RabbitMQ高阶/网络分区/消息追踪/负载均衡
RabbitMQ高阶
RabbitMQ实现原理
存储机制
持久化的消息到达时就写入磁盘,如果可以在内存中也会保存一份备份,以提高一定性能
非持久化消息到达时在内存中,当内存吃紧时,会被换入磁盘
消息包括消息体、属性和headers
$RABBITMQ_HOME/var/lib/mnesia/rabbit@$HOSTNAME/文件夹下的queues、msg_store_persistent、msg_store_transient文件夹
队列的结构
如果消息投递的目的队列是空的,且有消费者订阅这个队列,消息会直接发送给消费者,不会经过队列这一步
惰性队列
惰性队列会将收到的消息直接存入文件系统,而不管是持久化或非持久化,可以减少内存的消耗,但会增加I/O
队列具备两种模式:default和lazy。声明队列时通过x-queue-mode可以设置队列模式,当然也可以使用policy的方式设置,且policy具有更高的优先级
rabbitmqctl set_policy Lazy "^myqueue$" '{"queue-mode":"lazy"}' --apply-to queues
惰性队列和普通队列相比,只有很小的内存开销
普通队列,发送1千万条消息,需要801秒,若使用惰性队列,只要421秒,平均24000条/秒。性能偏差原因为:普通队列会因内存不足而发生换页动作
内存及磁盘告警
当内存使用超过配置的阈值或者磁盘剩余空间低于配置的阈值时,MQ会暂时阻塞客户端的连接,并停止接收新的消息,同时客户端与服务端的心跳检测也会失效
在一个集群中,如果一个Broker节点内存或磁盘受限,会引起整个集群中所有connection被阻塞
内存告警
rabbitmqctl set_vm_memory_high_watermark 0.4
默认为0.4即内存阈值为0.4,超过40%时,会产生内存告警并阻塞所有生产者的连接
若设置为0,则所有生产者都会被停止发送消息,可用于禁止集群中的心脏病消息发布的情况
正常建议在0.4至0.66之间,不要超过0.7
[{rabbit,[{vm_memory_hith_watermark,{absolute,"1024MiB"}}]}].
可用单位有:K、KiB、M、MiB、G、GiB
rabbitmqctl set_vm_memory_high_watermark absolute 200MiB
命令的方式设置的在重启后会失效,而配置文件的形式则不会失效

默认达到阈值的50%时会进行换页动作,vm_memory_hith_watermark_paging_ratio可以设置这个比例,设置其值大于1的浮点数则相当于是禁用换页功能
MQ不能识别系统内存大小时,会默认系统总内存为1G
磁盘告警
当剩余磁盘空间低于确定阈值时,MQ会阻塞生产者,默认磁盘阈值为50MB。一个谨慎的做法是将磁盘阈值设置为与操作系统所显示的内存大小一致。默认每10秒执行一次检查,随着与阈值的接近,检测频率会加快,当达到阈值时,检测频率为每秒10次
[{rabbit,[{disk_free_limit,1000000000}]}]. #设置阈值为1GB左右
[{rabbit,[{disk_free_limit,"1GB"}]}].
[{rabbit,[{disk_free_limit,{mem_relative,1.0}}]}]. #设置为与集群内存一样大
rabbitmqctl set_disk_free_limit 1GB
rabbitmqctl set_disk_free_limit mem_relative 1.5 #建设值为1.0至2.0之间
流控
Flow Control,流控用来避免消息发送速率过快导致服务器难以支撑
流控的原理
Erlang进程间不共享内存(binary类型除外),而是通过消息传递来通信,每个进程有自己的进程邮箱。默认并没有对进程邮箱进行大小限制,当有大量消息持续发往某个进程时,会导致进程邮箱过大,最终内存溢出并崩溃
MQ基于信用证算法的流控机制来限制发送消息的速率,最终阻塞网络数据包的接收而暂停接收新数据
一个连接connection触发流控时会处于flow状态,在客户端看来,只是服务器的带宽比正常的小了
流控作用于connection chanel queue
案例:打破队列的瓶颈
提升队列的性能方法:
一是开启Erlang语言的HiPE功能,可以提高30%~40%的性能,Erlang版本至少18.x以上
二是用多个进程来处理一个队列,rabbit_amqqueue_process,封装成逻辑队列。
声明交换器、队列、绑定关系,分片的概念
镜像队列
在集群上,交换器和绑定关系能够在单点故障上不丢失,但队列进行及其内容仅仅维持在单个节点之上,所以一个节点的失效表现为其对应的队列不可用
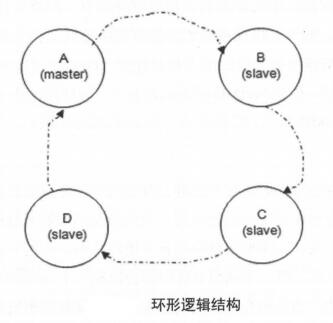
