探索Redis设计与实现13:Redis集群机制及一个Redis架构演进实例
Redis实战(四) 集群机制
- 1. Replication(主从复制)
- 1.1. 配置主服务器
- 1.2. 配置从服务器
- 1.3. 测试
- 2. Sentinel(哨兵)
- 2.1. 配置Sentinel
- 2.2. 启动 Sentinel
- 2.3. 测试
- 3. Twemproxy
- 4. Codis
- 5. Redis 3.0集群
- 5.1. 环境搭建
- 5.2. 创建集群
转自http://blog.720ui.com/2016/redis_action_04_cluster/
下面介绍Redis的集群方案。
Replication(主从复制)
Redis的replication机制允许slave从master那里通过网络传输拷贝到完整的数据备份,从而达到主从机制。为了实现主从复制,我们准备三个redis服务,依次命名为master,slave1,slave2。
配置主服务器
为了测试效果,我们先修改主服务器的配置文件redis.conf的端口信息
- port 6300
配置从服务器
replication相关的配置比较简单,只需要把下面一行加到slave的配置文件中。你只需要把ip地址和端口号改一下。
- slaveof 192.168.1.1 6379
我们先修改从服务器1的配置文件redis.conf的端口信息和从服务器配置。
- port 6301
- slaveof 127.0.0.1 6300
我们再修改从服务器2的配置文件redis.conf的端口信息和从服务器配置。
- port 6302
- slaveof 127.0.0.1 6300
值得注意的是,从redis2.6版本开始,slave支持只读模式,而且是默认的。可以通过配置项slave-read-only来进行配置。
此外,如果master通过requirepass配置项设置了密码,slave每次同步操作都需要验证密码,可以通过在slave的配置文件中添加以下配置项
- masterauth
测试
分别启动主服务器,从服务器,我们来验证下主从复制。我们在主服务器写入一条消息,然后再其他从服务器查看是否成功复制了。
Sentinel(哨兵)
主从机制,上面的方案中主服务器可能存在单点故障,万一主服务器宕机,这是个麻烦事情,所以Redis提供了Redis-Sentinel,以此来实现主从切换的功能,类似与zookeeper。
Redis-Sentinel是Redis官方推荐的高可用性(HA)解决方案,当用Redis做master-slave的高可用方案时,假如master宕机了,Redis本身(包括它的很多客户端)都没有实现自动进行主备切换,而Redis-Sentinel本身也是一个独立运行的进程,它能监控多个master-slave集群,发现master宕机后能进行自动切换。
它的主要功能有以下几点
- 监控(Monitoring):不断地检查redis的主服务器和从服务器是否运作正常。
- 提醒(Notification):如果发现某个redis服务器运行出现状况,可以通过 API 向管理员或者其他应用程序发送通知。
- 自动故障迁移(Automatic failover):能够进行自动切换。当一个主服务器不能正常工作时,会将失效主服务器的其中一个从服务器升级为新的主服务器,并让失效主服务器的其他从服务器改为复制新的主服务器; 当客户端试图连接失效的主服务器时, 集群也会向客户端返回新主服务器的地址, 使得集群可以使用新主服务器代替失效服务器。
Redis Sentinel 兼容 Redis 2.4.16 或以上版本, 推荐使用 Redis 2.8.0 或以上的版本。
配置Sentinel
必须指定一个sentinel的配置文件sentinel.conf,如果不指定将无法启动sentinel。首先,我们先创建一个配置文件sentinel.conf
- port 26379
- sentinel monitor mymaster 127.0.0.1 6300 2
官方典型的配置如下
- sentinel monitor mymaster 127.0.0.1 6379 2
- sentinel down-after-milliseconds mymaster 60000
- sentinel failover-timeout mymaster 180000
- sentinel parallel-syncs mymaster 1
- sentinel monitor resque 192.168.1.3 6380 4
- sentinel down-after-milliseconds resque 10000
- sentinel failover-timeout resque 180000
- sentinel parallel-syncs resque 5
配置文件只需要配置master的信息就好啦,不用配置slave的信息,因为slave能够被自动检测到(master节点会有关于slave的消息)。
需要注意的是,配置文件在sentinel运行期间是会被动态修改的,例如当发生主备切换时候,配置文件中的master会被修改为另外一个slave。这样,之后sentinel如果重启时,就可以根据这个配置来恢复其之前所监控的redis集群的状态。
接下来我们将一行一行地解释上面的配置项:
- sentinel monitor mymaster 127.0.0.1 6379 2
这行配置指示 Sentinel 去监视一个名为 mymaster 的主服务器, 这个主服务器的 IP 地址为 127.0.0.1 , 端口号为 6300, 而将这个主服务器判断为失效至少需要 2 个 Sentinel 同意,只要同意 Sentinel 的数量不达标,自动故障迁移就不会执行。
不过要注意, 无论你设置要多少个 Sentinel 同意才能判断一个服务器失效, 一个 Sentinel 都需要获得系统中多数(majority) Sentinel 的支持, 才能发起一次自动故障迁移, 并预留一个给定的配置纪元 (configuration Epoch ,一个配置纪元就是一个新主服务器配置的版本号)。换句话说, 在只有少数(minority) Sentinel 进程正常运作的情况下, Sentinel 是不能执行自动故障迁移的。sentinel集群中各个sentinel也有互相通信,通过gossip协议。
