python 面试题 1.1(简答类)
文章目录
- 1、python和其他语言的区别
- 2、解释性语言和编译性语言
- 3、python几种解释器的特点
- 4、位和字节的关系
- 5、PEP8(python代码规范)
- 6、列举布尔值为false的常见值
- 7、python递归的最大层数
- 8、ascii、unicode、utf-8、gbk 区别
- 9、字节码和机器码的区别
- 10、三元运算规则以及应用场景
- 11、Python2和3的区别
- 12、is和==
- 13、python里有哪些数据类型(可变、不可变)
- 14、赋值、深浅拷贝
- 15、python垃圾回收机制(cpython)
- 16、列举常见内置函数
- 17、列举常用模块
- 18、生成器、迭代器、可迭代对象
- 19、re的match和search区别
- 20、什么是正则的贪婪匹配
1、python和其他语言的区别
-
python是一种解释性语言与C语言和C的衍生语言不同,Python代码在运行之前不需要编译。其他解释型语言还包括PHP和Ruby。
-
Python是动态类型语言,指的是你在声明变量时,不需要说明变量的类型。你可以直接编写类似x=111和x="I’m a string"这样的代码,程序不会报错。
2、解释性语言和编译性语言
-
解释性语言:源代码—>中间代码—>机器语言,源代码不能直接翻译成机器语言,而是先翻译成中间代码,再由解释器对中间代码进行解释运行。
-
编译性语言:只须编译一次就可以把源代码编译成机器语言,后面的执行无须重新编译,直接使用之前的编译结果就可以;因此其执行的效率比较高;
| 解释性语言 | 编译性语言 |
|---|---|
| Python、JavaScript、Shell、Ruby、MATLAB | C、C++、Pascal/Object Pascal(Delphi) |
| 每执行一次都要翻译一次 | 只须编译一次 |
| 执行效率一般 | 执行效率比较高 |
| 依赖解释器,跨平台性好 | 依赖编译器,跨平台性差 |
其中java比较独特,它是先编译成.class文件再通过 jvm解释运行

3、python几种解释器的特点
| 解释器 | 特点 |
|---|---|
| cpython | C语言编写、标准python、垃圾回收利用引用计数 |
| jpython | java编写、编译从jvm字节码由jvm执行、利用JVM的垃圾回收和JIT |
| IronPython | c#编写、在CLR上实现了Python、面向.NET平台、可以利用.NET框架的JIT、垃圾回收等功能 |
| PyPy | 使用RPython实现,利用Tracing JIT技术实现的Python、PyPy可以选择多种垃圾回收方式,如标记清除、标记压缩、分代等、pypy性能提升非常明显但第三方库支持不够 |
4、位和字节的关系
1字=2字节 (1 word = 2 byte)
1字节=8位 (1 byte = 8bit 或简写为:1B=8b)
| 术语 | 区别 |
|---|---|
| 位 bit | 计算机基本储存单元、只能容纳0或1 |
| 字节 byte | 常用的计算机存储单位、一个字节均为8位,每个位是0或1 |
| 字 word | 自然储存单元、计算机进行数据处理时,一次存取、加工和传送的数据长度称为字 |
一个英文字符和英文标点占一个字节,一个中文字符和中文标点占用2个字节
一个字通常由一个或多个(一般是字节的整数位)字节构成。例如 286 微机的字由 2 个字节组成,它的字长为 16;486 微机的字由 4 个字节组成,它的字长为 32 位。
计算机的字长决定了其 CPU 一次操作处理实际位数的多少,由此可见计算机的字长越大,其性能越优越。
5、PEP8(python代码规范)
| 缩进 | 每一级缩进使用4个空格 |
