数据挖掘学习笔记-决策树算法浅析(含Java实现)
目录
一、通俗理解决策树算法原理
二、举例说明算法执行过程
三、Java实现
本文基于书籍《数据挖掘概念与技术》,由于刚接触Data Mining,所以可能有理解不到位的情况,记录学习笔记,提升自己对算法的理解。
代码下方有,如果有金币的童鞋可以贡献一下给无耻的我一枚:
代码传送门:http://download.csdn.net/detail/adiaixin123456/9416398
一、通俗理解决策树算法
决策树算法主要用于分类,分类顾名思义就是将不同的事物进行分类,比如对于银行贷款的客户来说,就可以分为是安全的客户以及存在潜在风险的客户,我们可以根据用户的类型来决定是否给予贷款,以及给多少额度。
决策树是一颗多叉树,它是一种监督学习(监督学习就是提供的训练数据中对每条数据都提供了类标号,例如告诉我们哪些人买了电脑,哪些人没有买)。是通过事务的多个不同属性来对事务进行分类的,这里举一个书上的例子,即电商想对用户是否会买电脑进行预测分析,我们就要对已经买过电脑和其他没有买电脑的人的各项属性来进行分类,发现这个买电脑人有哪些的特性,从而对其他潜在客户进行预测,是否满足这些特性,去推荐用户电脑。可以用来分类的属性有很多,这里只给出书上例子中的,包括年龄、收入、是否是学生、信用这四个维度,当然也可以包含其他的属性,例如职业、居住地、性别等等。这些属性在用户画像中也称为标签。
生成一个决策树主要的步骤1.学习:通过决策树生成算发分析训练数据,生成决策树。2.数据校验:通过校验数据评估这个决策树正确率如何,如果可以接受,就可以用于新数据的分类。
二、算法执行过程
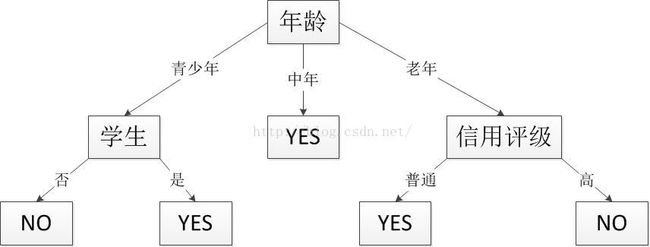
我们先给出一个决策树的例子图如下,表示了用户是否购买电脑的分类。一目了然,在使用时,通过用户的属性的值先比较用户的年龄然后继续向子节点比较,最后得出结果。
2.1在描述算法之前,我们首先要确定几件事情:
(1).属性比较的先后顺序,即那个属性先比较、哪些属性后比较,这里不同的决策树方法如ID3使用的属性的增益,而C4.5作为ID3的改进,选择了属性的增益率。大体的方向都差不多,就是选择出哪个属性对我们要分类的影响最大,就把它放在前面去比较,比如在买电脑上面,性别对分类的影响不大,比如各占50%。而不同的年龄中买电脑的比例就很大,比如老年人购买的几率就很小,而中年人的购买的几率就很大,毕竟工作需要,这样我们就说年龄比性别的增益大,当然这个是有个公式来计算的,我们后面会说。
(2).属性的类型可以分为连续的或离散的,其中离散的表示属性的值的取值范围是可数的,比如标称(类似枚举)、二元属性(类似布尔类型),连续的比如年龄、收入等,对于年龄,因为可以根据时间的单位进行无限的划分,比如按照年、月数、天数、秒、毫秒等等,决策树生成算法需要离散的属性,对于连续的属性要进行离散化,这里我们需要将年龄转化为离散的,比如如上操作,将年龄分为青少年、中年和老年,这个需要由专家来人为划分,或使用其他公式,输入数据的预处理部分
(3).如果想要一个理想的决策树,那么我们就需要大量的真实数据来构建与验证,否则也许会对决策进行误导。
2.2算法描述:
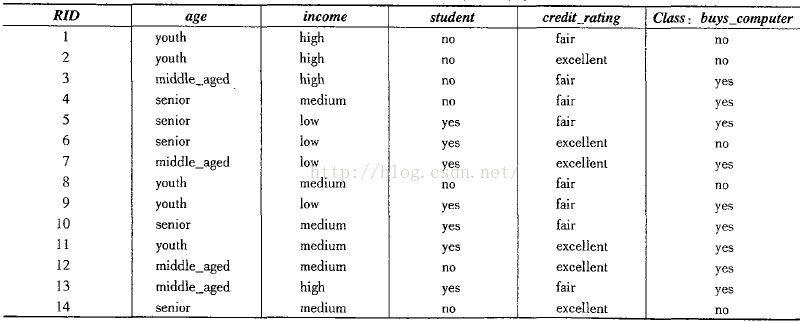
我们使用书上的例子:如下表为客户的数据,并且已经对其做了类标记,即客户有木有购买过电脑
书中决策树的生成算法如下,可以先跳过:

举例说明:
1.算法参数:
(1)带类标号的数据集D,即上面表中的数据,14条。
