广告行业中那些趣事系列11:推荐系统领域必学的Graph Embedding

摘要:推荐系统领域最近大火的Graph Embedding可以很好的解决传统的Sequence Embedding无法解决现实世界中诸如社交关系等图结构的问题。本文重点讲解了Graph Embedding中具有代表性的DeepWalk、LINE、SDNE、Node2Vec和阿里的EGES等模型,希望对Graph Embedding感兴趣的小伙伴有所帮助。
目录
01 为什么要学习Graph Embedding
02 对应到我们的业务场景
03 从DeepWalk到EGES的GraphEmbedding成长史
1. 打开Graph Embedding大门的DeepWalk
2. 微软的LINE
3. 第一个将深度学习模型引入图表示的SDNE
4. 斯坦福大学的Node2vec
5. Graph Embedding的最佳实践阿里的EGES
01 为什么要学习Graph Embedding
自从谷歌的Word2Vec引爆Embedding技术潮流,就有“万物皆可Embedding”之说。传统的Embedding比如Word2Vec通过句子等序列式的样本来学习文本的表征形式。而参考Word2Vec思想而生的Item2Vec则通过商品组合这种序列式去生成商品的Embedding。这种传统的Embedding称为“Sequence Embedding”。
现实世界中类似社交关系、搜索和购买行为、蛋白体结构、交通网络数据以及最近很火的知识图谱等都是一种图的表示关系,传统的基于序列的Embedding则显得无能为力。所以从2014年开始一些业内学者开始研究使用Embedding来表征图结构,这就是Graph Embedding技术的由来。
Graph Embedding的中心思想是找到一种映射函数将网络中的每个节点转换为低维度的潜在表示,也就是使用低维、稠密的向量来表示网络中的节点。Graph Embedding的一个输入和输出如下图所示:

图1 Graph Embedding的输入和输出表示
上图中我们输入的是一个图结构,输出则是将图中各个节点映射到二维空间的Embedding,通过计算节点间Embedding的距离长短可以获取物品之间的相似度关系。目前Graph Embedding技术已经应用于推荐系统、计算广告领域等,并且在实践后取得了不错的线上效果,所以值得我们学习。
02 对应到我们的业务场景
了解了Graph Embedding技术的由来,秉持着“技术最终的归宿都是服务于业务以及不落地的算法都是耍流氓”的业务为王的精神,我们来看看可以用Graph Embedding技术做什么。使用阿里论文中的一张用户购买商品行为序列的例子来说明:
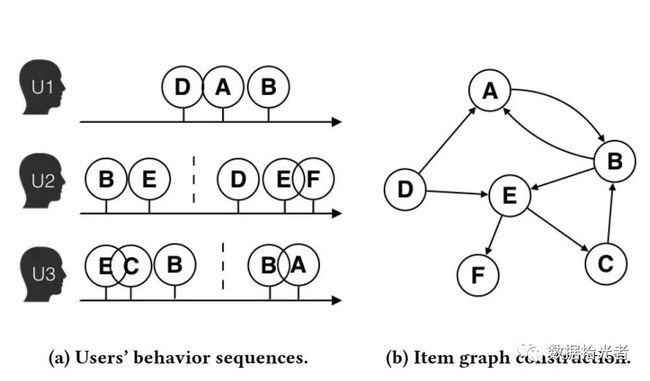
图2 用户购买商品序列生成商品关系结构图
上图中左边是用户购买商品的顺序图,比如用户1先后购买了D、A、B三种商品。通过用户购买商品的顺序序列我们可以得到右边的商品关系有向图,可以看到一共有A到F六种商品。通过构建商品的图结构,使用Graph Embedding的方式更好的表征商品,我们可以更好的理解商品之间的关联,最终实现商品推荐的目的。
知乎使用Graph Embedding技术来构建用户Embedding的实践以及在知乎收藏夹数据中的应用。下图是可视化的方式表示知乎用户关系图:

图3 知乎用户关系图
说完别人的,再看看我们实际业务场景中可以用Graph Embedding技术做什么。之前说过我们标签组主要是给用户打上兴趣标签,其中很重要的一块是就是item打标,其实就是实现数据源分类。已知的是其他团队通过构建用户启动app顺序的图关系实现app的Embedding表征,从而实现app推荐及分类任务。不仅如此,还有其他大厂通过Graph Embedding技术应用于信息流推荐场景。
