从b+ tree底层分析索引以及优化
什么是索引
数据库索引,是数据库管理系统(DBMS)中一个排序的数据结构,以协助快速查询、更新数据库表中数据。

大家看下上面的图就很清晰明了了,索引就是查字典嘛,比如说我要去字典里面找个帅字,你肯定不会从头找到尾,一页一页翻吧,你肯定是先去目录,通过拼音或者偏旁找到帅字在第几页,然后在去对应的页查看。
索引类型以及创建索引
不管网上是怎么分类的,我这里把索引分为四类,我们打开navicat,选中一张表右击设计表,然后点索引,打开索引类型的下拉,一共有FULLTEXT、NORMAL、SPATIAL、UNIQUE四种,这里介绍其中三种。
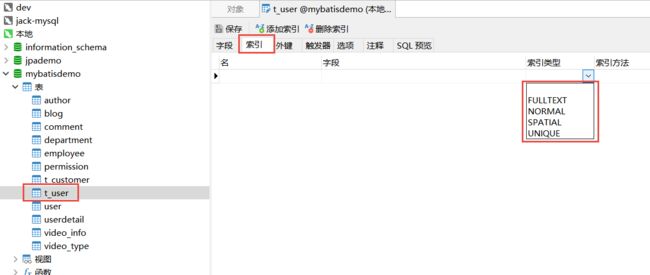
普通索引
也叫非唯一索引,是最普通的索引,没有任何的限制。
- 建表时添加,用index或key关键字创建
CREATE TABLE mytable (
name VARCHAR(32) ,
INDEX index_mytable_name (name)
);
- 建表后添加
ALTER TABLE table_name ADD INDEX index_name(column);
唯一索引
唯一索引要求键值不能重复。(注:主键索引是一种特殊的唯一索引,它多了一个限制条件,要求键值不能为空)。
- 建表时添加,用 unique index 或 unique key 创建
CREATE TABLE mytable2 (
`name` VARCHAR(32) ,
unique index index_unique_mytable_name (`name`)
);
- 建表后添加
ALTER TABLE mytable ADD UNIQUE INDEX index_mytable_name (name);
主键索引用 primay key 创建。
全文索引
针对比较大的数据,比如我们存放的是消息内容,有几 kb 的数据的这种情况,如果要解决 like ‘%jack xu%’ 这种低效查询的问题,可以创建全文索引。只有文本类型的字段才可以创建全文索引,比如 char、varchar、text。
- 全文索引,用 fulltext index 或者 fulltext key 创建
create table fulltext_test (
id int,
content text ,
fulltext index (content)
);
插入一些数据

注意:当我们用的时候不是用 like ‘%jack xu%’ 这样写的,他有特殊的语法用 match 和 against 操作,使用如下。
select * from fulltext_test where MATCH (content) AGAINST('fulltext' IN NATURAL LANGUAGE MODE);
MySQL的存储
这是在讲索引的数据结构之前的预知识,这样才能更好的理解索引。MySQL 的存储结构分为 5 级:表空间、段、簇、页、行。
系统从磁盘读取数据到内存时是以磁盘块(block)为基本单位的,位于同一磁盘块中的数据会被一次性读取出来,而不是按需读取。这个小伙伴可以理解吧,比如说我要从数据库拿一个d,他不会傻傻的只拿d,而是会把相邻的abcdefg都拿出来,先放在内存里面备着。
InnoDB 存储引擎使用页作为数据读取单位,页是其磁盘管理的最小单位。
文件系统中,也有页的概念。在许多操作系统中,页大小通常为4k,主存和磁盘以页为单位交换数据。InnoDB 默认 page 大小是 16k 。

索引的数据结构
之前说过索引是一种数据结构,那么它到底应该选择一种什么数据结构,才能实现数据的高效检索呢?
下面我们来分析一下,先打开这个网站,选择对应的结构来创建树。
https://www.cs.usfca.edu/~galles/visualization/Algorithms.html

二叉树 (BST Binary Search Tree)

