RDD的处理方法(创建、转换、行动、分区)
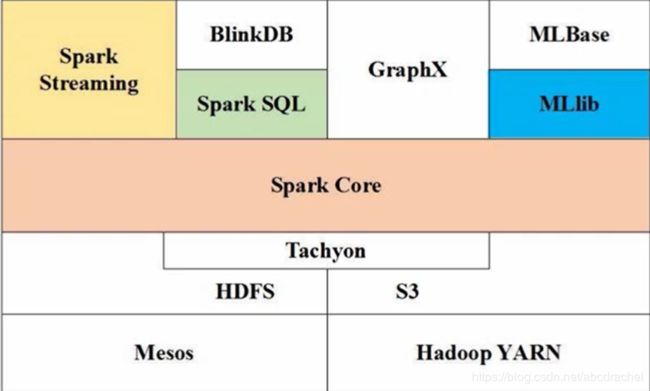
spark生态系统:底层是spark core,在spark core的基础上开发了其他组件,可以支持不同的应用场景。spark sql支持sql 查询,spark streaming可以支持流计算,spark mLlib支持机器学习等。
rdd编程是指spark core(底层)的编程。为什么叫rdd编程?因为整个过程就是对rdd的一次又一次的转换。
rdd编程基础
1、rdd创建方法
现有两种方法创建rdd:通过文件系统中加载数据创建rdd,通过并行集合(数组)来创建rdd。
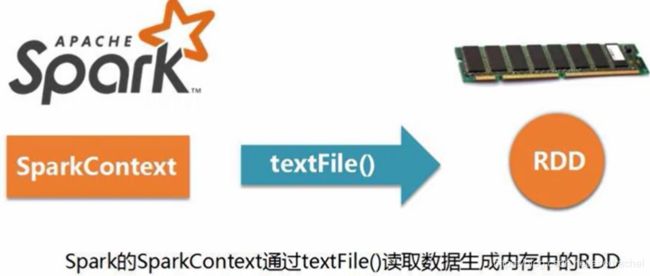
1、通过文件系统加载数据创建rdd
textfile()支持的数据类型:
分布式文件系统HDFS;本地文件系统;云端文件如Amazon S3等

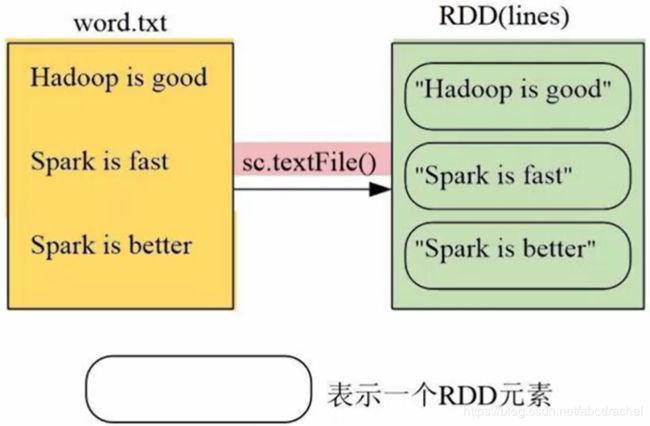
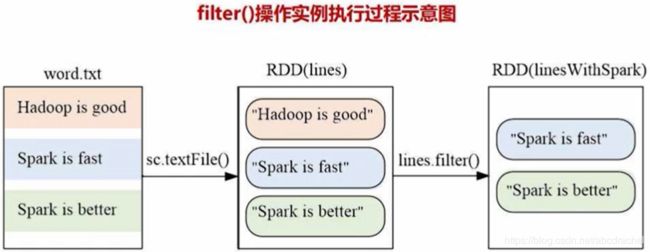
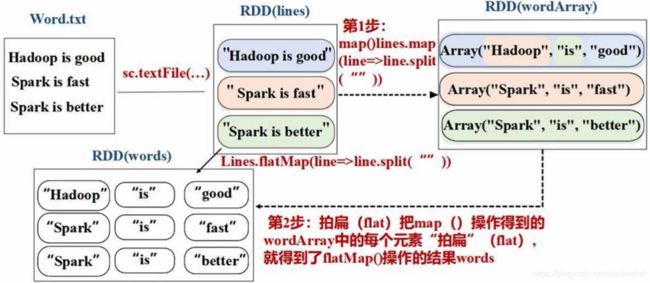
假设现有文档word.txt有三行记录,经过sc.textfile()加载,就生成了上图右侧的RDD,RDD的名称为lines,该RDD包含了三个元素,每个元素对应了文本文件的一行,所以加载后的RDD每个元素是字符串类型。
参看RDD中元素,可使用高阶函数foreach方法,里面传递一个函数作为它的参数,此处传递的是print函数。