(2)用户分类的属性集合,该例子中为年龄、收入、是否为学生、信用评级。
(3)找到最好的划分属性的方法,即我们之前提过的如果确定哪个属性优先进行比较,这里使用ID3的,属性增益来计算。
2.算法过程:
1.在属性的集合中选择一个最好的划分属性,作为根分裂节点,属性A的增益计算公式为
其中
,期望信息,又称为熵
m为类的值种类个数,本例中,m为2(buys_computer只有买或不买两种)
pi为类每个值出现的概率,p1=9/14,即buys_computer是yes的个数为9,总共数据集个数为14。同理p2=5/14

用来表示属性每个分区(分支)的纯度,所有的数据都是同一类就最纯,InfoA(D)=0
v为属性值分区个数,已属性age为例,v=3,因为只有youth,middle_aged,senior三种
|Dj|为每个分区数据的个数,D1为youth:5,D2=4,D3=5
下面式子中2/5表示在age=youth中有2个买了电脑,3/5,3个没有买
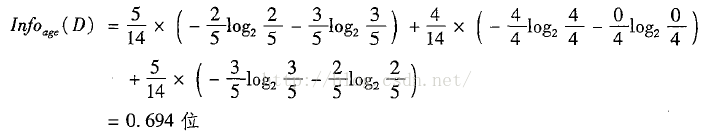
2.选出来增益最高的属性后就将该属性作为节点(本例中为age),将属性集合删除age,并对数据集拆分后继续向子节点计算

3.重复1、2步骤,直到
(1)数据集中所有的数据都属于一类,设为该结点为叶子,值设置为数据中类的值,如该例子中所有age=middle_aged的都购买了电脑,值都设置为YES
(2)属性集合为空,设该结点为叶子,值为数据中类的数量最多的分类的值,即对于buys_computer,yes的个数 > no的个数 ? yes : no
本例中最后得出的决策树就为最开始举例的那棵,由于数据太少以及属性选择的少,导致income这个属性没有用到,就已经分好了类:
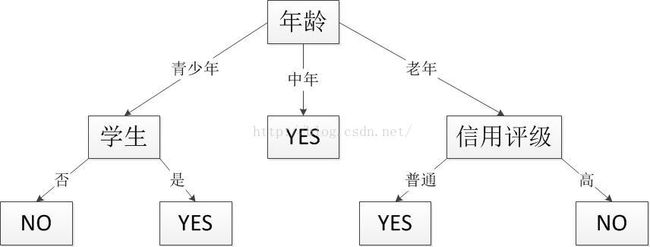
三、算法Java实现
3.1目录结构(忽略的我英文名称...)
项目的目录结构分为四个文件夹algorithm,common,data,test(1)algorithm为算法,包括DecisionTree(决策树生成算法)、IAttrSelector(最佳分裂点属性选择算法接口)、BaseAttrSelector(基础的属性选择算法实现)(2)common为公用类,只包含了表示多叉树的类TreeNode(3)data为数据,包含了BaseRecord(基础记录,这里只有一个属性,就是要分类的属性Boolean的,其他数据库实体都应该继承该类)
HummanAttrRecord(描述用户的属性类,包括收入、年龄、是否为学生、信用评级)、EmAgeLevel(年龄枚举类)、EmCreditRate(信用枚举类)、EmIncome(收入枚举类)。
(4)test为测试类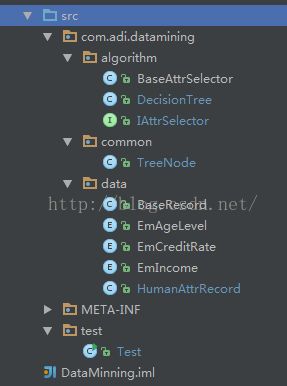
3.2类文件列表
package com.adi.datamining.algorithm;
import com.adi.datamining.data.BaseRecord;
import com.adi.datamining.common.TreeNode;
import java.lang.reflect.Field;
import java.util.ArrayList;
import java.util.List;
import java.util.Set;
/**
* Created by wudi on 2016/1/22.
