GSEA是一种无阈值方法,可根据其差异表达等级或其他分数对所有基因进行分析,无需事先进行基因过滤。当基因组中的所有或大多数基因(例如,RNA-seq数据)可获得rank时推荐使用GSEA进行通路富集分析, 然而,当仅有一小部分基因具有rank可用时,如,在确定显着突变的癌症基因的实验中,GSEA并不合适。GESA使用基于一个置换矩阵检验来分析rank gene list。GSEA搜索基因在rank gene list的顶部或底部富集通路,这比单凭偶然的机会所能预料到的还要多。 例如,如果最顶端的差异表达基因参与细胞周期,这表明细胞周期通路在实验中受到调控。相反,如果细胞周期基因在整个rank gene list中随机分散,则细胞周期途径可能不会受到显着调节。要计算通路的富集分数(ES),GSEA逐步从顶部到底部检测rank list的基因,如果基因是该通路的一部分则增加ES,否则降低分数。这些运行总和值是加权的,因此放大了top(和bottom)排序基因的富集,而中等水平基因的富集则没有被放大。ES分数被计算为运行总和的最大值并相对于通路大小进行归一化,从而得到标准化的富集分数(NES),其反映了列表中通路的富集。正NES值和负NES值分别表示列表顶部和底部的富集。最后一个基于置换的p值被计算,并用多次测试进行矫正以产生基于置换的错误发现率Q值,Q值的范围从0(非常显著)到1(不显著)。从排序基因列表的底部开始进行相同的分析,以鉴定在列表底部富集的通路。使用FDR Q值阈值(例如,Q <0.05)选择所得到的通路并使用NES进行rank。 此外,GSEA分析的“leading edge”方面确定了对检测到的通路富集信号最有贡献的特定基因。
GSEA有两种确定ES的统计学显着性(P值)的方法:基因集置换和表型置换。 基因集置换测试需要rank list,并且GSEA将观察到的通路的ES与通过用随机取样的匹配大小的基因集(例如,1,000次)重复分析而获得的分数分布进行比较。表型置换测试需要所有样品的表达数据(例如,生物学重复),以及被称为“表型”的样品组,该方法是彼此之间比较(例如,病例与对照;肿瘤与正常样品)。对于具有有限突变和生物学重复的研究(即每种条件2至5次),推荐使用基因集置换。在这种情况下,差异基因表达值应在GSEA之外计算,使用包括方差稳定性的方法(例如edgeR ,DESeq 和limma / voom ),并在通路分析之前导入GSEA软件,表型置换应该与使用更多次重复(例如,每种条件至少10次)。表型置换方法的主要优点在于与基因集置换方法相比,它在排列过程中保持了具有重要生物学意义的相关性基因的基因组结构。