除了第一行配置,我们发现剩下的配置都有一个统一的格式:
- sentinel
接下来我们根据上面格式中的option_name一个一个来解释这些配置项:
- down-after-milliseconds 选项指定了 Sentinel 认为服务器已经断线所需的毫秒数。
- parallel-syncs 选项指定了在执行故障转移时, 最多可以有多少个从服务器同时对新的主服务器进行同步, 这个数字越小, 完成故障转移所需的时间就越长。
启动 Sentinel
对于 redis-sentinel 程序, 你可以用以下命令来启动 Sentinel 系统
- redis-sentinel sentinel.conf
对于 redis-server 程序, 你可以用以下命令来启动一个运行在 Sentinel 模式下的 Redis 服务器
- redis-server sentinel.conf --sentinel
以上两种方式,都必须指定一个sentinel的配置文件sentinel.conf, 如果不指定将无法启动sentinel。sentinel默认监听26379端口,所以运行前必须确定该端口没有被别的进程占用。
测试
此时,我们开启两个Sentinel,关闭主服务器,我们来验证下Sentinel。发现,服务器发生切换了。
当6300端口的这个服务重启的时候,他会变成6301端口服务的slave。
Twemproxy
Twemproxy是由Twitter开源的Redis代理, Redis客户端把请求发送到Twemproxy,Twemproxy根据路由规则发送到正确的Redis实例,最后Twemproxy把结果汇集返回给客户端。
Twemproxy通过引入一个代理层,将多个Redis实例进行统一管理,使Redis客户端只需要在Twemproxy上进行操作,而不需要关心后面有多少个Redis实例,从而实现了Redis集群。
Twemproxy本身也是单点,需要用Keepalived做高可用方案。
这么些年来,Twenproxy作为应用范围最广、稳定性最高、最久经考验的分布式中间件,在业界广泛使用。
但是,Twemproxy存在诸多不方便之处,最主要的是,Twemproxy无法平滑地增加Redis实例,业务量突增,需增加Redis服务器;业务量萎缩,需要减少Redis服务器。但对Twemproxy而言,基本上都很难操作。其次,没有友好的监控管理后台界面,不利于运维监控。
Codis
Codis解决了Twemproxy的这两大痛点,由豌豆荚于2014年11月开源,基于Go和C开发、现已广泛用于豌豆荚的各种Redis业务场景。
Codis 3.x 由以下组件组成:
- Codis Server:基于 redis-2.8.21 分支开发。增加了额外的数据结构,以支持 slot 有关的操作以及数据迁移指令。具体的修改可以参考文档 redis 的修改。
- Codis Proxy:客户端连接的 Redis 代理服务, 实现了 Redis 协议。 除部分命令不支持以外(不支持的命令列表),表现的和原生的 Redis 没有区别(就像 Twemproxy)。对于同一个业务集群而言,可以同时部署多个 codis-proxy 实例;不同 codis-proxy 之间由 codis-dashboard 保证状态同步。
- Codis Dashboard:集群管理工具,支持 codis-proxy、codis-server 的添加、删除,以及据迁移等操作。在集群状态发生改变时,codis-dashboard 维护集群下所有 codis-proxy 的状态的一致性。对于同一个业务集群而言,同一个时刻 codis-dashboard 只能有 0个或者1个;所有对集群的修改都必须通过 codis-dashboard 完成。
- Codis Admin:集群管理的命令行工具。可用于控制 codis-proxy、codis-dashboard 状态以及访问外部存储。
- Codis FE:集群管理界面。多个集群实例共享可以共享同一个前端展示页面;通过配置文件管理后端 codis-dashboard 列表,配置文件可自动更新。
- Codis HA:为集群提供高可用。依赖 codis-dashboard 实例,自动抓取集群各个组件的状态;会根据当前集群状态自动生成主从切换策略,并在需要时通过 codis-dashboard 完成主从切换。
- Storage:为集群状态提供外部存储。提供 Namespace 概念,不同集群的会按照不同 product name 进行组织;目前仅提供了 Zookeeper 和 Etcd 两种实现,但是提供了抽象的 interface 可自行扩展。
Codis引入了Group的概念,每个Group包括1个Redis Master及一个或多个Redis Slave,这是和Twemproxy的区别之一,实现了Redis集群的高可用。当1个Redis Master挂掉时,Codis不会自动把一个Slave提升为Master,这涉及数据的一致性问题,Redis本身的数据同步是采用主从异步复制,当数据在Maste写入成功时,Slave是否已读入这个数据是没法保证的,需要管理员在管理界面上手动把Slave提升为Master。
Codis使用,可以参考官方文档https://github.com/CodisLabs/codis/blob/release3.0/doc/tutorial_zh.md
Redis 3.0集群
Redis 3.0集群采用了P2P的模式,完全去中心化。支持多节点数据集自动分片,提供一定程度的分区可用性,部分节点挂掉或者无法连接其他节点后,服务可以正常运行。Redis 3.0集群采用Hash Slot方案,而不是一致性哈希。Redis把所有的Key分成了16384个slot,每个Redis实例负责其中一部分slot。集群中的所有信息(节点、端口、slot等),都通过节点之间定期的数据交换而更新。
Redis客户端在任意一个Redis实例发出请求,如果所需数据不在该实例中,通过重定向命令引导客户端访问所需的实例。