但是二叉查找树有一个问题:它的查找耗时和这棵树的深度相关,在最坏的情况下会退化成一个链表,时间复杂度会退化成O(n),如下所示。

这种情况下不能达到加快检索速度的目的,和顺序查找效率是没有区别的,还是从头找到尾嘛,为了解决这个问题,我们使用平衡二叉树。
平衡二叉树 (AVL Tree )
平衡二叉树英文名也叫 Balanced binary search trees,为什么叫 AVL 呢,因为这是其发明者姓名的简写。我们用上面链表的数据用平衡二叉树在插入一遍,平衡二叉树会将其进行旋转,使其左右子树深度差绝对值不能超过1,如下所示。
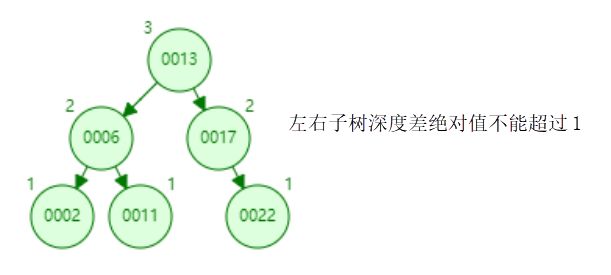
我们看下如果以平衡二叉树作为索引结构的话,他的存储方式是这样子的,一个磁盘块就是一页,也就是16k,在磁盘块上存储键值、数据磁盘地址和子节点的引用,这么多加起来也就几十个字节,而16k*1024=16384个字节,远远造成了浪费。当我们查询 id=37 的时候,要查询两个子节点,就需要跟磁盘交互 3 次,如果我们有几百万的数据的话,IO的次数将是非常多次。
红黑树(Red Black Tree)
我们知道 AVL 树在不停的旋转,来保证最长子树和最短子树高度差不能超过1,损失了插入性能来提高查询的性能,所以我们想到尽可能的将插入性能和查询性能取一个平衡,这时候就出现了红黑树,红黑树也是 BST 树,但是他对平衡的条件放宽了。
红黑树必须满足 5 个约束:
1、节点分为红色或者黑色。
2、根节点必须是黑色的。
3、叶子节点都是黑色的 NULL 节点。
4、红色节点的两个子节点都是黑色(不允许两个相邻的红色节点)。
5、从任意节点出发,到其每个叶子节点的路径中包含相同数量的黑色节点。

上面做了这么多的规则,最终是为了保证一点:从根节点到叶子节点的最长路径不大于最短路径的2倍。正是因为平衡不是那么严格,所以在 java 中,比如 TreeMap 和 HashMap 用的是红黑树,而没有用AVL树。
不管是 AVL 树还是红黑树都是只有两路,树的深度很深,需要 IO 的次数也多,所以在数据库中没有使用他们做索引。我们要从他们高瘦高瘦的样子,变为矮胖矮胖的样子,这时候 b 树就登场了。
多路平衡查找树 (B Tree )
Balanced Tree 分叉数(路数)永远比关键字数多 1。比如我们画的这棵树,每个节点存储两个关键字,那么就会有三个指针指向三个子节点。
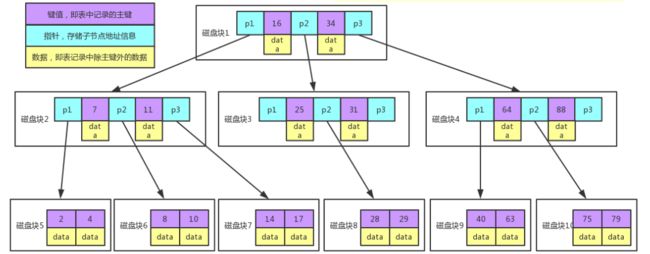
我们来看下他的查找过程,如果我们要找 16,那查找第一个磁盘块的时候就能命中,取到 16 的数据。如果我们要查找 28,看下过程:
1、根据根节点找到磁盘块1,读入内存。(1次IO)
2、比较28在区间(16,34),找到磁盘块1的指针p2。
3、根据p2指针找到磁盘块3,读入内存。(2次IO)
4、比较28在区间(25,31),找到磁盘块3的指针p2。
5、根据p2指针找到磁盘块8,读入内存。(3次IO)
6、在磁盘块8中找到28的数据。
我们看下一共经过了三次IO就找到了,比起 AVL 树来效率大大提升,但是在 MySQL 的 Innodb 里并没有选用 b 树来做索引的数据结构,而是选用了他的变种 b+ 树,我们来看下有什么好处。
加强版多路平衡查找树 (B+ Tree )
我们看下 b+ 树的两个特点:
1、它的关键字的数量是跟路数相等的。
2、B+Tree 的根节点和支节点中都不会存储数据,只有叶子节点才存储数据。搜索到关键字不会直接返回,会到最后一层的叶子节点。比如我们搜索 id=28,虽然在第一层直接命中了,但是全部的数据在叶子节点上面,所以我还要继续往下搜索,一直到叶子节点。
3、每个叶子节点增加了一个指向相邻叶子节点的指针,它的最后一个数据会指向下一个叶子节点的第一个数据,形成了一个有序链表环的结构。
4、它是根据左闭右开的区间 [ )来检索数据。