| 每行长度 | 每行最大长度79 |
| import | 按照以下顺序分组导入:标准库、相关第三方库、本地应用/库特定 |
| 类名 | 首字母大写 |
| 函数名 | 小写 |
| 函数方法和参数 | 始终要将 self 作为实例方法的的第一个参数、cls 作为类静态方法的第一个参数 |
| … | … |
6、列举布尔值为false的常见值
print("1. ", bool(0)) # 零
print("2. ", bool(-0))
print("3. ", bool(None)) # None
print("4. ", bool()) # 空
print("5. ", bool(False)) # false
print("6. ", bool([])) # 空列表
print("7. ", bool(())) # 空元组
print("8. ", bool({})) # 空字典
print("9. ", bool(0j)) # 复数0 在Python中,复数的虚部以j或者J作为后缀
print("10. ", bool(0.0)) # 浮点0
7、python递归的最大层数
默认的在window上的最大递归层数是998
# 验证
def foo(n):
print(n)
n += 1
foo(n)
if __name__ == '__main__':
foo(1)
#得到的最大数为998,以后就是报错了:RecursionError: maximum recursion depth exceeded while calling a Python object
8、ascii、unicode、utf-8、gbk 区别
| 编码 | 区别 |
|---|---|
| ascii | 美标、仅字母和符号等、1个字节 |
| unicode | 国际通用、所有文字、python默认字符编码(二进制) |
| utf-8 | unicode的一种实现方式、1~4字节、第一个字节和ascii兼容 |
| gbk | 国标、字母和中文、2个字节 |
需要注意的是,Unicode只是一个符号集,它只规定了符号的二进制代码,却没有规定这个二进制代码应该如何存储。
比如,汉字“严”的unicode是十六进制数4E25,转换成二进制数足足有15位(100111000100101),也就是说这个符号的表示至少需要2个字节。表示其他更大的符号,可能需要3个字节或者4个字节,甚至更多。
9、字节码和机器码的区别
| 机器码 | 字节码 |
|---|---|
| 学名机器语言指令 | 相当于2进制代码 |
| 由cpu直接执行 | 直译器转译后成为机器码 |
10、三元运算规则以及应用场景
三元运算:https://blog.csdn.net/a__int__/article/details/104981310?utm_source=po_vip
规则

应用场景
在赋值变量的时候,可以直接加判断
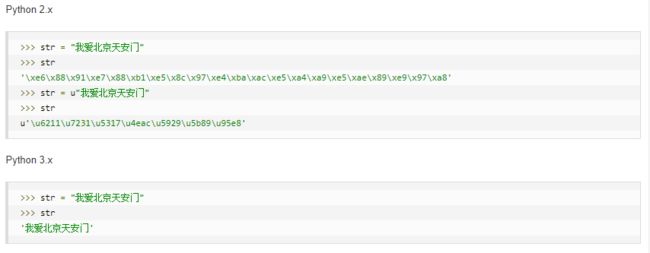
11、Python2和3的区别
来源1:https://www.runoob.com/python/python-2x-3x.html
来源2:https://www.cnblogs.com/kendrick/p/7478304.html
| python2 | python3 |
|---|---|
| print语句 | print()函数 |
| ASCII str() 类型,unicode() 是单独的,不是 byte 类型 | Unicode (utf-8) 字符串,以及一个字节类:byte 和 bytearrays。 |
| 除法:整数相除的结果是一个整数 | 除法:整数之间的相除,结果也会是浮点数 |
| 异常: except e, var | 异常:except e as var |