Redis 3.0集群,目前支持的cluster特性
- 节点自动发现
- slave->master 选举,集群容错
- Hot resharding:在线分片
- 集群管理:cluster xxx
- 基于配置(nodes-port.conf)的集群管理
- ASK 转向/MOVED 转向机制
如上图所示,所有的redis节点彼此互联(PING-PONG机制),内部使用二进制协议优化传输速度和带宽。节点的fail是通过集群中超过半数的节点检测失效时才生效。客户端与redis节点直连,不需要中间proxy层。客户端不需要连接集群所有节点,连接集群中任何一个可用节点即可。redis-cluster把所有的物理节点映射到[0-16383]slot上cluster负责维护node<->slot<->value。
选举过程是集群中所有master参与,如果半数以上master节点与master节点通信超时,认为当前master节点挂掉。
当集群不可用时,所有对集群的操作做都不可用,收到((error) CLUSTERDOWN The cluster is down)错误。如果集群任意master挂掉,且当前master没有slave,集群进入fail状态,也可以理解成进群的slot映射[0-16383]不完成时进入fail状态。如果进群超过半数以上master挂掉,无论是否有slave集群进入fail状态。
环境搭建
现在,我们进行集群环境搭建。集群环境至少需要3个主服务器节点。本次测试,使用另外3个节点作为从服务器的节点,即3个主服务器,3个从服务器。
修改配置文件,其它的保持默认即可。
- # 根据实际情况修改
- port 7000
- # 允许redis支持集群模式
- cluster-enabled yes
- # 节点配置文件,由redis自动维护
- cluster-config-file nodes.conf
- # 节点超时毫秒
- cluster-node-timeout 5000
- # 开启AOF同步模式
- appendonly yes
创建集群
目前这些实例虽然都开启了cluster模式,但是彼此还不认识对方,接下来可以通过Redis集群的命令行工具redis-trib.rb来完成集群创建。
首先,下载 https://raw.githubusercontent.com/antirez/redis/unstable/src/redis-trib.rb。
然后,搭建Redis 的 Ruby 支持环境。这里,不进行扩展,参考相关文档。
现在,接下来运行以下命令。这个命令在这里用于创建一个新的集群, 选项–replicas 1 表示我们希望为集群中的每个主节点创建一个从节点。
- redis-trib.rb create --replicas 1 127.0.0.1:7001 127.0.0.1:7002 127.0.0.1:7003 127.0.0.1:7004 127.0.0.1:7005 127.0.0.1:7006
5.3、测试
一个Redis架构的演进实例
1. 写在前面
对于Redis相信各位程序猿童鞋都是不陌生的。这款使用ANSI C编写的,基于内存亦可持久化的数据库已经成为后端数据缓存炙手可热的首选。但Redis自身的短板也被大家所诟病,例如:在现今动不动就24核32核的服务器,Redis单线程的设计就无法利用好CPU资源;基于内存Redis在内存使用量巨大时,管理和维护显得十分困难和低效等。相信聪明的童鞋们一定会想到通过单机多实例Redis然后采用客户端分片的模式的方式解决上面的问题,确实这也是常见的方案。今天将给大家讲讲我们在这方面上的心路历程~
2. 最开始的Redis
Redis最早在我们线上的正式应用是一款儿童游戏。当时的游戏数据存储采用MySQL。数据库做了20个分库,存储也做了RAID阵列,游戏在线量较大时,数据库的IO压力依然非常大。为了减轻MySQL的压力,我们采用Redis对数据做了缓存,这也是我们在线上的第一次尝试这款nosql的新贵。
作为早期的架构方案设计也比较简单,就是四台服务器构成两组Redis主从的模型:
-
单机内存32G,开20个Redis实例。
-
主库不做AOF,也不做快照,每天凌晨定时做快照并异地迁移,从库开启AOF并1秒落地。
-
主库每5分钟插入一个时间点,方便从库AOF记录时间点,用于定点还原。
虽然架构简单不过确实极大地缓解了MySQL的压力,但弊端也开始显露:如果主Redis挂了,则借助从库手动做定点还原,还有程序层面涉及的一系列操作。而且故障无法自动转移,在线高时故障会给用户带来相当不好的体验,更不提运维攻城狮自己的苦逼了。
如果能实现故障自动转移,那也是极好的。那时年少,对未来充满了期待。
3. Redis sentinel的出现
业务高可用、故障自动转移一直是咱们运维攻城狮极力追求的。我们也是一步一个脚印地前进,努力往这目标迈进,大家有兴趣有阅读本公众号之前的文章《双机房灾备架构搭建实践》。
随着业务的发展,Redis开始越来越多地被我们所使用。尤其是在公共平台Redis几乎就是缓存的不二之选,同时对Redis故障自动转移的需求也越来越迫切。于是我们一开始采用官方推荐的Redis实例的监控管理工具:Redis-sentinel。
3.1 Redis sentinel剖析
Sentinel是多个Redis实例的监控管理工具,主要实现以下三个功能:
-
Monitoring: Sentinel 会不断地检查主Redis和从Redis是否运作正常。
-
Notification: 被监控的某个 Redis出现问题时,Sentinel 可以通过 API发送通知。
-
Automatic failover: 当主Redis不能正常工作时, Sentinel 会自动进行故障迁移操作,将Redis主从的角色进行互换。
3.2 Redis sentinel应用
Sentinel第一次在线上的应用是一款公共社交平台。
Redis用于DB缓存,通过同内网服务器搭建Redis主从模型,实现主Redis读写、从Redis落地。借助Sentinel的Automatic failover,主Redis故障时,自动切换Redis主从。我们的设计方案如下:

从上图可以看出,程序读写Redis都是通过VIP实现的。Keepalive借助vrrp_script检测当前Redis master是否异常以决定是否转移VIP,Sentinel实现故障时主从自动切换。Redis master不备份,定时脚本每晚检查当前Redis是否为slave,然后进行bgsave。由于设计为互备,主从故障切换后可以不进行回切。
Sentinel + keepalive在实现Redis故障转移这块确实帮了我们很大的忙,但在实际应用时也需要遇到了以下问题:
-
Sentinel存在网络分区的问题,会受到网络影响造成误判。
-
当面对业务规模较大,甚至需要进行扩容时,Sentinel的功能就显得有些捉襟见肘。
-
Keepalive的VIP切换存在约40ms延迟,程序设计前期需要考虑网络链接的异常处理。
4. Redis cluster践行
4.1 Redis cluster窥视
Redis cluster是一个去中心化、多实例Redis间进行数据共享的集群。由于被设计为无中心节点和无代理节点,Redis cluster可以实现集群节点的在线线性伸缩,并通过主从复制模型来提供一定程度的高可用行,在实际环境中某个节点故障不可用时,集群其他节点可以持续提供服务。

关于数据分片,Redis cluster并没有采用一致性hash,而是引入了hash slot。整个集群共有16384个slot,这些slot被全部分配在各个节点中,并且可以在不同节点间迁移。而每个slot存放哪些数据是由key通过CRC16校验后对16384取模来决定的。
为了使集群中部分节点故障或者失去联系的情况下集群其他节点可以提供持续服务,Redis cluster 采用主从复制模型。简单的说,就是每个对外提供服务的节点,我们称之为master节点,并为每个master节点提供一个slave节点。当其中一个master节点故障时,其slave节点替代原有的master节点,以保证不会因为找不到slot而使整个集群不可用。
4.2 Redis cluster应用
Redis cluster所具备的水平伸缩能力和高可用性开始逐渐被我们业务所青睐。
Redis cluster目前主要应用于后端大数据平台,常见配置都是借助高配机部署4个8G内存的Redis实例组建4个master节点的集群,必要时直接通过同内网物理机扩容节点即可,非常方便。在需求量比较大的场景,比如我们的云推送平台,更是借助96G内存的超配机部署单实例10G的集群。下图是其中一个实例内存使用情况:

在后端业务的架构中,由于Redis处于缓存层,借助cluster-require-full-coverage参数,允许我们的集群一个节点故障而业务依然可以正常运行,因此在设计上,我们取消了slave节点,将所有实例都成为master。
运维、开发以及业务方积极的沟通协作,加之集群灵活的伸缩能力,让我们可以在业务高峰来临前及时扩容集群,无缝平滑对业务提供支持,在业务量减小时,可以做必要的集群收缩。及时的扩容、必要的收缩既是为了保障业务持续稳定,也是为了合理高效地利用资源。
5. Redis cluster实践
说了这么多,相信大家并不满足于理论性的介绍。笔者就给大家讲解Redis cluster的实践方式。
我们通过四个Redis实例构成集群。注意:Redis cluster需要3.0以上的版本。限于边幅Redis部署过程就略去了,下面是集群每个节点需要的配置:
# cluster
cluster-enabled yes
#集群配置文件,由集群自动维护,不可人工编辑
cluster-config-file nodes${port}.conf
#节点失联时间,超过这个时间,该节点就被认为是故障
cluster-node-timeout 15000
#只有一个master节点失效时仍然提供服务
cluster-require-full-coverage no
5.1 创建集群
使用redis-trib.rb命令的create选项来创建四个master节点的集群,命令如下:
redis-trib.rb create 127.0.0.1:6001 127.0.0.1:6002 127.0.0.1:6003 127.0.0.1:6004使用redis-trib.rb命令的check选项来瞄一眼刚刚创建的集群:
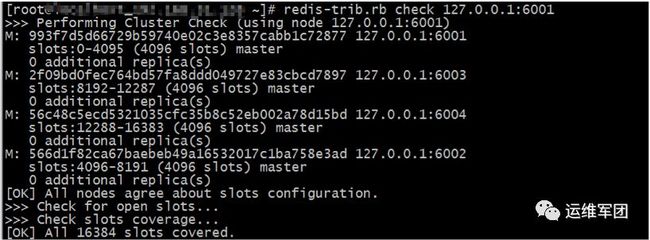
可以看到四个节点在集群中的角色都是master,并且每个节点都持有4096个slot。
5.2 伸缩集群
现在我们模拟一个情景:线上业务压力剧增,现有的集群压力巨大,我们需要对集群进行扩容并且不中断业务。
在开始之前,我们在后台跑个小脚本,让它不间断对集群写入数据:
for i in `seq 6000`
do
redis-cli -c -h 127.0.0.1 -p 6001 set key"$i" value"$i"
sleep 1s
done新增节点可以使用redis-trib.rb 命令的add-node选项,命令如下:
redis-trib.rb add-node 127.0.0.1:6005 127.0.0.1:6001目前Redis cluster还无法自动为新加入的加点分配slot,需要管理员手动分配,算是一个短板。使用redis-trib.rb 命令的reshard选项,给新节点分配100个slot吧,命令如下:
redis-trib.rb reshard --from ${src_node_id} --to${dist_node_id} --slots 100 --yes 127.0.0.1:6001
上面这条命令很easy,从${src_node_id} 节点迁移100个slot到${dist_node_id}节点的。我们来看看命令的执行结果:

如上图,新增的master节点不仅拥有了100个slot,同时还有数据。这也就说明了,slot的迁移其实也就是数据的迁移。
也许童鞋们觉得笔者很抠门,新的master节点才给100个slot。没关系redis-trib.rb命令的rebalance选项可实现slot在所有节点间均衡分配,这里就不做赘述了,就留给大家当做课后作业。
现在让我们来试试将集群收缩吧。假设业务已经平稳度过高峰期,4个节点完全能扛得住压力,需要去掉6005这个节点。
将一个节点从集群中剔除,首先要做的是将该节点的数据迁移至集群其他节点,也就是slot全部转移到集群其他节点。Slot迁移通过上面的介绍大家都知道通过redis-trib.rb命令的reshard选项来实现,就不再复述了。6005节点的slot都迁移到6004节点,得到的结果应该是:6005节点“0 keys 0 slots”。
其次使用redis-trib.rb命令的del-node选项来将节点从集群中去除,命令如下:
redis-trib.rb del-node 127.0.0.1:6005 ${del_node_id}看看效果:

至此我们就完成了一次集群的收缩工作。
童鞋们注意:对集群进行扩容收缩的工作,实际就是对slot的迁移,意味着进行数据迁移,过程挺消耗性能的,因此建议大家及时根据业务趋势提前做好评估和规划工作,避免在高峰时段给服务器增加额外的压力。
5.3 健壮集群
如前面描述Redis cluster采用主从复制模型来避免个别节点故障失联而导致集群不可用。相信这会是各位童鞋最期待的。
依旧是启用一个新的Redis6005实例,为6004节点增加一个slave节点,命令如下:
redis-trib.rb add-node --slave --master-id ${master_node_id} 127.0.0.1:6005 127.0.0.1:6001我们看看此时的集群状态:

看图中红框框的部分,这里表明了他俩是一对master/slave 。
现在failover掉6004节点(ps:进行failover节点必须是slave节点):

将6004节点failover后,6005应该提升为master节点替代6004,来看看现在的集群节点是不是如我们预期的:

从上面的信息可以看出,原有的master 6004已经降级为slave,而6005则升级为master替代6004,并且集群可以持续正常服务:

同理如6004节点恢复了,可在6004节点上执行cluster failover命令,让6005节点假故障,实现主从切换,恢复原有的集群状态。
线上的配置规划,如果服务器资源充裕的话,还是建议为每个master节点都配置slave,防止节点意外故障而导致集群无法使用。当然要是资源吃紧,也是可以在某些敏感时段进行临时配置slave,毕竟Redis cluster的伸缩都是很灵活的。
6. 结束语
以上就是我们在Redis上走过的路,相信会对大家对使用Redis上有帮助。技术选型其实并不是运维一言拍板,而是结合业务需求协调开发的基础上确定方案,并在业务程序开发前与开发者沟通注意事项。任何技术都有其优劣的方面,详细了解、提前规避风险、针对自身业务做好规划才是正确使用技术的方式。
redis哨兵主备切换的数据丢失问题:异步复制、集群脑裂
课程大纲
1、两种数据丢失的情况
2、解决异步复制和脑裂导致的数据丢失
------------------------------------------------------------------
1、两种数据丢失的情况
主备切换的过程,可能会导致数据丢失
(1)异步复制导致的数据丢失
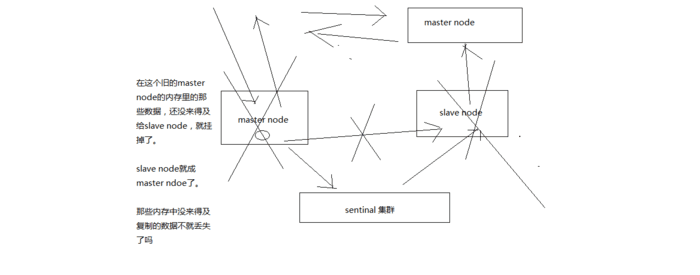
异步复制导致的数据丢失问题
因为master -> slave的复制是异步的,所以可能有部分数据还没复制到slave,master就宕机了,此时这些部分数据就丢失了
(2)脑裂导致的数据丢失

集群脑裂导致的数据丢失问题
脑裂,也就是说,某个master所在机器突然脱离了正常的网络,跟其他slave机器不能连接,但是实际上master还运行着
此时哨兵可能就会认为master宕机了,然后开启选举,将其他slave切换成了master
这个时候,集群里就会有两个master,也就是所谓的脑裂
此时虽然某个slave被切换成了master,但是可能client还没来得及切换到新的master,还继续写向旧master的数据可能也丢失了
因此旧master再次恢复的时候,会被作为一个slave挂到新的master上去,自己的数据会清空,重新从新的master复制数据
------------------------------------------------------------------
2、解决异步复制和脑裂导致的数据丢失
min-slaves-to-write 1
min-slaves-max-lag 10
要求至少有1个slave,数据复制和同步的延迟不能超过10秒
如果说一旦所有的slave,数据复制和同步的延迟都超过了10秒钟,那么这个时候,master就不会再接收任何请求了
上面两个配置可以减少异步复制和脑裂导致的数据丢失
(1)减少异步复制的数据丢失

异步复制导致数据丢失如何降低损失
有了min-slaves-max-lag这个配置,就可以确保说,一旦slave复制数据和ack延时太长,就认为可能master宕机后损失的数据太多了,那么就拒绝写请求,这样可以把master宕机时由于部分数据未同步到slave导致的数据丢失降低的可控范围内
(2)减少脑裂的数据丢失

脑裂导致数据丢失的问题如何降低损失
如果一个master出现了脑裂,跟其他slave丢了连接,那么上面两个配置可以确保说,如果不能继续给指定数量的slave发送数据,而且slave超过10秒没有给自己ack消息,那么就直接拒绝客户端的写请求
这样脑裂后的旧master就不会接受client的新数据,也就避免了数据丢失
上面的配置就确保了,如果跟任何一个slave丢了连接,在10秒后发现没有slave给自己ack,那么就拒绝新的写请求
因此在脑裂场景下,最多就丢失10秒的数据
作者:踏雪无痕722
链接:https://www.jianshu.com/p/f6ceae73c7ae
來源:简书
简书著作权归作者所有,任何形式的转载都请联系作者获得授权并注明出处。
微信公众号
个人公众号:程序员黄小斜
微信公众号【程序员黄小斜】新生代青年聚集地,程序员成长充电站。作者黄小斜,职业是阿里程序员,身份是斜杠青年,希望和更多的程序员交朋友,一起进步和成长!专注于分享技术、面试、职场等成长干货,这一次,我们一起出发。
关注公众号后回复“2020”领取我这两年整理的学习资料,涵盖自学编程、求职面试、算法刷题、Java技术学习、计算机基础和考研等8000G资料合集。

技术公众号:Java技术江湖
微信公众号【Java技术江湖】一位阿里 Java 工程师的技术小站,专注于 Java 相关技术:SSM、SpringBoot、MySQL、分布式、中间件、集群、Linux、网络、多线程,偶尔讲点Docker、ELK,同时也分享技术干货和学习经验,致力于Java全栈开发!
关注公众号后回复“PDF”即可领取200+页的《Java工程师面试指南》强烈推荐,几乎涵盖所有Java工程师必知必会的知识点。