*/
public class DecisionTree {
IAttrSelector selector;
public DecisionTree(IAttrSelector selector) {
this.selector = selector;
}
/**创建决策树*/
public TreeNode createTree(List records, Set attrSet) {
if(null == records || records.size() < 1)
return null;
TreeNode node = new TreeNode();
//1.如果所有的记录分类属性值都相同,如果全部相同则直接返回分类属性值
if(isAllInSameClass(records)){
node.setAttrName(String.valueOf(records.get(0).getDecisionAttr()));
return node;
}
//2.如果属性列表为空,统计记录集合中正负样例个数,正>负?true:false
if(null == attrSet || 0 == attrSet.size()){
node.setAttrName(String.valueOf(getMostClass(records)));
return node;
}
//3.选择出来增益最大的属性
Field bestField = selector.select(records,attrSet);
//4.根据最好属性的值分为多个分支
List> splitValues = splitRecords(records, bestField);
List children = new ArrayList(splitValues.size());
attrSet.remove(bestField);
//5.遍历子节点
for (List recordList : splitValues) {
children.add(createTree(recordList, attrSet));
}
node.setTreeNodeList(children);
node.setAttrName(bestField.getName());
return node;
}
/**根据属性的值分不同列表*/
private List> splitRecords(List records, Field field) {
List> result = new ArrayList>();
try {
field.setAccessible(true);
outerLoop :
for(BaseRecord record : records) {
Object value = field.get(record);
for(List recordList : result) {
if(field.get(recordList.get(0)).equals(value)) {
recordList.add(record);
continue outerLoop;
}
}
List recordList = new ArrayList();
recordList.add(record);
result.add(recordList);
}
} catch (Exception ex) {
System.out.println("method access exception");
}
return result;
}
/**根据列表中分类的正负样例个数决定叶子节点为true or false*/
private Boolean getMostClass(List records) {
int positCount = 0;
int negatCount = 0;
for(BaseRecord record : records) {
if(record.getDecisionAttr())
++positCount;
else
++negatCount;
}
return positCount > negatCount ? true : false;
}
/**判断所有记录是否具有相同的分类值*/
private boolean isAllInSameClass(List records) {
Boolean buyComp = records.get(0).getDecisionAttr();
for(BaseRecord record : records) {
if(!buyComp.equals(record.getDecisionAttr()))
return false;
}
return true;
}
}
package com.adi.datamining.algorithm;
import com.adi.datamining.data.BaseRecord;
import java.lang.reflect.Field;
import java.util.List;
import java.util.Set;
/**
* Created by wudi on 2016/1/23.
*/
public interface IAttrSelector {
public Field select(List records, Set atrrs);
}
package com.adi.datamining.algorithm;
import com.adi.datamining.data.BaseRecord;
import java.lang.reflect.Field;
import java.util.*;
/**
* Created by wudi10 on 2016/1/23.
*/
public class BaseAttrSelector implements IAttrSelector{
/**通过记录集合与记录的属性集合,挑选出属性中增益度最大的属性*/
@Override
public Field select(List records, Set atrrs){
Field bestField = null;
Double highestScore = 0D;
Double setInfo = entropy(records);
for(Field field : atrrs) {
Double gainScore = setInfo - infoScore( records, field);
if(gainScore > highestScore) {
highestScore = gainScore;
bestField = field;
}
}
return bestField;
}
/**根据记录列表求关于所求类的熵,此方法中要分的类是DcisionAtrr*/
private Double entropy(List records) {
Double positCount = 0D;
Double negatCount = 0D;
for(BaseRecord record : records) {
if(record.getDecisionAttr())
++positCount;
else
++negatCount;
}
return - positCount/records.size()* log2N(positCount / records.size())
- negatCount/records.size()* log2N(negatCount / records.size());
}
/**log2(N), log 以2为底N的对数*/
private Double log2N(Double d) {
return Math.log(d) / Math.log(2.0);
}
/**求某个属性对于分类DecisionAttr的期望分数,公式见<数据挖掘概念与技术>中决策树那节*/
private Double infoScore(List records, Field field) {
Double infoScore = 0D;
try {
//1.求该属性每个值对于分类的正负样例个数,即有多少是true,多少个false;
Map> count4Values = new HashMap>();//key:存放该属性不同值,value:长度为2,存放该属性值对分类正负样例数
Integer size = records.size();
field.setAccessible(true);
for(BaseRecord record : records) {
Object attrValue = field.get(record);
List countList = count4Values.get(attrValue);
if(countList == null) {
countList = new ArrayList(2);
countList.add(0,0);
countList.add(1,0);
}
if(record.getDecisionAttr()){
countList.set(0,countList.get(0) + 1);
} else {
countList.set(1,countList.get(1) + 1);
}
count4Values.put(attrValue, countList);
}
//2.遍历map算出期望值
for(Object key : count4Values.keySet()) {
List countList = count4Values.get(key);
double positCount = countList.get(0);
double negatCount = countList.get(1);
if(positCount == 0 || negatCount == 0) //对于正负样例个数为0的情况,视为无效,对分类影响最大,分数为0;
continue;
double valueCount = positCount + negatCount;
infoScore += valueCount/size * ( - (positCount/valueCount) * log2N(positCount / valueCount)
- (negatCount/valueCount) * log2N(negatCount/valueCount));
}
} catch (Exception ex) {
System.out.println("method access exception");
}
return infoScore;
}
}
package com.adi.datamining.common;
import java.util.List;
/**
* Created by wudi on 2016/1/22.