| range()和xrange() | 只有range(),用法同之前的xrange() |
| 八进制数可以写成0o777或0777 | 只能写成0o777 |
| 不等运算符: != 和 <> | 不等运算符:!= |
| 整型:int、long | 整型:只有int(但它的行为就像2.X版本的long),新增了bytes类型,对应于2.X版本的八位串 |
| 打开文件:file( … )或 open(…) | 打开文件:open(…) |
| 键盘录入:raw_input( “提示信息” )、input( “提示信息” ) | 键盘录入:仅保留input( “提示信息” ) |
| 老式类和新式类 | 统一采用新式类 |
新式类和老式类的区别:https://www.jianshu.com/p/eaa4d2371e2e
需要注意的是python2.6、2.7兼容部分python3语言
django1.5开始支持python3,django2.0以后仅支持python3
| django2 | django3 |
|---|---|
| 路由: url() | path() |
| {% load staticfiles %} | {% load static %} |
lxml的使用:
python2
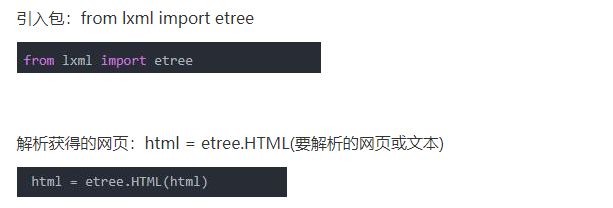
python3

12、is和==
- ==是python标准操作符中的比较操作符,用来比较判断两个对象的value(值)是否相等
- is也被叫做同一性运算符,这个运算符比较判断的是对象间的唯一身份标识,也就是id是否相同
13、python里有哪些数据类型(可变、不可变)
可变对象:当有需要改变对象内部的值的时候,这个对象的id不发生变化。
不可变对象:当有需要改变对象内部的值的时候,这个对象的id会发生变化。
| 数据类型 | |
|---|---|
| 可变 | 字典(dict), 集合(set), 列表(list) |
| 不可变 | 整型(int), 字符串(string), 浮点型(float), 元组(tuple) |
14、赋值、深浅拷贝
导入模块:import copy
浅拷贝:copy.copy
深拷贝:copy.deepcopy
| 赋值 | 指向同一内存 |
| 浅拷贝 | 仅拷贝数据集合的第一层数据 |
| 深拷贝 | 指拷贝数据集合的所有层 |
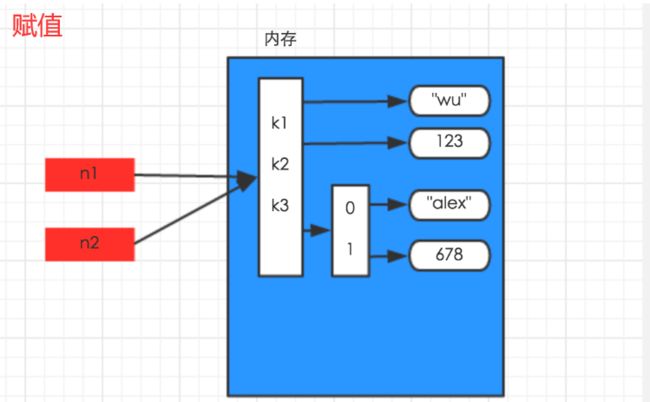

浅拷贝的时候,python仅仅将最外层的内容在内存中新建了一份出来,字典第二层的列表并没有在内存中新建,所以你修改了新模版,默认模版也被修改了。
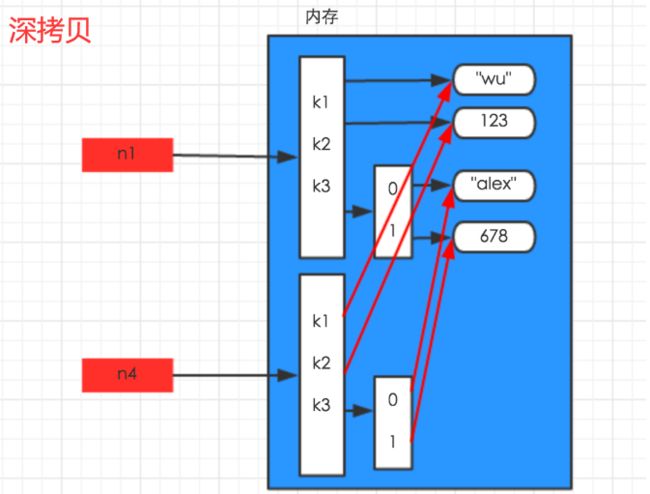
深拷贝的时候python将字典的所有数据在内存中新建了一份,所以如果你修改新的模版的时候老模版不会变。
15、python垃圾回收机制(cpython)
Python垃圾回收主要以引用计数为主,分代回收为辅。
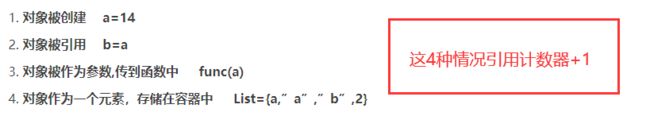

原始的引用计数法也有明显的缺点:

为了解决这两个致命弱点,Python又引入两种GC机制:
gc的逻辑:(重点)
分配内存
-> 发现超过阈值了
-> 触发垃圾回收
-> 将所有可收集对象链表放到一起
-> 遍历, 计算有效引用计数
-> 分成 有效引用计数=0 和 有效引用计数 > 0 两个集合
-> 大于0的, 放入到更老一代
-> =0的, 执行回收
-> 回收遍历容器内的各个元素, 减掉对应元素引用计数(破掉循环引用)
-> 执行-1的逻辑, 若发现对象引用计数=0, 触发内存回收
-> python底层内存管理机制回收内存