镜像队列Mirror Queue机制,可以将队列镜像到集群中其他Broker节点上。一个镜像队列包含一个主节点master和若干个从节点slave

slave会准确地按照master执行命令的顺序进行动作,slave和master维护的状态是一样的,master失效后,资历最老的slave会被提升为新的master,资历最老是加入时间最长。除发送消息外所有动作都只向master发送,然后再由master将命令执行结果广播到和只个slave
若消费者与slave建立连接并订阅,实质上都是从master上获取消息
实际的负载在master队列上,一个集群中会有多个队列,保证不同队列的master落在不同的broker上,就可以实现负载的均衡。MQ没有MySQL那样的读写分离
MQ的镜像队列同时支持publisher confirm和事务两种机制

当一个新节点加入或者重新加入到这个镜像链路中时,之前队列保存的内容会被全部清空
当slave挂掉后,与slave连接的客户端连接全部断开,没有其他影响
当master挂掉后,会有以下动作:
1、与master连接的客户端连接全部断开
2、选举最老的slave作为新的master,若此时所有slave未处于同步状态,则未同步的消息丢失
3、新master重新入队所有unack的消息,此时客户端可能会有重复消息
4、若客户端连接着slave,且指定了x-cancel-on-ha-failover参数,那么客户端会收到一个通知,若未指定则客户端无感
配置方法
镜像队列主要是通过添加相应policy的方式完成
rabbitmqctl set_policy [-p vhost] [--priority priority] [--apply-to apply-to] {name} {pattern} {definition}
对于镜像队列,definition部分包含3个部分:ha-mode、ha-params、ha-sync-mode
ha-mode,镜像队列模式,值有all、exactly、nodes,默认为all
->all,在集群中所有节点上进行镜像
->exactly,在指定个数的节点上进行镜像,节点个数由ha-params指定
->nodes,在指定节点上进行镜像,节点名称通过ha-params指定,节点名称可以通过rabbitmqctl cluster_status命令查看
ha-params,不同ha-mode配置中需要用到的参数
ha-sync-mode,队列中消息的同步方式,值有automatic、manual
对名称以queue_开头的所有队列进行镜像,并在集群的两个节点上完成镜像
rabbitmqctl set_policy --priority 0 --apply-to queues mirror_queue "^queue_" '{"ha-mode":"exactly","ha-params":2,"ha-sync-mode":"automatic"}'
ha-mode对排他exclusive队列无效,因为排他队列是独占的,当连接断开时会自动删除
ha-sync-mode为manual时,新加入的节点不会主动同步到新的slave中,需要显式调用同步命令
ha-sync-mode为automatic时,新加入的slave会自动同步已知镜像队列
同步时,队列会阻塞,直至同步完成,所以不建立对生产环境正在使用的队列进行操作
手动同步队列:rabbitmqctl sync_queue queue_test
当ha-promote-on-shutdown设置为when-synced(默认)时,若master主动停掉,如rabbitmqctl stop或者优雅关闭操作系统,那么slave不会接管master,镜像队列不可用;如果master因被动原因关掉,如Erlang虚拟机或操作系统崩溃,slave会接管master;若ha-promote-on-shutdown设置为always,那么slave总是会接替master,优先保证可用性,不过过程中可能会有消息丢失
镜像队列最后一个停止的会是master,要恢复镜像队列,可以尝试在30秒内启动所有节点
若消息是持久化的,建议搭配惰性队列使用
网络分区
网络分区即集群解体,可能会引起消息丢失或服务不可用。可以简单通过重启或配置自动化处理的方式解决这个问题
网络分区的意义
当网络恢复时,网络分区的状态还会保持,除非采取一些措施来解决
网络分区有利有弊,许多情况下,是由于单个这结故障引起的,通常会形成一个大分区和一个单节点的分区
网络分区的判定
RabbitMQ集群节点内部通信端口默认为25672,两两节点之间都会有信息交互。当出现网络故障或端口不通时,会有超时判定机制,继而判定网络分区
对网络分区的判定与net_ticktime参数相关,默认值为60秒。T时间范围是:45s~75s
heartbeat_time是客户端与MQ之间的心跳时间,针对5672端口
查看网络分区的方式:
1、看日志
2、rabbitmqctl cluster_status 查看partitions项
