MySql常用的一些关键字
主要是做个记录,免得忘了要到处找
DATE_FORMAT(时间字段, '%Y-%m'):截取Date类型的时间字段,例如2019- 08-03可以拆分成2019-08
其他参数:https://www.w3school.com.cn/sql/func_date_format.asp
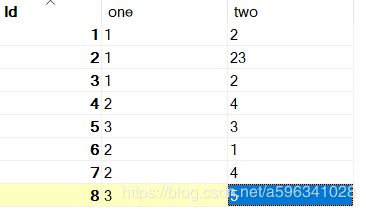
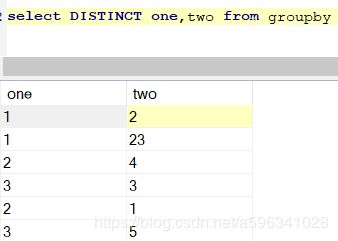
DISTINCT :去除重复字段(如果查询多字段,需要字段相等才会去重),例:
数据库字段: 查询字段:
| AVG(column) | 返回某列的平均值 |
| COUNT(column) | 返回某列的行数(不包括 NULL 值) |
| COUNT(*) | 返回被选行数 |
| FIRST(column) | 返回在指定的域中第一个记录的值 |
| LAST(column) | 返回在指定的域中最后一个记录的值 |
| MAX(column) | 返回某列的最高值 |
| MIN(column) | 返回某列的最低值 |
| SUM(column) | 返回某列的总和 |
group by:根据字段进行分组,分组后不会对数据进行统计,需要手动进行统计 例如: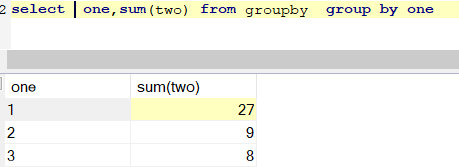
Having:having作用类似于where,group by 后面如果想接条件只能使用having
Order by:排序,默认升序(asc),desc降序,
子查询:可以在查询语句里面嵌套子查询,子查询的结果可以作为查询结果,可以作为where里面的条件
select (select SUM(tout.Onum) from tout join ting where tout.tid = ting.tid and ting.tlog = "苹果" and DATE_FORMAT(tout.Otime, '%Y-%m') between "2018-10" and "2018-11")/(select SUM(tout.Onum) from tout join ting where tout.tid = ting.tid and DATE_FORMAT(tout.Otime, '%Y-%m') between "2018-10" and "2018-11") as "苹果手机在2018年10月到2018年11月销量占比";
这句是我面试时写的,数据库已经没了所以无法展示效果
and和or:and是需要多个条件同时满足,例如id = 1 and id = 2这种情况是没法同时满足的,但是id = 1 and one = 1这种可以满足并查询出结果。
or语句只需要满足其中一边即可,如果两边同时满足则合并查询结果,例如 id = 1 or id = 3的结果就是两条结果,一个结果的id为1,一个结果的id为3
order by rand() limit 3:从表中随机查询三条数据
Like:模糊查询,用例
'%a' //以a结尾的数据
'a%' //以a开头的数据
'%a%' //含有a的数据
'_a_' //三位且中间字母是a的
'_a' //两位且结尾字母是a的
'a_' //两位且开头字母是a的Regexp:使用正则表达式,例如:WHERE name REGEXP '^st' name字段中以'st'为开头
union:将两个表的结果并在一起,但是两个表的列要一致,不能一个表有一个列另一个表有两个列,union会去重,如果想要重复的数据,需要使用union all
处理null:NULL表示的是“a missing unknown value”,而字符串''"是一个确定的值,NULL是指没有值,而''"则表示值是存在的,只不过是个空值,因此,在查询字段有null的时候,应该是 字段 is null 或者 字段 is not null,在排序时,null是一个无穷小的值
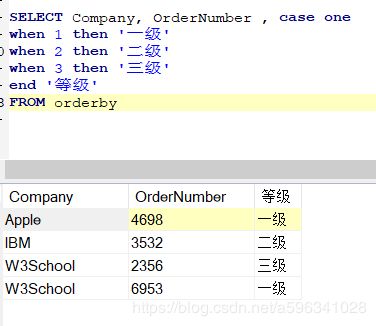
case when then else end:类似于switch
case :指定字段
when:当什么条件
then:满足上面的条件 就干什么
else:前面的条件都不满足
end:结束语
案例:
select:查询语句
select 字段 from 表 where 条件
select DATE_FORMAT(now(),'%m-%Y')
update:修改语句
update 表 set 字段 = 修改后的内容 where 条件
delete:删除语句(删除字段内容)
delete from 表 where 条件
insert:新增字段
insert into 表 (字段1,字段2) values (对应字段1,对应字段2),(对应字段1,对应字段2)
旧表字段插入到新表(表结构相同):INSERT INTO 新表 SELECT * FROM 旧表
旧表字段插入到新表(表结构不相同):INSERT INTO 新表(字段1,字段2,.......) SELECT 字段1,字段2,...... FROM 旧表
create table:创建表
create table if not exists:如果表不存在,则创建
CREATE TABLE IF NOT EXISTS `表名`(
`列名1` INT(数据类型) UNSIGNED(正数) AUTO_INCREMENT(自增),
`列名2` VARCHAR(100)(数据类型) NOT NULL(不为空),
`列名3` VARCHAR(40)(数据类型) NOT NULL(不为空),
`列名4` DATE(数据类型),
PRIMARY KEY ( `runoob_id` )(设置主键)
)
复制表:
CREATE TABLE 新表 SELECT * FROM 旧表 WHERE 1=2;(不会复制时的主键类型和自增方式的字段)
或
CREATE TABLE 新表 LIKE 旧表 ;(旧表的所有字段类型都复制到新表)
drop database:删除数据库
drop database <数据库名>
alter table: 表的字段操作
add:增加字段alter table 表名 add column 列名 varchar(30);
drop:删除列alter table 表名 drop column 列名
change :修改列名 alter table 表名 change 原名 新名 int;
modify :修改列属性alter table 表 modify 列名 varchar(22);
索引字段
- UNIQUE(唯一索引):不可以出现相同的值,可以有NULL值
- INDEX(普通索引):允许出现相同的索引内容
- PROMARY KEY(主键索引):不允许出现相同的值
- fulltext index(全文索引):可以针对值中的某个单词,但效率确实不敢恭维
- 组合索引:实质上是将多个字段建到一个索引里,列值的组合必须唯一
创建索引
alter table 表名 add 索引类型 (例如unique,primary key,fulltext,index)(字段名)