03 从DeepWalk到EGES的GraphEmbedding成长史
总的来说,Graph Embedding主要包含以下不同的分类以及对应的算法模型。GraphEmbedding算法全家桶如下图所示:
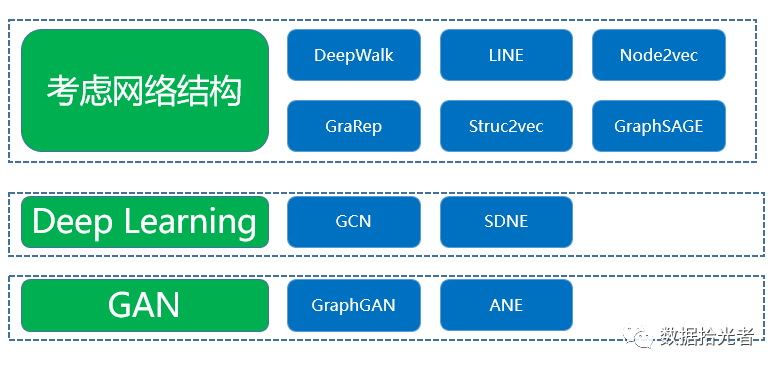 图4 Graph Embedding算法全家桶
图4 Graph Embedding算法全家桶
从2014年至今,Graph Embedding技术飞速发展。下面选出其中具有代表性的模型进行详细分析:
1. 打开Graph Embedding大门的DeepWalk
可以说2014年提出的DeepWalk算法是打开Graph Embedding大门的先行者。DeepWalk算法的主要思想是在物品组成的图结构上随机游走生成大量的物品序列,然后把这些序列作为训练样本放到Word2Vec中进行训练,最终得到物品Embedding。总体来说是一种将图结构转换成序列,然后底层使用Word2Vec这种Sequence Embedding的方式。

图5 DeepWalk算法的四个步骤
DeepWalk算法整个流程如上图所示分成四个主要的步骤:
图a是用户购买商品的行为序列关系。比如用户1购买了D、A、B三种商品。这里需要说明的是存在一个时间域的概念,就是用户在一段时间内购买商品的顺序关系,比如用户2购买完B、E之后经过了一段时间接着买D、E、F,这里将时间分成了两个域,分别是BE和DEF
根据图a用户购买商品的行为序列关系得到图b这样的有向有权图
图c是使用随机游走的方式随机选择起始点重新生成物品序列
图d是把重新生成的物品序列作为训练样本放到Word2Vec中的Skip-Gram模型中去训练得到物品的Embedding向量
整个流程最重要的是第三步的使用随机游走的方式生成物品序列,下面进行详细说明。这里需要定义随机游走的跳转概率,也就是到达节点v_i后下一步遍历邻接节点v_j的概率。如果物品关系是一个有向有权图,那么节点v_i跳转到v_j的概率定义如下:
 图6 节点v_i跳转到节点v_j的概率定义图
图6 节点v_i跳转到节点v_j的概率定义图
其中N+(v_i)是所有和v_i邻接的出边的集合,这里需要强调下出边,因为是有向图。如果是无向图则代表所有和v_i相邻的边的集合。M_ij是节点v_i到v_j边的权重。从公式中可以看出这个所谓的随机游走算法会倾向于向权重更大的节点靠近。
2. 微软的LINE
2014年DeepWalk打开Graph embedding的大门之后,2015年微软紧跟其后提出了LINE(Large-scale InformationNetwork Embedding)模型。LINE的核心思想是通过一阶相似度(First-order proximity)和二阶相似度(Second-orderproximity)明确定义了如何表征图中节点的相似度。通过下图说明一阶相似度和二阶相似度:

图7 LINE模型的一阶相似度和二阶相似度说明图
其中一阶相似度是用于描述图中节点之间的局部相似度,对应图中形式化的描述就是节点之间存在直接相连的边,比如上图中的节点6和7之间存在直接相连的边,所以1阶相似度较高;仅有一阶相似度还远远不够,比如节点5和6,虽然没有直接相连,但是因为有大量重合的边1-4,所以认为节点5和6也是相似的,二阶相似度则是用于描述这种关系。论文中还做了以下三点优化:首先一阶相似度和二阶相似度可以分开进行训练,可以根据实际的应用场景进行拼接使用;然后,使用边采样EdgeSample解决了因为权重范围过大导致学习率难以控制的问题;最后,考虑冷启动的问题,当一个节点边较少时通过2阶邻居也就是它的3阶点去处理二阶相似度。