input data :数据是被TCGA鉴定的两种卵巢癌两种亚型差异表达的gene list。该rank先前基于基因表达数据分层为四种分子亚型,定义为分化,免疫反应,间充质和增殖。GSEA需要具有基因分数的RNK文件,该rnk文件有两列,第一列是基因ID,第二列是基因分数。基因组中的所有(或大多数)基因需要具有分数,并且基因ID需要与GMT文件中使用的基因ID匹配。
Load Data:将需要分析的数据加载进来,同时也将进行通路分析的基因集(GMT)加载进来。
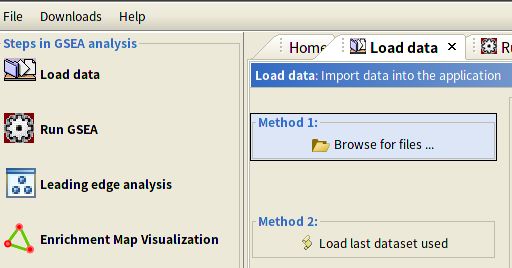
在下图的这个地方就可以看到你加载进来的数据
点击左边工具栏的Run GSEAPreranked
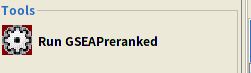
GSEA自己也提供了基因集文件,可以直接通过MSigDB资源从GSEA端口直接访问,不需要输入GSEA中。要定义GMT文件,可以在Select one or more genesets dialog对话框的第一个选项卡Gene Matrix(from website)中找到MSigDB基因集文件。如下图,而我自己提供了GMT文件,就选择Gene matrix (local gmx/gmt)选项卡,这下面有你在Load data的时候加载进来的GMT文件。
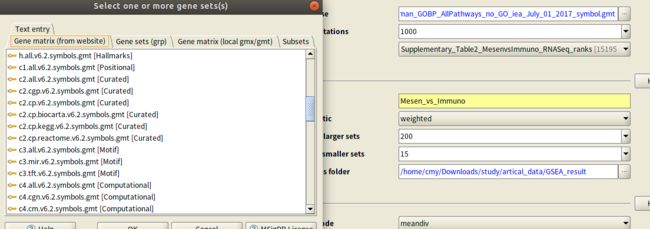
Number of permutations: 这指定了基因集随机化以创建空分布以计算P值和FDR Q值的次数。 使用默认值1,000个排列。
更多的置换次数需要更长的计算时间。 为了计算每个gene set的FDR Q值,通过置换每个基因组中的基因并重新计算随机组的P值来随机化数据集,此参数指定完成此随机化的次数。执行的随机化越多,FDR Q值估计就越精确(达到极限,因为最终FDR Q值将稳定在实际值)。
rank list: 单击最右侧的箭头并突出显示排名文件,选择排序的基因列表。
单击Basic fields 的Show可以展示出其他选项:
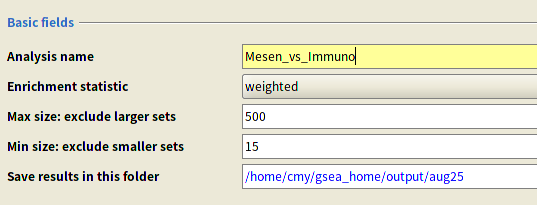
Analysis name: 默认是‘my_analysis',也可以修改为自己想要的。
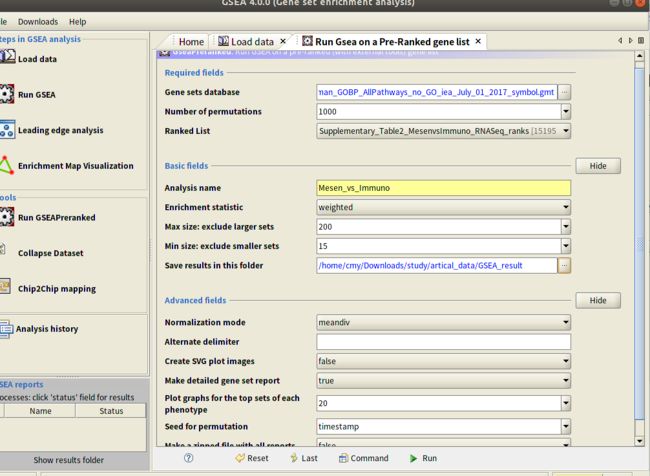
Max size: exclude larger sets:默认情况下,GSEA将上限设置为500,将此值设置为200以从分析中删除较大的集合。