这样做有什么好处呢?我们知道每页存储空间是有限的,是 16k,b 树中存储 data,如果 data 比较大的话导致每个节点存储的 key 的数量变小,从而导致路数变少。而 b+ 树中不存储data,路数变多,树的深度减小,IO次数减少,效率大大提升。
我们来简单算下,假设索引字段是 bigint 类型,长度为 8 字节。指针大小在 InnoDB 源码中设置为
6 字节,这样一共 14 字节。非叶子节点一页可以存储 16384/14=1170 个这样的单元(键值+指针),代表有 1170 个指针。两层就是1170 * 1170=1368900 路,叶子节点一条数据是 1k,一页就是能放 16 条记录,那这样的一个三层 b+树一共能放1368900 * 16=21902400条记录,所以在 InnoDB 中 b+ 树深度一般为 1-3 层,它就能满足千万级的数据存储。
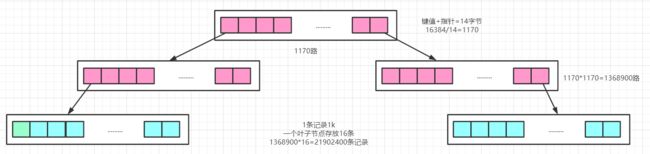
另一个使用链表环结构以后,当我们要进行顺序或者范围查找 where id>28 and id<66 的时候,只要先找到 28 所在的位置,依次往后找就行了,而不用每个值都经过 3 次 IO 才找到。
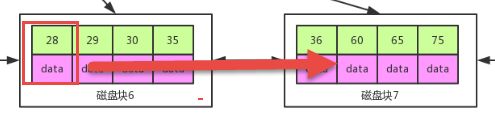
最后查找更稳定,b 树中可能经过一次 IO 找到,可能经过两次 IO 找到,可能经过三次 IO 找到,而 b+ 树中因为数据都存放在叶子节点,即使你第一次就命中了,也要到叶子节点才能将数据取出,所有 IO 次数是一样的。
索引的落地
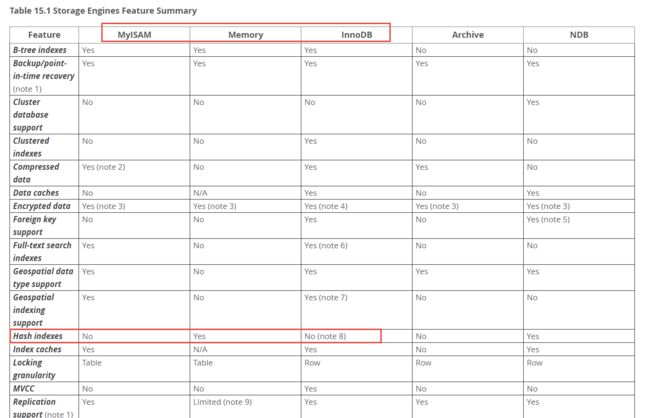
经过上面的一系列分析,我们最终得出结论,在 MySQL中使用 b+ tree 作为索引,那到底是不是这样的呢?我们打开 navicat 看下,索引方法有 BTREE 和 HASH,这里的 BTREE 指的就是 b+ tree,而 HASH 大家不要被误解,你是不能手动指定的,就算你指定的是 HASH,他最终存储的还是 b+ tree。