分代回收:Python将内存分为了3“代”,分别为年轻代(0代)、中年代(1代)、老年代(2代),对应的是3个链表,年轻代链表的总数达到上限时,垃圾收集机制被触发,把可以被回收的对象回收掉,把不会回收移到中年代去,依此类推,老年代中的对象是存活时间最久的对象。
16、列举常见内置函数
| 函数 | 作用 |
|---|---|
| abs(a) | 返回数字a的绝对值 |
| all([0, 1,2]) | 判断给定的可迭代参数 iterable 中的所有元素是否都不为 0,没0返回True |
| any( [ ] ) | 判断给定的可迭代参数 iterable 是否全部为空对象,全0或空返回False |
| bin(10) | int变2进制 |
| bool() | 判断为True或false |
type()、id()、int()、str()、long()。。。。
17、列举常用模块
os模块,路径
re模块,正则表达式
sys模块,标准输入输出
math模块,数学公式
json模块,字符串与其他数据类型转换;pickle模块,序列化
random模块,生成随机数
time模块,时间模块
datatime模块,datetime 基于 time 进行了封装
request模型,HTTP请求库
lxml, 处理XML和HTML文件
18、生成器、迭代器、可迭代对象
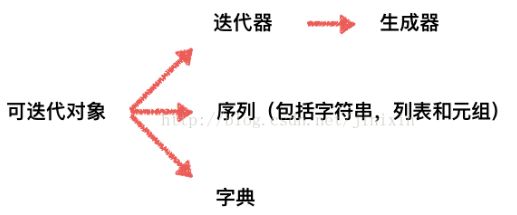
可迭代对象:
- 可迭代对象和容器一样是一种通俗的叫法,并不是指某种具体的数据类型
- 列表、元组、字典、set等都是可迭代对象,也可以自定义一个可迭代对象(类)
- 可迭代对象实现了__iter__方法,该方法返回一个迭代器对象。
迭代器:
- 用iter() 函数来生成迭代器。例:iter([1,2,3])。
- 任何实现了__iter__和__next__()(python2中实现next())方法的对象都是迭代器,__iter__返回迭代器自身,__next__返回容器中的下一个值,如果容器中没有更多元素了,则抛出StopIteration异常
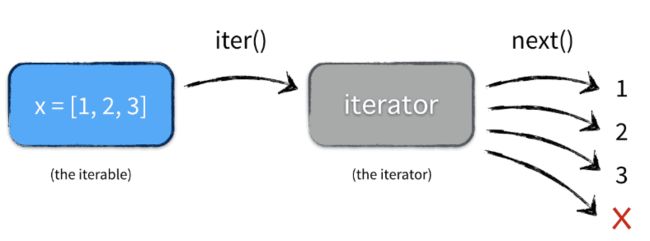
生成器:
- 生成器是一种特殊的迭代器。
- 它不需要再像上面的类一样写__iter__()和__next__()方法了,只需要一个yiled关键字。
yield就是return返回的一个值,并且记住这个返回的位置.下一次迭代就从整个位置开始
例:
# 一个普通的函数
def something():
result = []
for ... in ...:
result.append(x)
return result
# 生成器
def iter_something():
for ... in ...:
yield x
例:
# 用生成器来实现斐波那契数列
def fib():
prev, curr = 0, 1
while True:
yield curr
prev, curr = curr, curr + prev
>>> f = fib()
>>> list(islice(f, 0, 10))
[1, 1, 2, 3, 5, 8, 13, 21, 34, 55]
生成器表达式例:
a = (x*x for x in range(10))
# 返回生成器对象
列表推导式例:
b = [x*x for x in range(10)]
# 返回列表对象
参考源:https://foofish.net/iterators-vs-generators.html
19、re的match和search区别
match()函数只检测RE是不是在string的开始位置匹配,search()会扫描整个string查找匹配
20、什么是正则的贪婪匹配
贪婪匹配:正则表达式一般趋向于最大长度匹配。
非贪婪匹配:匹配到结果就好。
默认是贪婪模式。在量词后面直接加一个问号?就是非贪婪模式。
