已配置好的 hadoop-2.7.2 目录即可:$ xsync /opt/module/hadoop-2.7.2/
集群单起
集群单起,说白了,就是一个一个进程启动,这个情况适用于,单独上线几个,少数个新服务器节点(DN+NM)
注意:一般情况下DN+NM都是同时存在一台服务器上的
HDFS
[atguigu@hadoop101 hadoop-2.7.2]$ sbin/hadoop-daemon.sh start namenode
[atguigu@hadoop101 hadoop-2.7.2]$ sbin/hadoop-daemon.sh start datanode
YARN
[atguigu@hadoop102 hadoop-2.7.2]$ sbin/yarn-daemon.sh start resourcemanager
[atguigu@hadoop102 hadoop-2.7.2]$ sbin/yarn-daemon.sh start nodemanager
History
[atguigu@hadoop101 hadoop-2.7.2]$ sbin/mr-jobhistory-daemon.sh start historyserver
集群群起
群起配置文件及分发
第一步:在 NameNode名称节点 所处虚拟机上 配置 slaves 文件,并分发给所有节点
此文件只被 sbin 目录下的 集群 群启动关闭等命令所读取。
注:若不配置,则默认启动NN节点的NN&DN与SND节点的SNN服务,其他2个虚拟机DN服务不启动
[atguigu@hadoop102 hadoop]$ vim /opt/module/hadoop-2.7.2/etc/hadoop/slaves
>>
hadoop102
hadoop103
hadoop104
<<
[atguigu@hadoop102 ~]$ xsync /opt/module/hadoop-2.7.2/etc/hadoop/slaves
# 一定要查看!!!分发的虚拟机(抽查)是否正确!!!
# 103
[atguigu@hadoop103 hadoop]$ cat /opt/module/hadoop-2.7.2/etc/hadoop/slaves
hadoop102
hadoop103
hadoop104
# 104
[atguigu@hadoop104 hadoop]$ cat /opt/module/hadoop-2.7.2/etc/hadoop/slaves
hadoop102
hadoop103
hadoop104
群起命令
第二步: 启动HDFS集群,在 NameNode 名称节点 所处虚拟机上【规划为 102】
# 大前提,NameNode配置 SSH 免密登录
[atguigu@hadoop102 .ssh]$ ssh-keygen -t rsa
[atguigu@hadoop102 .ssh]$ ssh-copy-id hadoop102
[atguigu@hadoop102 .ssh]$ ssh-copy-id hadoop103
[atguigu@hadoop102 .ssh]$ ssh-copy-id hadoop104
# 注:第一次启动HDFS集群,需要将 NameNode 进行格式化
[atguigu@hadoop102 ~]$ cd /opt/module/hadoop-2.7.2/
[atguigu@hadoop102 hadoop-2.7.2]$ bin/hdfs namenode -format
# 群起HDFS,使用 sbin 目录下的 dfs集群命令,
[atguigu@hadoop102 hadoop-2.7.2]$ sbin/start-dfs.sh
# 验证1,使用 jps 命令查询 虚拟机 正在运行的 Java进程(HDFS)
[atguigu@hadoop102 hadoop-2.7.2]$ jps
# 验证2,NameNode:http://hadoop102:50070/dfshealth.html#tab-overview
# 验证3,SecondaryNameNode:http://hadoop104:50090/status.html
第三步:启动YARN集群,在 ResourceManager 资源节点 所处虚拟机上【规划为 103】
# 大前提,NameNode配置 SSH 免密登录
[atguigu@hadoop103 .ssh]$ ssh-keygen -t rsa
[atguigu@hadoop103 .ssh]$ ssh-copy-id hadoop102
[atguigu@hadoop103 .ssh]$ ssh-copy-id hadoop103
[atguigu@hadoop103 .ssh]$ ssh-copy-id hadoop104
# 群起YARN,使用 sbin 目录下的 yarn集群命令
[atguigu@hadoop103 hadoop-2.7.2]$ sbin/start-yarn.sh
# 验证1,使用 jps 命令查询 虚拟机 正在运行的 Java进程(HDFS)
[atguigu@hadoop103 hadoop-2.7.2]$ jps
# 验证2,http://hadoop103:8088/cluster,注意,非正常完全启动YARN集群,会导致WEB初始化失败无法访问
# 运行MR
[atguigu@hadoop102 hadoop-2.7.2]$ bin/hdfs dfs -mkdir -p /user/atguigu/input/
[atguigu@hadoop102 hadoop-2.7.2]$ bin/hdfs dfs -put README.txt /user/atguigu/input/
[atguigu@hadoop102 hadoop-2.7.2]$ bin/hadoop jar share/hadoop/mapreduce/hadoop-mapreduce-examples-2.7.2.jar wordcount /user/atguigu/input /user/atguigu/output
[atguigu@hadoop102 hadoop-2.7.2]$ bin/hdfs dfs -rm -R /user/atguigu/output
[atguigu@hadoop102 hadoop-2.7.2]$ bin/hdfs dfs -rm -R /user/atguigu/input
第四步:启动 History 历史服务器,在 hadoop104 上 【规划为 104】
[atguigu@hadoop101 hadoop-2.7.2]$ sbin/mr-jobhistory-daemon.sh start historyserver
# 验证1,使用 jps 命令查询 虚拟机 正在运行的 Java进程(HDFS)
[atguigu@hadoop103 hadoop-2.7.2]$ jps
# 验证2,http://hadoop104:19888/jobhistory
启/停 命令总结
群起命令 及 单节点命令 [ sbin/ ]
# 整体启动/停止HDFS(NN+DN+SNN)
start-dfs.sh / stop-dfs.sh
# 整体启动/停止YARN(NN+DN+SNN)
start-yarn.sh / stop-yarn.sh
# 单节点 启动/停止HDFS组件
hadoop-daemon.sh start / stop namenode / datanode / secondarynamenode
# 单节点 启动/停止YARN(RM+DM)
yarn-daemon.sh start / stop resourcemanager / nodemanager
.