hdfs后面是两个斜杠,localhost是主机名,9000为安装hadoop的端口号
在linux系统中,有个主目录,若用hadoop用户名登录linux系统,那么linux系统会自动为hadoop用户创建一个主目录\home\hadoop,简约用~表示。同理在分布式文件系统hdfs中,也存在一个当前用户的用户主目录,该主目录为/user/hadoop.
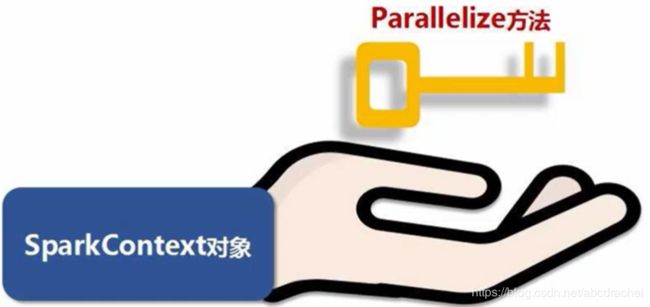
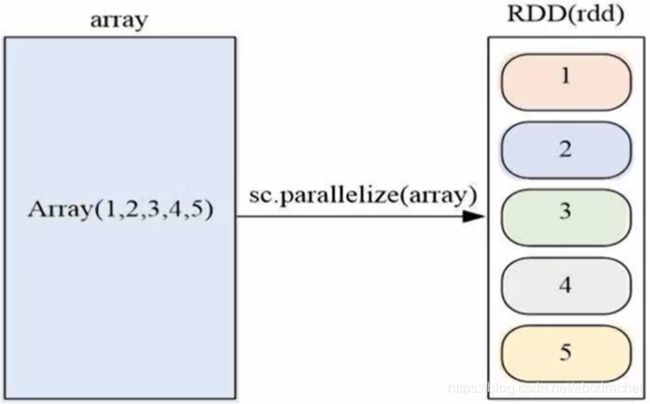
2、并行集合(数组)创建rdd

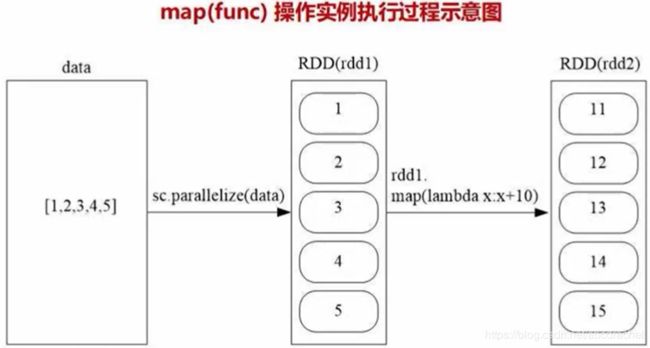
2、RDD操作(转换操作filter、map、flatmap)








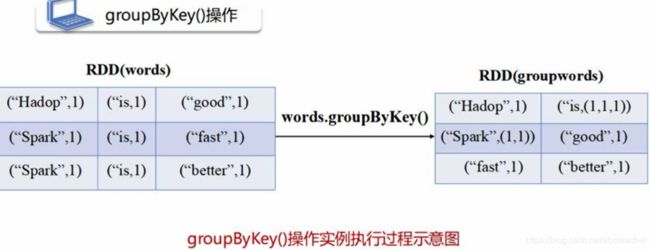
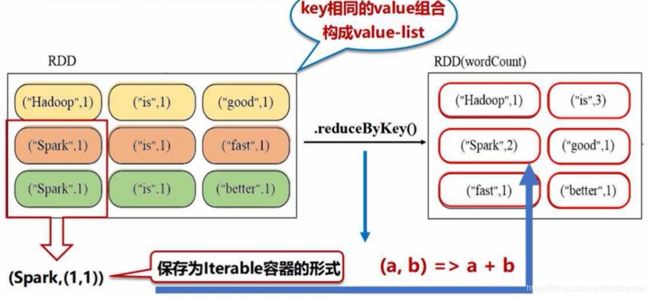
将健封装在用pyspark.resultiterable.ResultIterable对象中