相比于DeepWalk纯粹随机游走的序列生成方式,LINE可以应用于有向图、无向图以及有有向有权图,并通过将一阶和二阶的邻近关系引入目标函数,让节点最终学到的Embedding分布更为均衡平滑,避免了DeepWalk容易使node Embedding聚集的情况。
3. 第一个将深度学习模型引入图表示的SDNE
2016年清华国家实验室在KDD会议发表的论文提出了SDNE(Structural Deep NetworkEmbedding)模型。论文认为DeepWalk算法的缺点是缺乏明确的优化目标,虽然LINE模型通过一阶相似度和二阶相似度分别学习网络的局部信息和全局信息,但是通过简单的拼接两个向量并不是最优的方法。针对这个问题,SDNE模型基于LINE进行扩展,将深度学习引入Graph Embedding,使得模型具有更强的非线性表达能力。模型中还设计了一个同时扫描局部和全局网络信息的目标函数,利用半监督的方式去拟合模型。
SDNE模型将图的网络结构信息分成local和global,对应LINE模型中的一阶相似度和二阶相似度。SDNE模型使用非监督的AutoEncoder去计算二阶相似度,还原节点的上下文信息;同时使用监督的方式去计算一阶相似度,对应的监督样本是直接相连的节点。SDNE模型的网络结构如下图所示:
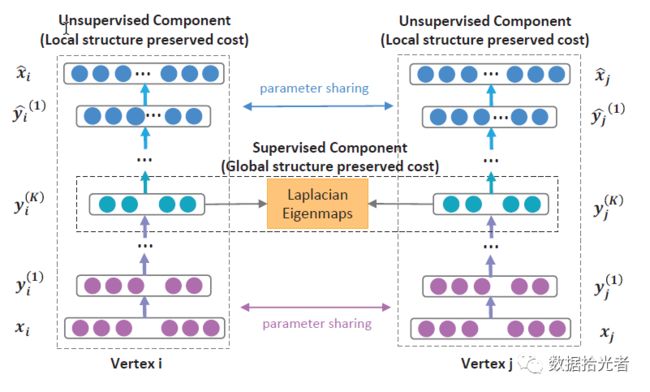
图8 SDNE模型网络结构图
上图中左边是一个自动编码器结构,输入是邻接矩阵,输出则是重构后的邻接矩阵。通过优化重构后邻接矩阵的损失函数可以保留节点的全局结构特性。图中绿色的y_i就是我们需要的Embedding向量,模型通过一阶损失函数拉近相邻接节点的Embedding向量距离,从而保留节点的局部结构特性。注意论文图中的Global和Local画反了。
4. 斯坦福大学的Node2vec
2016年斯坦福大学进一步改进DeepWalk算法并提出了Node2vec模型,模型的核心思想是使用深度优先搜索(Deepth-First Search)和广度优先搜索(Breadth-FirstSearch)替代随机游走权重,使得Graph Embedding的结果在同质性和结构性中进行权衡。通过下图说明DFS和BFS的区别:

图9 深度优先搜索(DFS)和广度优先搜索(BFS)示意图
上图中红色箭头表示BFS搜索,节点u会更倾向于搜索和它直接相连的节点S1、S2、S3,BFS更注重获取网络的结构性特征。因为在Node2vec模型中存在所谓的“返回概率”,也就是说u搜索到了S1,同时也有很大的概率从S1返回到u,所以最终的结果是u在自己邻接的节点来回震荡,相当于对u周围的网络结构进行了一次微观扫描,也就是论文中说的microscope view。因为这个微观扫描更容易得到微观结构的观察,所以BFS搜索更容易使Embedding结果反映网络的结构性。这里的结构性是一阶、二阶范围内的微观结构。
这里通过一个例子说明使用BFS搜索导致图中不同位置(这里的不同位置是指节点在图中是位于中心还是边缘)节点的Embedding差别很大。对比上图中的节点u和节点S9,其中u是局部网络的中心点,而S9是一个边缘节点。当网络采用BFS搜索策略进行随机游走时节点u因为处于局部网络的中心所以会被多次遍历到,而且会和直接相连的节点S1-S4等节点发生联系。但是边缘位置的节点S9无论从遍历次数还是邻接点的丰富程度上都不如u,所以最终的结果是节点u和节点S9两者的Embedding差异会非常大,从而一定程度上达到了区分物品的目的。
同理,上图中蓝色箭头表示DFS搜索,节点u会更倾向于搜索更远的节点S4、S5、S6,DFS更注重获取网络的同质性特征。这里的同质性是指在相对较广的范围内能发现一个类似社区聚集的具有本质区别的性质。如果要发现这种性质,肯定要通过DFS深度优先搜索的策略进行更广范围内的搜索。所以说DFS是对整个图进行了一次宏观扫描,也就是论文中说的macroscope view。因为只有在宏观的视角下才能发现社区的聚集性和集团内部节点的同质性。