* 多叉树
*/
public class TreeNode {
private String attrName;
private List treeNodeList;
public TreeNode(){}
public TreeNode(String attrName, List treeNodeList) {
this.attrName = attrName;
this.treeNodeList = treeNodeList;
}
public String getAttrName() {
return attrName;
}
public void setAttrName(String attrName) {
this.attrName = attrName;
}
public List getTreeNodeList() {
return treeNodeList;
}
public void setTreeNodeList(List treeNodeList) {
this.treeNodeList = treeNodeList;
}
public void print(int level) {
if(null == this)
return;
for (int i=0; i package com.adi.datamining.data;
/**
* Created by wudi on 2016/1/23.
*/
public class BaseRecord {
private Boolean decisionAttr;
public BaseRecord(Boolean decisionAttr) {
this.decisionAttr = decisionAttr;
}
public Boolean getDecisionAttr() {
return decisionAttr;
}
public void setDecisionAttr(Boolean decisionAttr) {
this.decisionAttr = decisionAttr;
}
}
package com.adi.datamining.data;
/**
* Created by wudi on 2016/1/22.
*/
public class HumanAttrRecord extends BaseRecord{
private EmAgeLevel age;
private EmIncome income;
private Boolean isStudent;
private EmCreditRate creditRate;
public HumanAttrRecord(EmAgeLevel age, EmIncome income, Boolean isStudent, EmCreditRate creditRate, Boolean decisionAttr) {
super(decisionAttr);
this.age = age;
this.income = income;
this.isStudent = isStudent;
this.creditRate = creditRate;
}
public EmAgeLevel getAge() {
return age;
}
public void setAge(EmAgeLevel age) {
this.age = age;
}
public EmIncome getIncome() {
return income;
}
public void setIncome(EmIncome income) {
this.income = income;
}
public Boolean getIsStudent() {
return isStudent;
}
public void setIsStudent(Boolean isStudent) {
this.isStudent = isStudent;
}
public EmCreditRate getCreditRate() {
return creditRate;
}
public void setCreditRate(EmCreditRate creditRate) {
this.creditRate = creditRate;
}
}
package com.adi.datamining.data;
/**
* Created by wudi10 on 2016/1/22.
*/
public enum EmAgeLevel {
SENIOR(1, "高龄人"),
MIDDLE_AGED(2,"中龄人"),
YOUTH(3,"年轻人");
private final Integer level;
private final String desc;
private EmAgeLevel(Integer level, String desc) {this.level = level;this.desc = desc;}
public Integer getLevel(){return this.level;}
}
package com.adi.datamining.data;
/**
* Created by wudi10 on 2016/1/22.
*/
public enum EmCreditRate {
EXCELLENT(1, "优秀"),
FAIR(2,"正常");
private final Integer level;
private final String desc;
private EmCreditRate(Integer level, String desc) {this.level = level;this.desc = desc;}
public Integer getLevel(){return this.level;}
}package com.adi.datamining.data;
/**
* Created by wudi10 on 2016/1/22.
*/
public enum EmIncome {
HIGH(1, "高收入"),
MEDIUM(2,"中收入"),
LOW(3,"低收入");
private final Integer level;
private final String desc;
private EmIncome(Integer level, String desc) {this.level = level;this.desc = desc;}
public Integer getLevel(){return this.level;}
}
package test;
import com.adi.datamining.algorithm.BaseAttrSelector;
import com.adi.datamining.algorithm.DecisionTree;
import com.adi.datamining.algorithm.IAttrSelector;
import com.adi.datamining.common.TreeNode;
import com.adi.datamining.data.*;
import java.lang.reflect.Field;
import java.util.ArrayList;
import java.util.HashSet;
import java.util.List;
import java.util.Set;
/**
* Created by wudi on 2016/1/23.