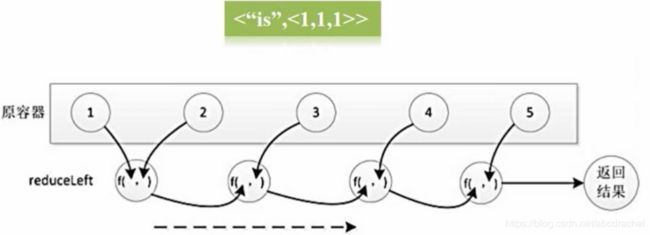

reducebykey相当于先用groupbykey进行操作,得到结果后再执行lambda函数的操作。
3、RDD操作(行动操作)


4、持久化
对于迭代计算,经常需要多次重复使用同一组数据,持久化可以将多次访问的值保存在内存中,不消失,下次再重复使用的时候就需要从头到尾的计算了。


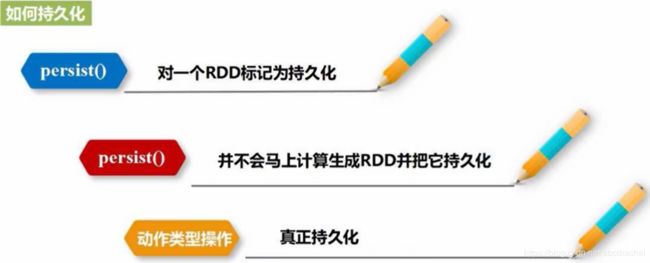
peisist()
persist(memory_only):将RDD作为反序列化对象存在JVM当中,如果内存不足,就按LRU(litte recently use)原则(最近最少使用原则)原则替换内存(仅存在内存当中)。
persist(memory_and_disk):同时保存在内存和磁盘。优先保存内存,若内存不足,再将多余的存入磁盘。
在实际工作中,我们都常使用保存在内存中,对于persist(memory_only)有一个简介的方法:.cache()方法


我们知道当内存中东西太多会降低电脑的速率的,所以当我们使用完并确保后续不在使用之前计算的RDD时,我们需要将该RDD从内存中删除。

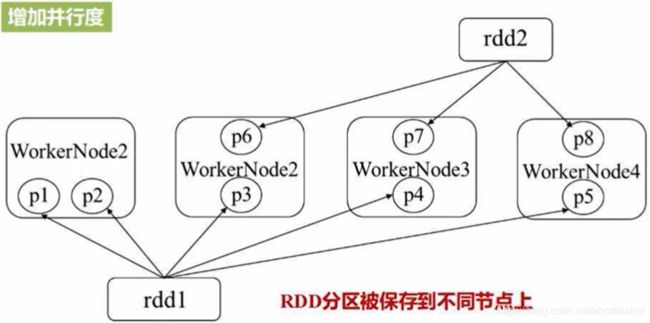
5、RDD分区
RDD分区的好处:1、能够增加并行度,即并行计算;2、减少通信开销