3、通过web界面查看
4、通过HTTP API 如curl -i -u admin:admin -H "content-type:application/json" -XGET http://192.168.158.100:15672/api/nodes
网络分区的模拟
iptables封禁/解封IP或端口号
关闭/开启网卡
挂起/恢复操作系统
iptables方式
iptables -A INPUT -p tcp --dport 25672 -j DROP
iptables -A OUTPUT -p tcp --dport 25672 -j DROP
恢复
iptables -D INPUT 1
iptables -D OUTPUT 1
iptables -I INPUT -s 192.168.0.2 -j DROP
iptables -I INPUT -s 192.168.0.4 -j DROP
恢复
iptables -D INPUT 1
iptables -D INPUT 1
网卡方式
ifdown eth0
ifup eth0
挂起/恢复操作系统方式
网络分区的影响
未配置镜像
网络分区发生后,队列也会伴随宿主节点而分散在各自的分区之中。对消息发送方而言,可以成功发送消息,但是会有路由失败的现象,需要配置mandatoryt等机制保障消息的可靠性。对于消息消费方来说,有可能会有诡异、不可预知的现象发生,如已消费消息的ack会失效。网络分区发生后,客户端与某分区重新建立通信链路,若分区中没有相应队列的进程,会有异常报出。如果从网络分区中恢复后,数据不会丢失,但客户端会重复消费
已配置镜像
同步会阻塞队列,有大量消息重复等,镜像分配问题,是否自动同步
手动处理网络分区
选挑选一个信任分区,重启非信任分区中的节点,若此时还有网络分区的告警,紧接着重启信任分区中的节点
挑选信任分区:分区中要有disc节点;分区中节点数最多;分区中队列数最多;分区中客户端连接数最多。优先级从前到后
重启非信任分区节点:一种是rabbitmqctl stop;rabbitmq-server -detached。一种是rabbitmqctl stop_app;rabbitmqctl start_app。推荐第二种方式,仅重启MQ应用
重启顺序:
1、停止其他非信任分区中的所有节点,然后再启用。若还有告警,则再重启信任分区中节点以消除告警
2、关闭整个集群中节点,再启动每一个节点,需要确保启动的第一个节点在信任分区中
重启之前要考虑队列“漂移”现象
对镜像队列,为防止发生网络分区恢复过程中的“漂移”,在一定程度上阻止队列“过分漂移”到一个节点的情况,可以先删除镜像队列的配置
rabbitmqctl clear_policy [-p vhost] {mirror_policy_name}
需要在每个分区上都执行
网络分区处理步骤:
1)挂起生产者和消费者进程。减少消息不必要的丢失
2)删除镜像队列的配置
3)挑选信任分区
4)关闭非信任分区中节点。采用rabbitmqctl stop_app
5)启动非信任分区中节点。采用rabbitmqctl start_app
6)检查网络分区是否恢复,恢复转步骤8,否则转步骤7。检查rabbitmqctl cluster_status输出中partitions项为空
7)重启信任分区中节点
8)添加镜像队列的配置
9)恢复生产者和消费者进程
自动处理网络分区
三种方法:pause-minority、pause-if-all-down、autoheal、ignore(默认,不处理)
rabbitmq.config配置方法
[{rabbit,[{cluster_partition_handling,ignore}]}].
pause-minority模式
发生分区时,节点自己检查是否属于少数派(节点数小于或等于集群一半),若是则自动关闭MQ应用,处于关闭状态的节点会每秒检测一次是否可连通到剩余集群,若可以则启动自身
[{rabbit,[{cluster_partition_handling,pause_minority}]}].
不适用于只有两个节点的集群以及对等集群,因为会关闭所有节点,只有等网络恢复后才会启动所有节点以求从网络分区中恢复
pause-if-all-down模式
目标节点与所配置的列表中的任何节点不能交互时才会关闭
{pause_if_all_down,[nodes],ignore|autoheal}
[{rabbit,[{cluster_partition_handling,{pause_if_all_down,['rabbit@node1'],ignore}}]}].
autoheal模式
发生网络分区时,MQ自动决定一个获胜的分区,然后重启不在这个分区中的节点来从网络分区中恢复
获胜:客户端连接最多>节点数最多>节点名称字典序
[{rabbit,[{cluster_partition_handling,autoheal}]}].