*/
public class Test {
public static void main(String[] arr) {
List records = new ArrayList();
HumanAttrRecord record0 = new HumanAttrRecord(EmAgeLevel.YOUTH, EmIncome.HIGH,false, EmCreditRate.FAIR,false);
HumanAttrRecord record1 = new HumanAttrRecord(EmAgeLevel.YOUTH, EmIncome.HIGH,false, EmCreditRate.EXCELLENT,false);
HumanAttrRecord record2 = new HumanAttrRecord(EmAgeLevel.MIDDLE_AGED, EmIncome.HIGH,false, EmCreditRate.FAIR,true);
HumanAttrRecord record3 = new HumanAttrRecord(EmAgeLevel.SENIOR, EmIncome.MEDIUM,false, EmCreditRate.FAIR,true);
HumanAttrRecord record4 = new HumanAttrRecord(EmAgeLevel.SENIOR, EmIncome.LOW,true, EmCreditRate.FAIR,true);
HumanAttrRecord record5 = new HumanAttrRecord(EmAgeLevel.SENIOR, EmIncome.LOW,true, EmCreditRate.EXCELLENT,false);
HumanAttrRecord record6 = new HumanAttrRecord(EmAgeLevel.MIDDLE_AGED, EmIncome.LOW,true, EmCreditRate.EXCELLENT,true);
HumanAttrRecord record7 = new HumanAttrRecord(EmAgeLevel.YOUTH, EmIncome.MEDIUM,false, EmCreditRate.FAIR,false);
HumanAttrRecord record8 = new HumanAttrRecord(EmAgeLevel.YOUTH, EmIncome.LOW,true, EmCreditRate.FAIR,true);
HumanAttrRecord record9 = new HumanAttrRecord(EmAgeLevel.SENIOR, EmIncome.MEDIUM,true, EmCreditRate.FAIR,true);
HumanAttrRecord record10 = new HumanAttrRecord(EmAgeLevel.YOUTH, EmIncome.MEDIUM,true, EmCreditRate.EXCELLENT,true);
HumanAttrRecord record11 = new HumanAttrRecord(EmAgeLevel.MIDDLE_AGED, EmIncome.MEDIUM,false, EmCreditRate.EXCELLENT,true);
HumanAttrRecord record12 = new HumanAttrRecord(EmAgeLevel.MIDDLE_AGED, EmIncome.HIGH,true, EmCreditRate.FAIR,true);
/* HumanAttrRecord record13 = new HumanAttrRecord(EmAgeLevel.SENIOR, EmIncome.LOW,false, EmCreditRate.EXCELLENT,false);
HumanAttrRecord record14 = new HumanAttrRecord(EmAgeLevel.YOUTH, EmIncome.MEDIUM,false, EmCreditRate.FAIR,false);
HumanAttrRecord record15 = new HumanAttrRecord(EmAgeLevel.MIDDLE_AGED, EmIncome.MEDIUM,true, EmCreditRate.EXCELLENT,true);
HumanAttrRecord record16 = new HumanAttrRecord(EmAgeLevel.SENIOR, EmIncome.LOW,false, EmCreditRate.EXCELLENT,true);
HumanAttrRecord record17 = new HumanAttrRecord(EmAgeLevel.YOUTH, EmIncome.HIGH,true, EmCreditRate.EXCELLENT,true);
HumanAttrRecord record18 = new HumanAttrRecord(EmAgeLevel.YOUTH, EmIncome.MEDIUM,false, EmCreditRate.EXCELLENT,false);
HumanAttrRecord record19 = new HumanAttrRecord(EmAgeLevel.SENIOR, EmIncome.LOW,false, EmCreditRate.FAIR,false);
*/
records.add(record0);
records.add(record1);
records.add(record2);
records.add(record3);
records.add(record4);
records.add(record5);
records.add(record6);
records.add(record7);
records.add(record8);
records.add(record9);
records.add(record10);
records.add(record11);
records.add(record12);
/* records.add(record13);
records.add(record14);
records.add(record15);
records.add(record16);
records.add(record17);
records.add(record18);
records.add(record19);*/
Set fieldSet = new HashSet();
Field[] fields = HumanAttrRecord.class.getDeclaredFields();
for (Field field : fields) {
if(field.getName().equals("decisionAttr")) continue;;
fieldSet.add(field);
}
IAttrSelector selector = new BaseAttrSelector();
DecisionTree decisionTree = new DecisionTree(selector);
TreeNode root = decisionTree.createTree(records,fieldSet);
if(null != root) {
root.print(0);
}
}
}
3.3运行Test即可得到结果如下:(请忽略我的显示方式....)