关于网络的结构性和同质性在知乎上看到一个热评感觉比较有意思,放上来和大家一起欣赏下:周游了世界(DFS深度优先搜索)才知道中国人和外国人之间的本质的区别即同质性;周游了中国(BFS宽度优先搜索)才知道中国人之间的结构性,个体之间细小的差异。
说完同质性和结构性,那么在Node2vec算法中具体如何控制BFS和DFS的倾向性呢?主要通过节点间的跳转概率。下图展示了Node2vec算法从节点t跳转到v之后,在v节点跳转到周围节点的跳转概率:
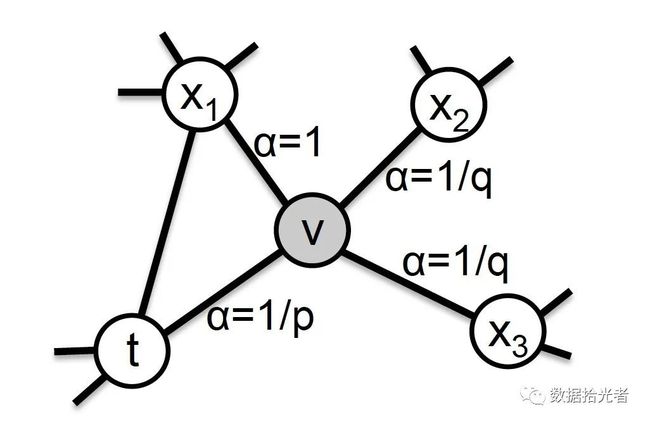
图10 Node2Vec模型如何控制BFS和DFS的倾向性
论文中表示从节点v跳转到x_i的概率公式为:
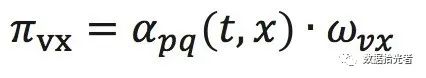
图11 Node2Vec节点跳转概率公式
其中w_vx是节点v到x的权重,a_pq(t,x)的定义如下所示:
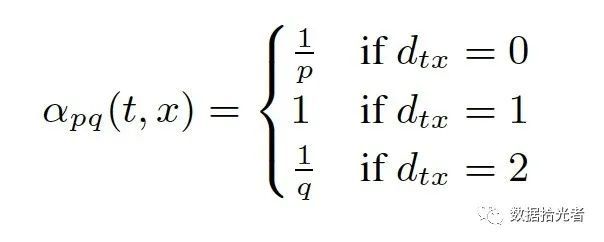 图12 Node2Vec倾向性参数p和q
图12 Node2Vec倾向性参数p和q
其中d_tx控制a_pq(t,x)的值,代表节点t和x_i的距离。这里的节点t是节点v跳转之前的节点。参数p称为返回参数(returnparameter),p越小,随机游走回节点t的可能性就更大,Node2vec就更加注重表达网络的结构性;参数q称为进出参数(in-out parameter),控制节点v去往节点X2、X3的概率。节点t和X2、X3的距离是2(t->v->X2/X3),所以q越小,随机游走到距离t节点更远的X2和X3的概率就越大,Node2vec就更加注重表达网络的同质性。节点X1是个比较特殊的存在,因为X1是节点t和节点v的公共邻居,和t的距离是1,所以设置为1。就这样通过设置p和q的权重我们可以控制随机游走的方式更倾向于DFS还是BFS。
下图是论文中证明Node2vec灵活表达同质性和结构性特点的节点可视化图。可以看出图中上部分通过BFS策略网络更加注重结构性,也就是节点相邻的点之间的Embedding比较相似,更注重微观结构microscope view;而图中下部分则通过DFS策略网络更加注重同质性,也就是中心或者边缘的节点之间的Embedding比较相似,更注重宏观结构macroscope view。
图13 Node2Vec模型结果可视化图
Node2vec这种网络的结构性和同质性在推荐系统中也是可以直观的解释的。结构性关注的节点是在系统中的相对位置,比如是在中心位置还是边缘位置,而不关心节点本身的特有的属性。这种类似每个品类的热门热销商品等容易有这样的特点。而同质性刚好相反,更多关注内容之间本身的相似性,比如同品类、同店铺、同价格区间等更容易表现同质性。对应于咱们实际业务中用于数据源打标场景,目的是对app进行区分,也就是数据源分类,更加注重的是app本身内容之间的相似性,所以使用同质性来进行区分可能更加合理。
实际业务场景中同质性和结构性这两种Embedding在推荐系统中都是非常重要的特征表达。正因为Node2vec具有很好的灵活性以及挖掘不同特征的能力,所以可以把不同Node2Vec生成的Embedding融合之后一起输入到后续的深度学习网络中,从而保留商品的不同特征信息。
5. Graph Embedding的最佳实践阿里的EGES
2018年阿里公布了在淘宝应用的Graph Embedding模型EGES(Enhanced GraphEmbedding with Side Information),模型核心思想是在DeepWalk生成的Graph Embedding的基础上加入了补充信息side information。
之前说过DeepWalk算法会将用户购买商品的序列关系转换成商品图结构。但是对于那些新上架的商品因为缺少用户购买行为序列,所以无法构建商品图结构,归根结底其实就是冷启动的问题。针对这个问题阿里提出了利用相同属性、相同类别等相似性信息构建商品之间的边,从而生成基于内容的Knowledge Graph。
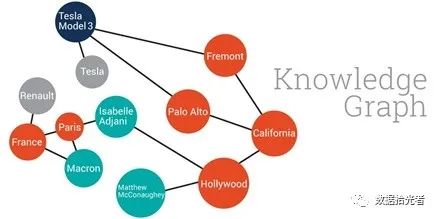
图14 Knowledge Graph表示图
通过这种Knowledge Graph生成的基于物品内容信息的向量可以称为补充信息(sideinformation)的Embedding 向量。多个不同的补充信息就会对应多个不同的side information Embedding向量。现在又面临新的问题,如何融合多个补充信息的Embedding向量从而形成物品最终的Embedding向量呢?阿里提出了在深度神经网络中加入average pooling层将不同的Embedding平均,并在每个Embedding加上了权重。如下图所示,对不同补充信息的Embedding向量分别赋予不同的权重a_0到a_n。
图中的隐藏表示层(HiddenRepresentation)就是对不同Embedding进行加权平均操作的神经网络层,将加权平均后的Embedding向量直接输入Softmax层,通过梯度下降的反向传播算法就可以得到每个Embedding向量的权重a_i。这里需要注意的是EGES模型采用了e^a_i来表示对应Embedding的权重a_i,目的是既可以避免权重为0,又可以在梯度下降的过程中使用e^a_i良好的数学性质。

图15 阿里的EGES模型的流程图
下图是论文中展示通过EGES模型实现冷启动商品的推荐效果图:

图16 EGES模型冷启动效果图
下图是论文中将EGES模型得到的商品的Embedding通过PCA降维能达到很好的聚类效果图:
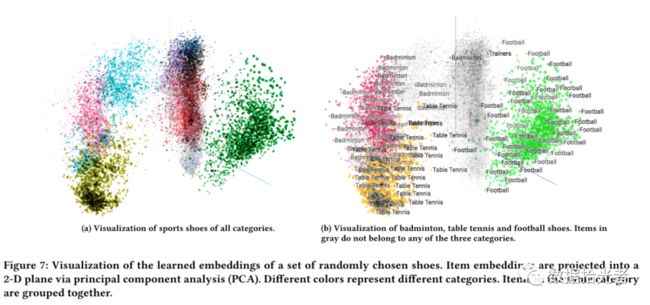
图17 EGES模型输出Embedding用于聚类
总体来说阿里的EGES模型虽然没有复杂的理论创新,但是给出了一个结合多种Embedding的实用性极强的工程性的方法average pooling。通过这种方法可以有效解决因为部分Embedding缺失导致的冷启动问题,所以非常有借鉴价值。
总结
本篇首先讲了下由于传统的Sequence Embedding无法解决现实世界中诸如社交关系等图结构的问题,所以业内开始研究Graph embedding技术;然后讲了下阿里和知乎使用Graph Embedding技术应用于实际业务,同时我们也可以使用该技术来解决数据源分类和信息流场景下的广告推荐问题;最后分别讲了DeepWalk、LINE、SDNE、Node2Vec和阿里的EGES等具有代表性的Graph Embedding模型,为我们后面使用Graph Embedding技术打下了坚实的理论基础。
参考资料
[1] [DeepWalk] DeepWalk- Online Learning of SocialRepresentations (SBU 2014)
[2] [LINE] LINE - Large-scale Information NetworkEmbedding (MSRA 2015)
[3] [Node2vec] Node2vec - Scalable Feature Learningfor Networks (Stanford 2016) [4] [SDNE] Structural Deep Network Embedding (THU2016)
[5] [Alibaba Embedding] Billion-scale CommodityEmbedding for E-commerce Recommendation in Alibaba (Alibaba 2018)
最新最全的文章请关注我的微信公众号:数据拾光者。