userData表是一个非常庞大的表,有成百上千万的用户,每个用户均有一个userID和userInfo。events表是一个小表,包含两个字段,分别为userID和LinkInfo,记录了这些用户在过去的五分钟之内所访问的网站的链接信息,比如userID为1的用户,访问了新浪网,userID为2的用户,访问了阿里巴巴网,即events记录了每个用户访问的链接信息。
若我们希望找到用户的名字、单位、访问了什么网站,则需要将UserData与events连接起来。这两表的连接就关系到分区的问题。
假设没有分区去做连接,对于userData,数据非常大的时候,数据需要分块存储(注:不是分区),即数据在一台机器上存储不了,需要分块,分块保存在不同机器上,如上图所示的u1块、u2块、u3块等,每块都分布在不同的机器上。假设有一千万用户,这时候u1、u2、u3块等的userID均散布在0至一千万之间(因为不是分区,而是分块,每块的用户信息都是散布在0至一千万之间)。这时候连接采用了一个中间机器,让j1机器负责0至100万的连接,j2机器负责100万到200的连接,以此类推。此时将u1块中0-100万的userID呈给j1,100万-200万的userID呈给j2等,同理针对u2块......。如此这样就会发生如上图所示的大量数据的交叉传输,这就是涉及非常昂贵的通信开销。
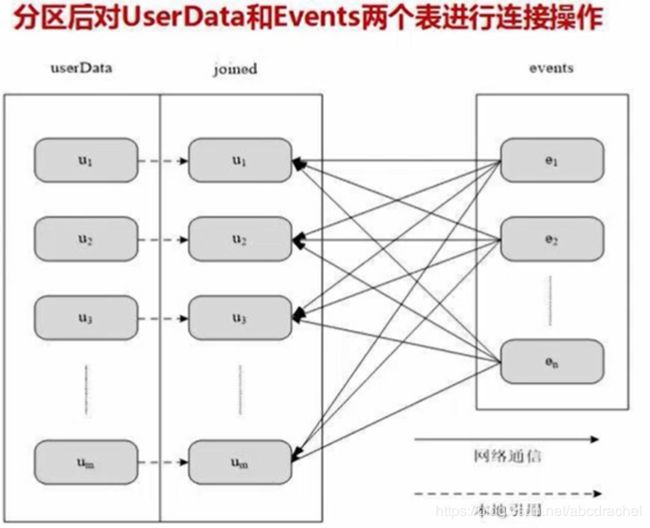
若采取分区处理,如上图所示,让u1只保存0-100万的userID信息,u2只保存100-200万的userID信息,以此类推。如此再与中间机器连接时,按分区后的表进行连接,从而节省了大量数据传输开销。
分区的原则:
分区的个数 尽量等于 集群中CPU核心数目,每个分区启动一个线程
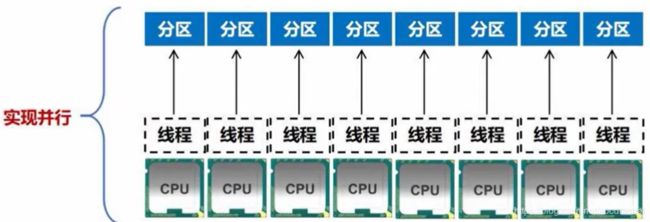
对于不同的spark部署模式而言,可通过设置具体参数值,来配置默认的分区数目,参数名为spark.default.parallelism。
一般而言,local模式,默认为本地机器的CPU数目,若设置了local[N],则默认为N;
对于Apache Mesos模式,默认分区数目为8;
对于Standalone模式和YARN模式,是将集群中所有CPU核心数目总和与2之间取较大值作为分区的默认数目。
如何设置分区个数?
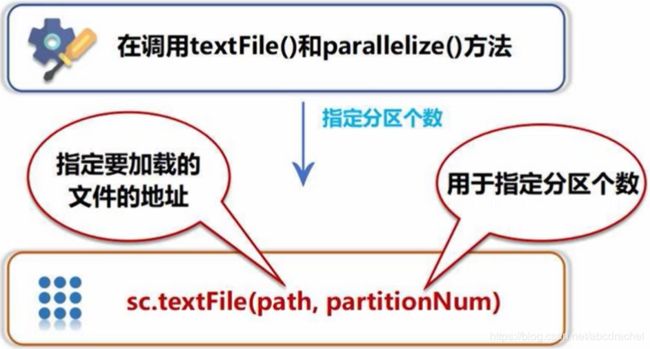
创建时手动指定分区个数:在调用textFile()和parallelize()方式时,可以人工的设定它的分区个数。


自定义分区
spark有哈希分区(HashPartitioner)、区域分区(RangePartitioner)以及自定义分区,自定义分区有时候可进一步减少通信开销,那如何自定义分区呢?
现有实例如下:

要实现如上的分区,需要自定义分区的函数:


.partitionBy是一个重分区的方法,其中参数10表示将要分区的分区个数,MyPartitioner是我们自定义的分区类。partitionBy只接受键值对类型,根据键值对中键进行分区。
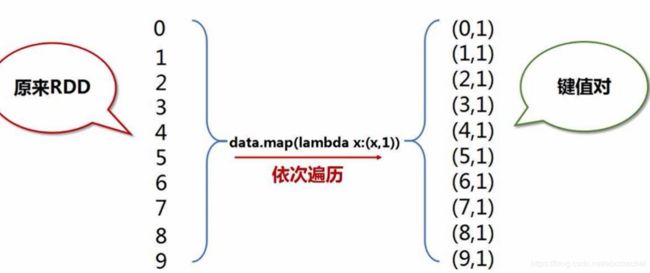
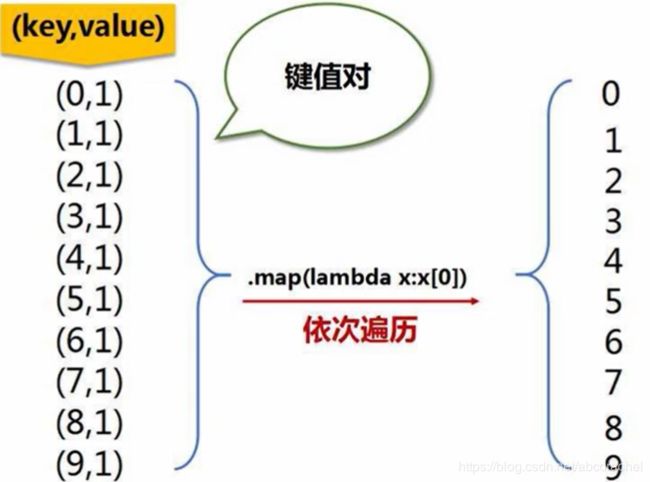