我们打开下面的官网看下,https://dev.mysql.com/doc/refman/5.7/en/storage-engines.html , 在 MyISAM 和 InnoDB 中使用的都是 b+ 树,而 Memory 存储引擎使用的是 Hash 索引。
MyISAM
使用命令查看一下数据文件存放的地址
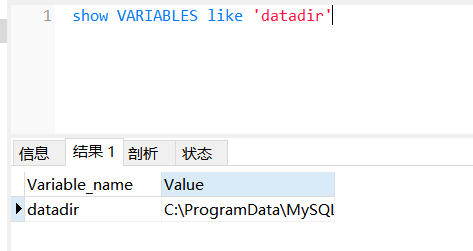
进入目录以后发现my_table这张表有三个文件,.frm存放表结构文件,.MYI存放索引数据,.MYD存放实际数据,数据和索引是分开存放的。

这里 Id 是主键索引,Name 是辅助索引,他们都存放在 myi 文件中,通过索引找到地址后再去myd 中查找具体的值。
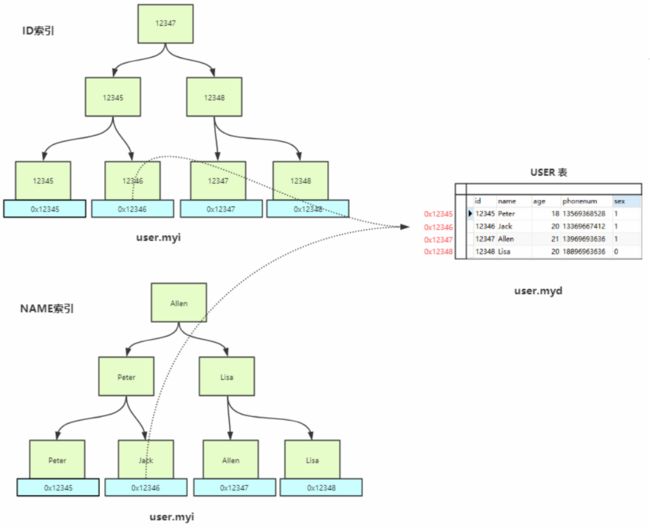
InnoDB
InnoDB存储引擎默认情况下会把所有的数据文件放到表空间中,不会为每一个单独的表保存一份数据文件,如果需要将每一个表单独使用文件保存,设置如下属性:set global innodb_file_per_table=on;
在 InnoDB 中只有两个文件,frm还是存放表结构的,.ibd文件中索引和数据都存放在一起。

主键索引 Id 里存储的就是具体的数据,而 Name 辅助索引中存储的是主键 id 的值,然后再通过 id 去主键索引中拿到数据,这个过程叫做回表。

聚集索引:指数据库表行中数据的物理顺序与键值的逻辑(索引)顺序相同。这个就好比字典的目录是按拼音排序的,而内容也是按拼音排序的,按拼音排序的这种目录就叫聚集索引。
注意:
- 一个表只能有一个聚集索引,因为一个表的物理顺序只有一种情况。
- 在InnoDB引擎中,主键索引是聚集索引,其他的索引都是非聚集索引。
- 如果没有主键, InnoDB 会选择第一个不包含有 NULL 值的唯一索引作为主键索引,如果也没有这样的唯一索引,那么会选择内置 6 字节长的 ROWID 作为隐藏的聚集索引。
select _rowid name from t2;
建立优秀的索引
列的离散度
我们看下列的离散度的公式:count(distinct(column_name)) : count(*),简而言之,列的重复值越多,离散度就越低,比如说性别就是010101001010101。而如果我们将索引建在离散度低的列上,这样的索引的效率是低的,因为需要扫描的行数多。