在net_tick_timeout时不做动作,等到网络恢复时才进行重启操作
若集群中有非运行节点,将不会进行任何操作
挑选哪种模式
如果置MQ于不可靠的网络环境下,需要使用Federation或Shovel
ignore:人工介入操作
pause-minority:对对等分区处理不优雅,可能会关闭所有节点,常用于非跨机架、奇数节点数的集群中
pause-if-all-down:对受信节点的选择考究,可以处理对等分区的情形
autoheal:可处理各种情况下的网络分区,但若集群中有节点处于非运行状态,则此模式会失效
RabbitMQ扩展
消息追踪
Firehose
Firehose可以实现消息追踪,记录每一次发送或消费消息的过程,进行调试、排错等
将生产者或者消费者的消息按指定的格式发送到默认交换器上,默认交换器为amp.rabbitmq.trace,topic类型的交换器,发送到其上的消息路由键为publish.{exchangename}和deliver.{queuename}
#开启Firehose
rabbitmqctl trace_on [-p vhost]
#关闭Firehose
rabbitmqctl trace_off [-p vhost]
默认处于关闭状态,开启会多少影响整体服务性能,因为它会引起额外的消息生成、路由和存储
消息相关属性会在headers中反映出来

rabbitmq_tracing插件
相当于是Firehose的GUI版本,会将结果输出到文件中,文件默认路径/var/tmp/rabbitmq-tracing目录,可在web上查看
内部是新建一个匿名队列,bind到amq.rabbitmq.trace中的
#启用rabbitmq_tracing
rabbitmq-plugins enable rabbitmq_tracing
#关闭
rabbitmq-plugins disable rabbitmq_tracing
参数说明
Format,输出格式,text和json,其中json的payload会采用base64编码
Max payload bytes,每条消息的最大限制,单位B
Pattern,匹配模式,#匹配所有 publish.#, deliver.# #.amq.direct, #.myqueue
负载均衡
客户端内部实现负载均衡
轮询、加权轮询、随机、加权随机、源地址哈希、最小连接数
使用Haproxy实现负载均衡
使用Keepalived实现高可靠负载均衡
Keepalived检查Haproxy状态的脚本,若不存在haproxy线程,则启动haproxy,等待2秒后,若如现启动不成功,则重启keepalived服务,让VIP漂移
| 1 2 3 4 5 6 7 8 9 |
#!/bin/bash # /etc/keepalived/check_haproxy.sh if [ $(ps -C haproxy --no-header | wc -l) -eq 0 ];then haproxy -f /opt/haproxy-1.7.8/haproxy.cfg fi sleep 2 if [ $(ps -C haproxy --no-header | wc -l) -eq 0 ];then systemctl restart keepalived fi |
使用Keepalived + LVS实现负载均衡
LVS是4层负载均衡,效率非常高。LVS由3部分组成
负载调度器Load Balancer/Director,整个集群对外的前端机,负载将客户的请求发送到一组服务器上执行,而客户认为服务是来自一个IP
服务器池Server Pool/RealServer,真正执行客户端请求的服务器
共享存储Shared Storage,为服务器池提供一个共享存储区
LVS负载均衡的方式:
VS/NAT:所有RealServer将自己的网关指向Director,但Director能带动的RealServer比较有限
VS/TUN:IP隧道,将一个IP报文封装到另一个IP报文。
VS/DR:改写报文中MAC地址

LVS不需要额外的配置文件,直接集成在Keepalived的配置文件之中。在LVS和Keepalived环境里,LVS主要的工作是提供调度算法,把客户端请求调度到RealServer中,Keepalived主要工作是提供LVS控制器的一个冗余,且对RealServer进行健康检查,发现不健康的将其从LVS集群中剔除,RealServer只负责提供服务
通常在LVS的VS/DR模式下,需要在RealServer上配置VIP。因为客户端来的请求目标IP是VIP,RealServer收到发现不是自己的IP,会丢弃。所以这里将VIP的值绑定到RealServer的lo接口上,并设置其掩码为255.255.255.255,说明广播地址是自身,那么它就不会将ARP广播出去,从而防止LVS上的VIP与lo上的VIP地址冲突。
安装keepalived 2.0.2
wget https://github.com/hnakamur/keepalived-rpm/releases/download/2.0.2-1/keepalived-2.0.2-1.el7.x86_64.rpm
yum install keepalived-2.0.2-1.el7.x86_64.rpm
systemctl start keepalived
systemctl status keepalived
| 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 93 94 95 96 97 98 99 100 101 102 103 104 105 106 107 108 109 |
! /etc/keepalived/keepalived.conf global_defs { ! 路由ID 主/备ID不能相同 router_id NodeA }