Save results in this folder:默认的结果保存路径是:/home/cmy/gsea_home/output/aug25,也就是会默认保存在你的home目录下。可将其改为自定义的路径

除了上面Basic fields 外,下面还有一个Advanced fields,点击右边的show就可以展示出来,在这里可以进行一些高级的设置。在高级设置里面我没有修改,都是GSEA默认的。
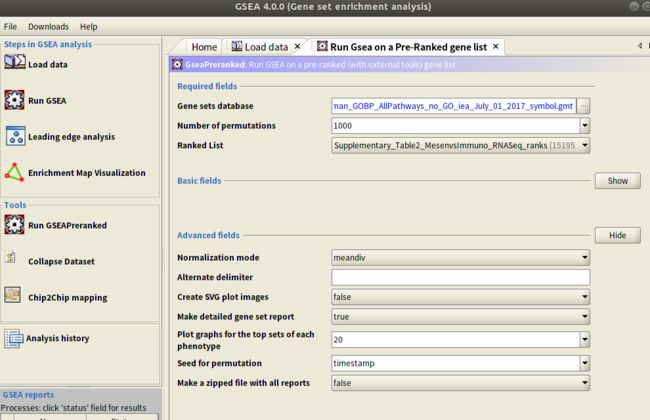
设置结束之后点击下面"run”箭头按钮:
在run的过程中你会看到下图这个最右边的数字会变化,而且左下角的GSEA report 中Status 会变成running. run的时间长短和速度的快慢取决于你的电脑配置。
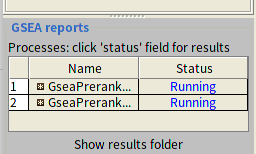
运行结束之后GSEA report 中Status会从running 状态变成success,点击Success就可以以网页的形式查看你的结果,根据上调还是下调会展示为两组。结果文件会保存在Save results in this folder设置的文件夹中。
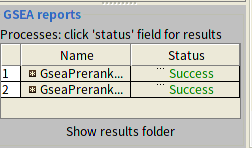
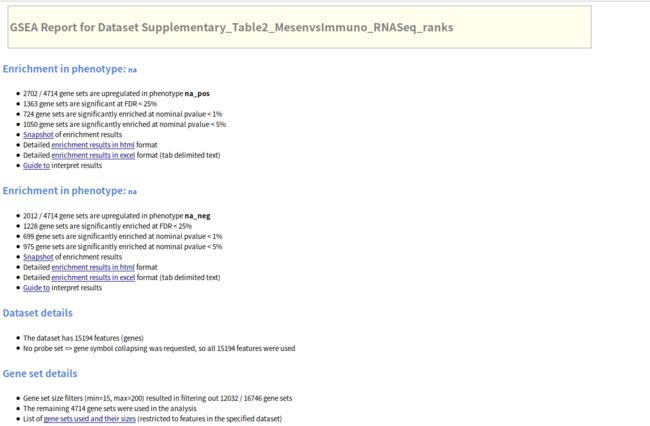
GSEA分析的结果通路富集排列在top的genes为上调的基因, na_pos(na表示'not available',因为我没有将表型标签的cle格式的文件输入,因此默认为na,而pos表示positive,neg:表示下调(negtive))

对于上图的结果解释可见下图:

点击enrichment results in html,可以在网页查看高表达基因集的富集的结果,如下图:

GS:基因集的名字,SIZE:基因集下的基因总数,ES:Enrichment score, NES:归一化后的Enrichment score, NOM p-val:p-value,表征富集结果的可信度,FDR q-val:q-value, 是多重假设检验矫正后的p值,注意GSEA采用pvalue < 5%, qvalue < 25% 对结果进行过滤。
点击GS DESC可以跳转到每个基因集详细结果页面,如下所示:
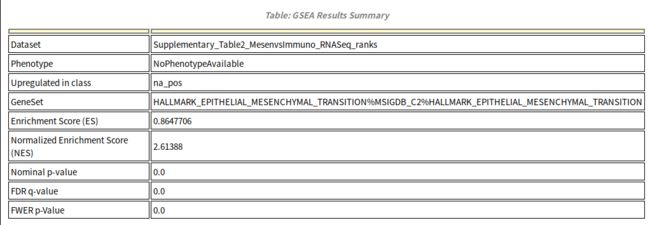
首先是一个汇总的结果,Upregulated in class说明该基因集在na-pos这组中高表达,其他的信息和上一副图中的表描述的一样,除此之外,还有详细的表格,如下所示:
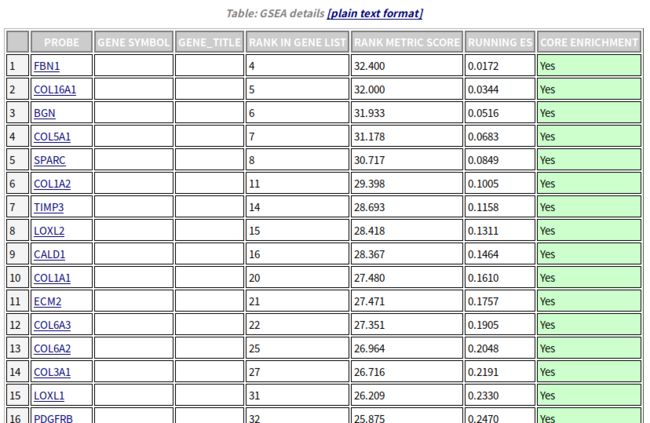
上表对于该基因集下的每个基因给出了详细的统计信息,RANK IN GENE LIST代表该基因在排序号的列表中的位置, RANK METRIC SCORE代表该基因排序量的值,比如foldchange值,RUNNIG ES代表累计的Enrichment score, CORE ENRICHMENT代表是否属于核心基因,即对该基因集的Enerchment score做出了主要贡献的基因。
该表格的基因集对应下面这张图:
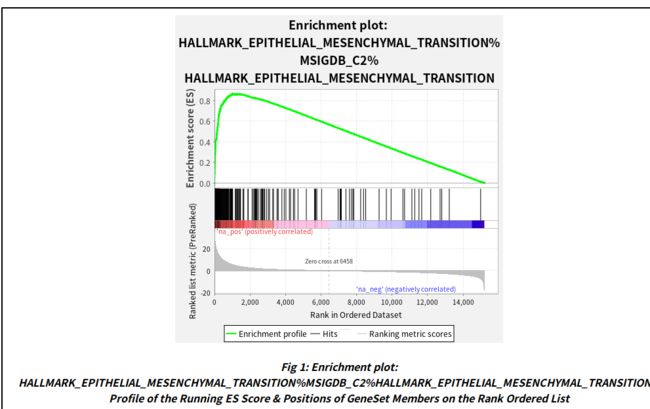
该图分为3个部分:
第一部分为基因Enrichment Score的折线图,横轴为该基因集下的每个基因,纵轴为对应的Running ES, 在折线图中有个峰值,该峰值就是这个基因集的Enrichemnt score,峰值之前的基因就是该基因集下的核心基因,即对该基因集的Enerchment score做出了主要贡献的基因。
第二部分为hit,用黑色线条标记位于该基因集下的基因
第三部分为所有基因的rank值分布图
从上图可以看到,其Enrichment score值全部为正数,对应的在其峰值左侧的基因为该基因集下的核心基因。
在总的html页面中,还给出了如下信息:
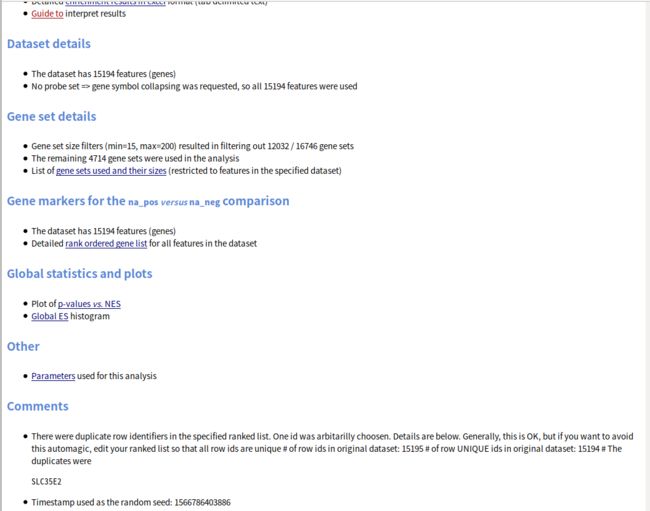
Dataset details给出了基因总数,Gene Set details给出了基因集的信息,默认根据基因集包含的基因个数是先对基因集进行过滤,最小15个,最大500个基因,(由于我自己设置了最大为200个),所以这里过滤掉了12032个基因集,剩余的 4714 个基因集用于分析。
学习与参考:
1.https://blog.csdn.net/weixin_43569478/article/details/83745105
2.NCBI - WWW Error Blocked Diagnostic
3.Reimand J, Isserlin R, Voisin V, et al. Pathway enrichment analysis and visualization of omics data using g:Profiler, GSEA, Cytoscape and
EnrichmentMap[J]. Nature Protocols, 2019, 14(2): 482-517.