就像下面一样,基本就是全表扫描了嘛,此时索引建和不建就没差别了。

联合索引(最左匹配原则)
ALTER TABLE user_innodb add INDEX comidx_name_phone (name,phone);
我们创建上面这个联合索引,它是按照从左到右的顺序来建立搜索树的 name 在左边,phone 在右边。name 是有序的,phone 是无序的,当 name 相等的时候,phone 才是有序的。
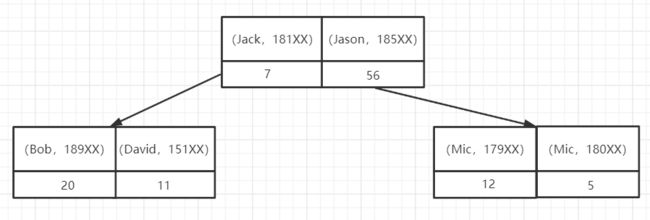
基于联合索引的最左匹配原则,下面哪些可以用到联合索引呢?我们可以肯定的是,1和3用到,4用不到,而 2 看上去 phone 在前面,用不到联合索引,但其实优化器会帮我们优化成 where name=‘jack xu’ and phone='13666666666’的,所以也能用到的。
- select * from user_innodb where name=‘jack xu’ and phone=‘13666666666’ ;
- select * from user_innodb where phone=‘13666666666’ and name=‘jack xu’;
- select * from user_innodb where name=‘jack xu’;
- select * from user_innodb where phone=‘13666666666’;
注意:我们在创建联合索引 index(a,b,c) 的时候,相当于创建了 index(a)、index(a,b)、index(a,b,c) 这三个索引,所以小伙伴不要重复创建,造成浪费,索引不是多多益善的。
覆盖索引
通过索引项的信息可以直接返回所查询的列,则该索引称为查询 SQL 的覆盖索引。
我们在看上面联合索引的图,当我查询 name , phone 和 id 的时候,直接在索引中就能取到了,而第四条 select * 的时候,需要回表通过 id 再去主键索引中拿到完整行的信息。
- select name from user_innodb where name=‘jack xu’;
- select phone from user_innodb where name=‘jack xu’;
- select id from user_innodb where name=‘jack xu’;
- select * from user_innodb where name=‘jack xu’;
注意:尽量使用覆盖索引,查什么字段用什么字段,因为它能加快我们的查询速度。
索引下推
MySQL5.7索引下推默认是开启的.
set optimizer_switch='index_condition_pushdown=on';
我们还是看上面联合索引的图
首先我们要知道一点,索引的过滤是在存储引擎进行,数据的过滤是在 Server 层进行。现在我们要查询 where name=‘Mic’ and phone=‘179666666666’,现在有两种方式:
1、根据联合索引查出所有姓名是 Mic 的二级索引数据,然后回表,到主键索引上查询全部符合条件的数据(2 条数据)。然后返回给 Server 层,在 Server 层过滤出手机号是179666666666 的数据。
2、根据联合索引查出所有姓名是 Mic 的二级索引数据( 2 个索引),然后从二级索引中筛选出手机号是 179666666666 的索引(1 个索引),然后再回表,到主键索引上查询全部符合条件的数据(1 条数据),返回给 Server 层。
小伙伴觉得哪种方式好,显然是第二种,现在是只有 2 条数据,当有 10000 条数据的时候,在存储引擎层就可以过滤掉 9999 条,减少访问表的完整行的读数量从而减少 I/O 操作。