6、综合案例(词频统计)
代码如下(单机):

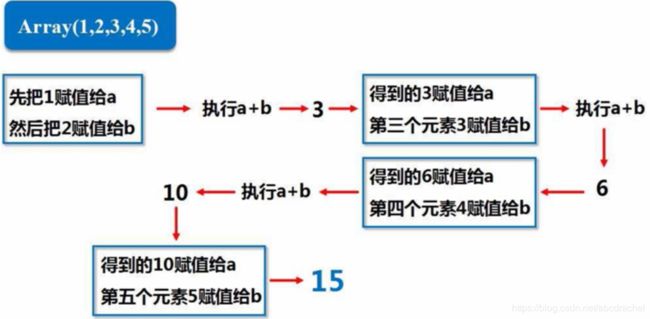
代码运行过程:
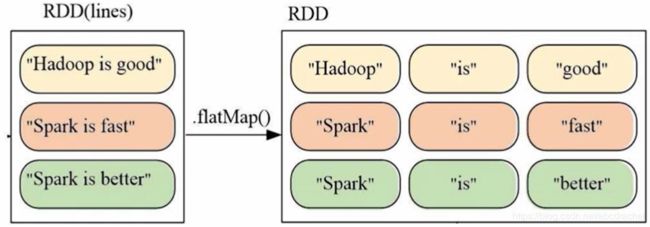
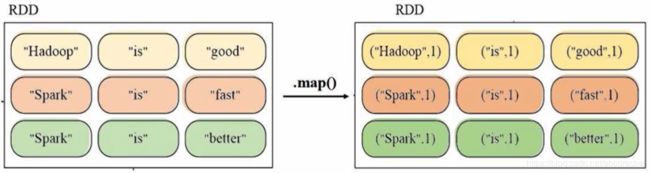
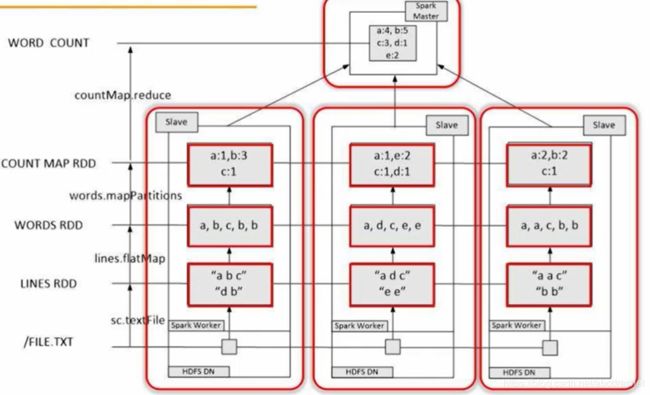
多机并行执行
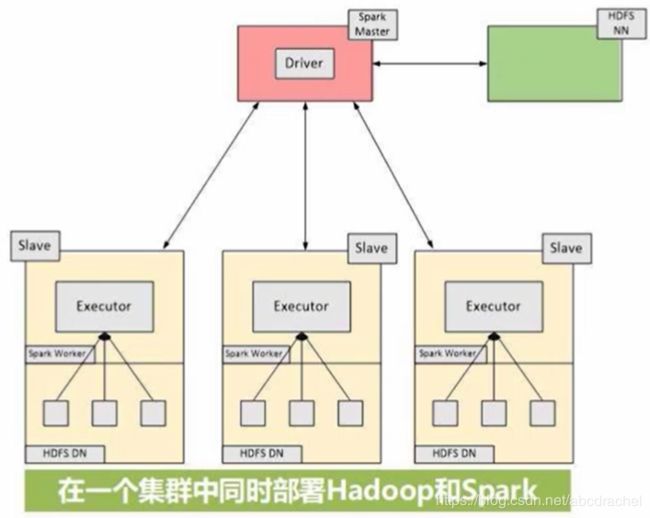
此时需要一个集群进行词频统计,将Hadoop和spark同时部署在同一个集群里面,我们将集群当中的某个节点既作为HDFS的存储节点,也作为Spark的worknode,工作节点,即Hadoop的存储组件和Spark的计算组件是放在了同一台机器上的,如上图所示。如此则可以让Spark对保存在HDFS当中的词频文件进行并行的词频统计,最终将结果进行汇总。
下图详细描述了分布式词频统计的过程。