vrrp_instance VI_1 { ! 角色 MASTER BACKUP state MASTER ! 指定监测网卡 interface ens33 ! 虚拟路由ID 主/备ID不能相同 virtual_router_id 1 ! 优先级 BACKUP要小于MASTER priority 100 ! 设置主备间检查时间 单位秒 advert_int 1 authentication { auth_type PASS auth_pass root123 } ! track_script { ! 七层检查脚本 ! hk_haproxy ! } virtual_ipaddress { ! VIP地址 可设置多个 ! 若没有/24将会是32位的 VIP就不会漂移了 192.168.1.10/24 } }
! 设置虚拟服务器 virtual_server 192.168.0.10 5672 { ! 设置运行情况检查时间 单位秒 delay_loop 6 ! 负载算法 有rr wrr lc wlc lblc lblcr dh sh ! 这里是加权算法 lb_algo wrr ! 设置LVS负载均衡机制 VS/DR lb_kind DR persistence_timeout 50 ! 转发协议类型 有TCP UDP protocol TCP ! 后端真实服务器 RealServer real_server 192.168.0.2 5672 { weight 1 TCP_CHECK { connect_timeout 3 nb_get_retry 3 delay_before_retry 3 connect_port 5672 } } real_server 192.168.0.3 5672 { weight 1 TCP_CHECK { connect_timeout 3 nb_get_retry 3 delay_before_retry 3 connect_port 5672 } } real_server 192.168.0.4 5672 { weight 1 TCP_CHECK { connect_timeout 3 nb_get_retry 3 delay_before_retry 3 connect_port 5672 } } }
! 为MQ的Management插件设置负载均衡 virtual_server 192.168.0.10 15672 { delay_loop 6 lb_algo wrr lb_kind DR persistence_timeout 50 protocol TCP real_server 192.168.0.2 15672 { weight 1 TCP_CHECK { connect_timeout 3 nb_get_retry 3 delay_before_retry 3 connect_port 15672 } } real_server 192.168.0.3 15672 { weiht 1 TCP_CHECK { connect_timeout 3 nb_get_retry 3 delay_before_retry 3 connect_port 15672 } } real_server 192.168.0.4 15672 { weight 1 TCP_CHECK { connect_timeout 3 nb_get_retry 3 delay_before_retry 3 connect_port 15672 } } } |
因为LVS这里选用的是DR方式,所以仅路由转发请求,服务器本身并不会监听端口,所以使用netstat -ltunp并不会看到virtual_server的监听端口
genhash –s 192.168.100.2 –p 80 –u /testurl/test.jsp
官方文档:http://www.keepalived.org/doc/index.html
服务器部分
| 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 |
#!/bin/bash # /opt/realserver.sh VIP=192.168.158.200 chmod u+x /etc/rc.d/init.d/functions /etc/rc.d/init.d/functions chmod u-x /etc/rc.d/init.d/functions
case "$1" in start) /sbin/ifconfig lo:0 $VIP netmask 255.255.255.255 broadcast $VIP /sbin/route add -host $VIP dev lo:0 echo "1" >/proc/sys/net/ipv4/conf/lo/arp_ignore echo "2" >/proc/sys/net/ipv4/conf/lo/arp_announce echo "1" >/proc/sys/net/ipv4/conf/all/arp_ignore echo "2" >/proc/sys/net/ipv4/conf/all/arp_announce sysctl -p >/dev/null 2>&1 echo "RealServer Start OK" ;; stop) /sbin/route del -host $VIP dev lo:0 /sbin/ifconfig lo:0 down echo "0" >/proc/sys/net/ipv4/conf/lo/arp_ignore echo "0" >/proc/sys/net/ipv4/conf/lo/arp_announce echo "0" >/proc/sys/net/ipv4/conf/all/arp_ignore echo "0" >/proc/sys/net/ipv4/conf/all/arp_announce ;; status) islothere=`/sbin/ifconfig lo:0 | grep $VIP | wc -l` isrothere=`netstat -rn | grep "lo:0" | grep $VIP | wc -l` if [ $islothere -eq 0 ] then if [ $isrothere -eq 0 ] then echo "LVS of RealServer Stopped." else echo "LVS of RealServer Running." fi else echo "LVS of RealServer Running." fi ;; *) echo "Usage:$0{start|stop}" exit 1 ;; esac |