建立优秀的索引
1、在用于 where 判断 order 排序和 join 的(on)字段上创建索引,减少扫描行数,越精确越好。
2、索引的个数不要过多,浪费空间,更新变慢。
3、区分度低的字段,例如性别,不要建索引,离散度太低。
4、频繁更新的值,不要作为主键或者索引。维护索引是要消耗性能的,维护索引会造成页分裂和合并。
5、联合索引把散列性高(区分度高)的值放在前面。
6、创建联合索引,而不是修改单列索引。
7、使用覆盖索引,减少回表操作。
8、不建议用无序的值(例如身份证、UUID )作为索引,用自增主键,Id自增页都连续的,而无序的会导致页分裂。
9、过长的字段,使用fullText索引或者使用前缀索引。
能否用到索引
1、索引列上使用函数( replace \SUBSTR \ CONCAT \ sum count avg )、表达式、
计算(+ - * /):
explain SELECT * FROM `t2` where id + 1 = 4; [错误做法]
这里我们换下顺序,因为按照id + 1索引都不知道怎么走了,我们应该算好以后让索引走。
explain SELECT * FROM `t2` where id = 4 - 1; [正确做法]
2、字符串不加引号,出现隐式转换
explain SELECT * FROM `user_innodb` where name = 136; [错误做法]
这里name是字串符格式,不加引号也能查,但是会出现隐式转换,导致不走索引。
explain SELECT * FROM `user_innodb` where name = '136'; [正确做法]
3、like 条件中前面带%
select *from user_innodb where name like '%xu';[错误做法]
这里按照最左匹配原则,jack%是可以走索引的,而%xu索引谁知道怎么走。另外对于like开销太大,可以使用全文索引。
select *from user_innodb where name like 'jack%';[正确做法]
4、负向查询
NOT LIKE 不走索引:
select * from user_innodb where last_name not like 'xu'
!= (<>)和 NOT IN 可能走可能不走:
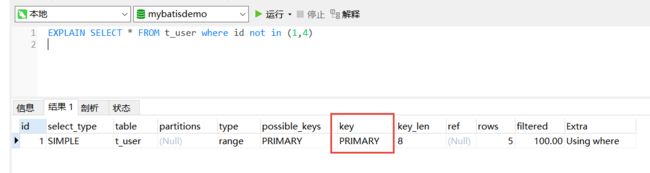
select * from user_innodb where id not in (1)
select * from user_innodb where id <> 1
我们做下实验,可以看到用到了主键索引,我的天呢,我们按照对 b+ 树的索引结构的理解,理论上是用不到的啊,因为索引他不知道怎么走怎么查找,但实际还是用到了。
总结
一个 SQL 语句是否使用索引,跟数据库版本、数据量、数据选择度都有关系。其实,用不用索引,最终都是优化器说了算。
优化器又分为基于 cost 开销(Cost Base Optimizer)和基于规则(Rule-Based Optimizer),但是我们大多数是基于 CBO 的,毕竟我们保证性能优先,基于规则 RBO 有这么多规则:
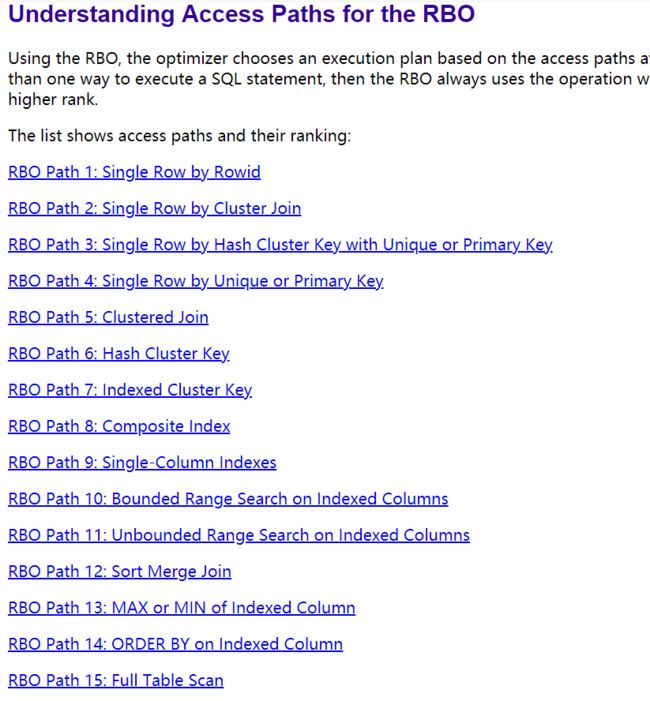
所以当我们在用 CBO 的时候,即使我们现在了解了一些 b+ tree 底层的原则,但是 CBO 是没有具体的细则的,我们不好说什么情况下一定使用,什么情况下一定不使用,具体有没有用到,用到了哪些索引,我们只能用 explain 来查看。
最后本文通过从 b+ tree 底层来分析索引,以及创建索引时候的一些规则,希望给大家在工作中带来一些帮助。最后原创不易,如果你觉得写的不错,请点一个赞!