PLSA主题模型
摘自这里
PLSA的通俗理解:
想象某个人要写N篇文档,他需要确定每篇文档里每个位置上的词。假定他一共有K个可选的主题,有V个可选的词项,所以,他制作了K个V面的 “主题-词项” 骰子,每个骰子对应一个主题,骰子每一面对应要选择的词项。然后,每写一篇文档会再制作一颗K面的 ”文档-主题“ 骰子;每写一个词,先扔该骰子选择主题;得到主题的结果后,使用和主题结果对应的那颗”主题-词项“骰子,扔该骰子选择要写的词。他不停的重复如上两个扔骰子步骤,最终完成了这篇文档。重复该方法N次,则写完所有的文档。在这个过程中,我们并未关注词和词之间的出现顺序,所以pLSA也是一种词袋方法;并且我们使用两层概率分布对整个样本空间建模,所以pLSA也是一种混合模型。
具体来说,该模型假设一组共现(co-occurrence)词项关联着一个隐含的主题类别 zk∈{z1,…,zK} 。有如下三个相关的概率: P(di) 表示词在文档 di 中出现的概率, P(wj|zk) 表示某个词 wj 在给定主题 zk 下出现的概率, P(zk|di) 表示某个主题 zk 在给定文档 di 下出现的概率。利用这三个概率,我们可以按照如下方式得到“词-文档”的生成模型:(三步刚好是上文对PLSA的理解)
- 按照概率
P(di)选择一篇文档di - 按照概率
P(zk|di)选择一个隐含的主题类别zk - 按照概率
P(wj|zk)生成一个词wj
这样可以得到文档中每个词的生成概率。把这个过程用数学方法表示:
P(di,wj)=P(di)P(wj|di)=P(di)∑k=1KP(wj|zk)P(zk|di)
用概率图表示如下:
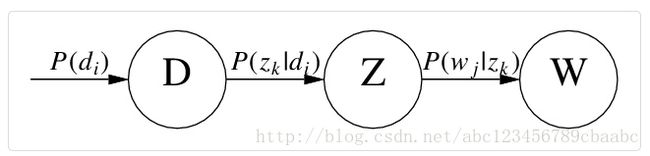
Hofmann的原始论文里使用概率符号 P(wj|zk) 和 P(zk|di) ,我们也可以从矩阵的角度来描述这两个变量:
假设用 ϕk 表示词表 V 在主题 zk 上的一个多项分布,则 ϕk 可以表示成一个向量,每个元素 ϕk,j 表示词项 wj 出现在主题 zk 中的概率,即
P(wj|zk)=ϕk,j,∑wj∈Vϕk,j=1
同样,假设用 θi 表示所有主题 Z 在文档 di 上的一个多项分布,则 θi 可以表示成一个向量,每个元素 θi,k 表示主题 zk 出现在文档 di 中的概率,即
P(zk|di)=θi,k,∑zk∈Zθi,k=1
最终我们要求解的参数是这两个矩阵:
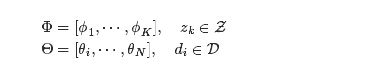
由于词和词之间是互相独立的,于是可以得到整篇文档的词的分布;并且文档和文档也是互相独立的,于是我们可以得到整个样本的词的分布:
P(W|di)P(W|D)=∏j=1MP(di,wj)n(di,wj)=∏i=1N∏j=1MP(di,wj)n(di,wj)
其中, n(di,wj) 表示词项 wj 在文档 di 中的词频, n(di) 表示文档 di 中词的总数,显然有 n(di)=∑wj∈Vn(di,wj) 。
于是,可以很容易写出样本分布的对数似然函数:
ℓ(Φ,Θ)=∑i=1N∑j=1Mn(di,wj)logP(di,wj)=∑i=1Nn(di)⎛⎝logP(di)+∑j=1Mn(di,wj)n(di)log∑k=1KP(wj|zk)P(zk|di)⎞⎠=∑i=1Nn(di)⎛⎝logP(di)+∑j=1Mn(di,wj)n(di)log∑k=1Kϕk,jθi,k⎞⎠
我们需要最大化对数似然函数来求解参数,对于这种含有隐变量的最大似然估计,我们还是需要使用EM方法。
E-step: 假定参数已知,计算此时隐变量的后验概率。
利用贝叶斯法则,可以得到:
P(zk|di,wj)=P(zk,di,wj)∑Kl=1P(zl,di,wj)=P(wj|di,zk)P(zk|di)P(di)∑Kl=1(P(wj|di,zl)P(zl|di)P(di))=P(wj|zk)P(zk|di)∑Kl=1P(wj|zl)P(zl|di)=ϕk,jθi,k∑Kl=1ϕl,jθi,l
这需要一点贝叶斯网络和概率图模型的知识,具体可以参考PRML第八章。
M-step:带入隐变量的后验概率,最大化样本分布的对数似然函数,求解相应的参数。
观察上面的对数似然函数 ℓ ,由于 P(di)∝n(di) 也就是文档长度可以单独从样本计算,可以去掉不影响最大化似然函数;此外,根据E-step的计算结果,把 ϕk,jθi,k=P(zk|di,wj)∑Kl=1ϕl,jθi,l 代入 ℓ ,于是我们最大化下面这个函数即可:
ℓ=∑i=1N∑j=1Mn(di,wj)∑k=1KP(zk|di,wj)log[ϕk,jθi,k]
这是一个多元函数求极值问题,并且已知有如下约束条件:
∑j=1Mϕk,j=1∑k=1Kθi,k=1
一般处理这种带有约束条件的极值问题,我们常用的方法是拉格朗日乘数法,引入拉格朗日乘子把约束条件和多元函数结合在一起,转化为无条件极值问题。这里我们引入两个乘子 τ 和 ρ ,可以写出拉格朗日函数,如下:
H=Lc+∑k=1Kτk⎛⎝1−∑j=1Mϕk,j⎞⎠+∑i=1Nρi(1−∑k=1Kθi,k)
需要求解 ϕk,j 和 θi,k ,分别求偏导,取0,可得如下等式:
∑i=1Nn(di,wj)P(zk|di,wj)−τkϕk,j=0,1≤j≤M,1≤k≤K∑j=1Mn(di,wj)P(zk|di,wj)−ρiθi,k=0,1≤i≤N,1≤k≤K
消去拉格朗日乘子,最终可估计出参数:
