RDD运行原理
RDD产生的原因
在之前的机器学习里以及交互式挖掘等经常会涉及很多迭代式计算,这些迭代计算会涉及到一个中间结果计算的重用问题,MapReduce是把中间结果写入到磁盘里面,下次要使用的时候再从磁盘里读取中间结果,这样就会带来大量化的磁盘读写开销以及序列化与反序列化的开销。这里说的序列化是指将内存中的java对象进行转换为存储或传输的格式,比如说可以将java对象序列化为二进制对象或ssm文本格式,方便在网络上存储或传输。而将二进制或ssm文本还原成java对象,则称为反序列化。RDD就是为了避免这些问题而产生的。
RDD提供了抽象的数据结构,从而不用担心底层的分布式特性,而只需要经我们的逻辑表达为一个个转换处理(不论多复杂的逻辑都可以将其变为RDD转换),不同的转换关系就形成了rdd的转换的依赖关系,即为有向无环图DAG。

对于该依赖图我们可以进行优化处理,从而实现相应的管道处理,一个操作结束后,数据不需要进入磁盘,马上就可以进行下一个操作。

一个RDD就是一个分布式集合,其本质为一个只读(不能修改)的分区记录集合,一个RDD可以存储几十G或多少个T的数据,一个单机存不下,我们可以将其分布式的保存在很多台机器上,将RDD分成若干个分区,每个分区放在不同的机器上去,每个分区就是一个数据片段,把它分布在不同结点上面,数据分布在不同结点上,从而就可以使计算分布式并行。这就是其为什么可以加快速度,因为数据被分布式存储了,所以计算就可以在多台计算上并行的发生。
RDD提供了一种高度受限的共享内存模型,这里说的高度受限是因为RDD为只读,RDD一旦生成就不能对其发生变化。
RDD在转换当中是可以发生修改的,通过生成一个新的RDD来完成数据修改的目的。

RDD提供了两种类型的操作:动作类型操作(action)和转换类型操作(transformation),这两种操作都是粗粒度的转换操作,粗粒度转换意思是一次只能针对RDD全集进行转换(一个记录全集进行转换),而不支持对单挑进行修改。
虽然RDD为高度受限的内存模型,同时只能进行粗粒度转换,但是它却不影响功能操作。
Spark提供了RDD的的API,程序员可通过调用API实现对RDD的各种操作。
RDD的典型执行过程:


RDD的惰性机制,RDD的一系列转换操作并不会真正进行转换,其只记录的转换的意图,并不会真正发生计算,只有当遇到动作类型操作,它才会从头到尾执行计算。管道化是只每次转换过程中可以形成一个管道流,我们可直接将一个操作的输出呈给下一个操作,而不需要将中间结果进行存储处理。同时因为操作非常多,每一个操作就非常简单,将这些简单的操作串联起来就可以解决很多复杂的功能。
spark为什么能实现高效的计算呢?
第一,其有高效的容错性;
第二,中间结果持久化内存RDD.cache(),数据在内存的多个RDD之间进行传递操作,避免了不必要的磁盘读写开销
第三,避免了序列化及反序列化开销
RDD的依赖关系
一个RDD应用会分成多个作业关系,一个作业关系会分成多个阶段(为什么一个作业会分成多个阶段?)以什么依据将一个作业拆分为多个阶段?这里就涉及到宽依赖和窄依赖的问题,它决定是否拆分阶段的依据。
窄依赖不划分阶段,宽依赖划分成多个阶段。是否包含shuffle操作是区分宽依赖和窄依赖的依据。包含shuffle操作即为宽依赖,没有包含shuffle操作则称为窄依赖。
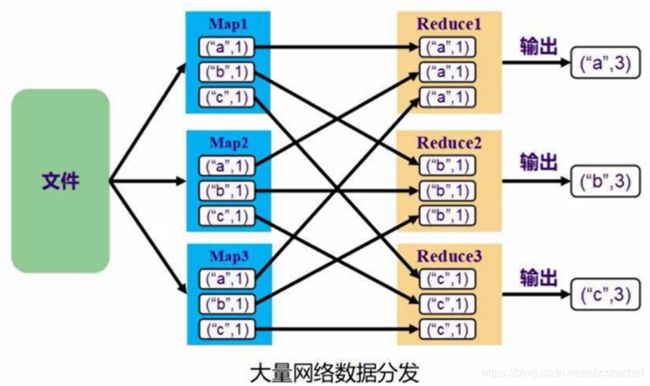
像上图这样交叉洗牌的操作就称为shuffle操作。shuffle操作就是发生了很多来回数据交叉的分发。
宽依赖和窄依赖的区分
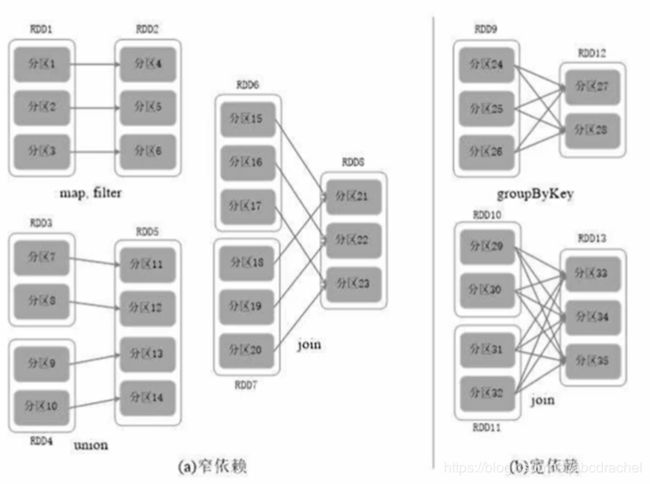
窄依赖特征:一个父RDD分区对应一个子RDD的分区或者多个父RDD分区对应一个子RDD的分区。
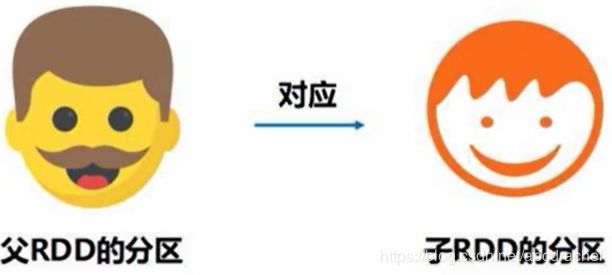

宽依赖特征:一个父RDD的一个分区对应多个子RDD的多个分区(即一个父亲对应多个儿子)
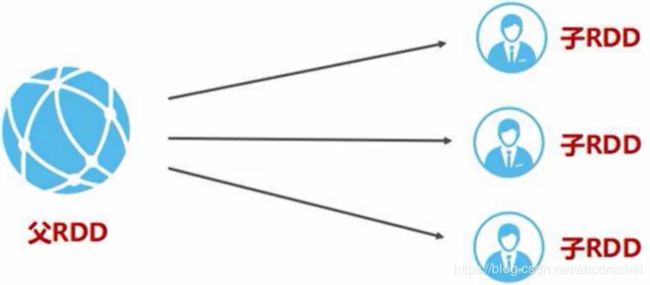
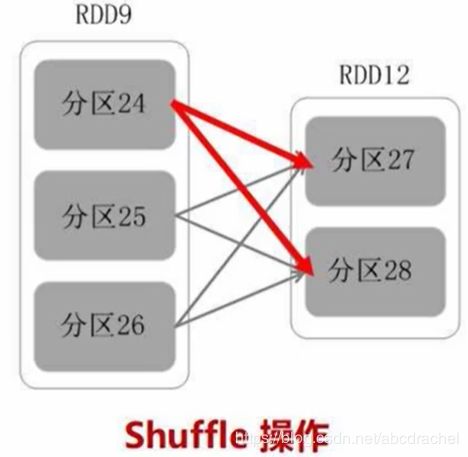
为什么宽依赖需要在shuffle操作处划分成多个阶段,而窄依赖就不要划分呢?
这是因为窄依赖可以进行流水线优化的,而宽依赖不能进行流水线优化。
spark优化机制
spark采用了fork/join机制,这是分布式典型的优化机制。

此处为RDD1转换为RDD2,但是在一个复杂的RDD应用中,可能会不断地转换。

一个单个的转换就是一次fork/join,多个不同转换串联起来就说多个不同的fork/join。每次RDD操作都是一次fork/join,多个RDD串联起来就是多个fork/join的组合。
多个fork/join组合怎么能够优化呢?
只要发生shuffle就会一定会写入磁盘。优化就是让数据中间不要落入磁盘中,直接在内存中就完成一个操作的输出到下一个操作的输入。一旦发生shuffle操作,一定是发生数据的交换(洗牌),这时候就需要写入磁盘,进行操作。

在该图中我们可以省去上海的join,从而达到优化的目的,最后飞行时长为5小时。
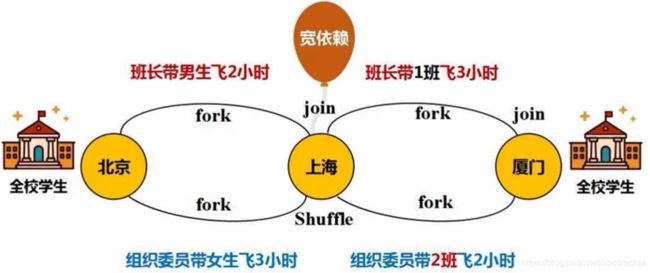
上图中因为上海到厦门的人员分配有变动,即shuffle,不能取消上海的join,因此不能进行优化。
RDD运行过程

RDD的运行过程:首先提交所写的rdd代码给spark框架,spark框架会根据提供的代码生成一个有向无环图,即DAG图,DAG图会提交给DAGScheduler,DAGScheduler会将其分成多个阶段,每个阶段包含若干个任务,每个任务会被分配给TaskScheduler,TaskScheduler会把任务分配给工作节点上的Excutor进程,然后由Excutor进程派发出来的线程去执行任务,这样就完成了一个工作,即为RDD的整个执行过程。