Java8新特性
目录
1、Lambda表达式
2、函数式接口
3、接口的默认方法和静态方法
4、方法引用
4.1、引用方法
4.2、引用构造方法
4.3、引用数组
5、Optional
6、Stream
6.1、什么是Stream
6.2、Stream的特点
6.3、Stream的构成
6.4、生成Stream的方式
6.5、Stream的操作类型
6.6、Stream的使用
6.7、Stream总结
7、Date/Time API
7.1、LocalDate类
7.2、LocalTime类
7.3、LocalDateTime类
7.4、ZoneDateTime类
7.5、Clock类
7.6、Duration类
8、其他特性
8.1、重复注解
8.2、扩展注解
8.3、更好的类型推测机制
8.4、参数名字保留在字节码中
8.5、并行数组
8.6、CompletableFuture
8.7、JVM的新特性
1、Lambda表达式
在JDK8之前,一个方法能接受的参数都是变量,例如: object.method(Object o)
那么,如果需要传入一个动作呢?比如回调。
那么你可能会想到匿名内部类。
例如:
匿名内部类是需要依赖接口的,所以需要先定义个接口
public interface PersonCallBack {
void callBack(Person person);
}Person类
public class Person {
private int id;
private String name;
public Person (int id, String name) {
this.id = id;
this.name = name;
}
/**
* 创建一个Person后进行回调
* @param id
* @param name
* @param personCallBack
*/
public static void create(Integer id, String name, PersonCallBack personCallBack) {
Person person = new Person(id, name);
personCallBack.callBack(person);
}
}调用方法:
// 调用方法,传入回调类,传统方式,使用匿名内部类
Person.create(1, "zhangsan", new PersonCallBack() {
@Override
public void callBack(Person person) {
System.out.println("callback -- " +person.getName());
}
});上面的PersonCallback其实就是一种动作,但是我们真正关心的只有callback方法里的内容而已,我们用Lambda
表示,可以将上面的代码就可以优化成:
// 使用lambda表达式实现
Person.create(2, "lisi", (person) -> {System.out.println("lambda callback -- " +person.getName());});
// 进一步简化
// 这归功于Java8的类型推导机制。因为现在接口里只有一个方法,那么现在这个Lambda表达式肯定是对应实现了这个方法,
// 既然是唯一的对应关系,那么入参肯定是Person类,所以可以简写,
// 并且方法体只有唯一的一条语句,所以也可以简写,以达到表达式简洁的效果。
Person.create(2, "lisi", person -> System.out.println("lambda callback -- " +person.getName()));Lambda允许把函数作为一个方法的参数,一个lambda由用逗号分隔的参数列表、–>符号、函数体三部分表示。
一个Lambda表达式实现了接口里的有且仅有的唯一一个抽象方法。那么对于这种接口就叫做函数式接口。
Lambda表达式其实完成了实现接口并且实现接口里的方法这一功能,也可以认为Lambda表达式代表一种动作,
我们可以直接把这种特殊的动作进行传递。
2、函数式接口
函数式接口是新增的一种接口定义。
用@FunctionalInterface修饰的接口叫做函数式接口,或者,函数式接口就是一个只具有一个抽象方法的普通接口,@FunctionalInterface可以起到校验的作用。
@FunctionalInterface
public interface MyFunctionInterface {
/**
* 函数式接口的唯一抽象方法
*/
void method();
}在JDK7中其实就已经有一些函数式接口了,比如Runnable、Callable、FileFilter等等。
在JDK8中也增加了很多函数式接口,比如java.util.function包。
比如这四个常用的接口:
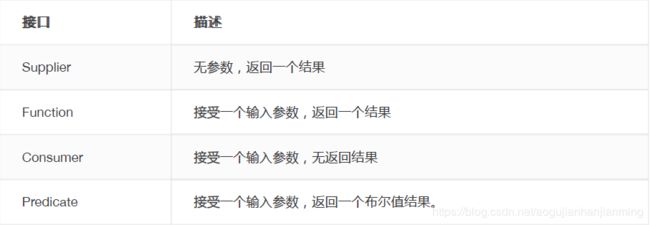
一个Lambda表达式其实也可以理解为一个函数式接口的实现者,但是作为表达式,它的写法
其实是多种多样的,比如
- () -> {return 0;},没有传入参数,有返回值
- (int i) -> {return 0;},传入一个参数,有返回值
- (int i) -> {System.out.println(i)},传入一个int类型的参数,但是没有返回值
- (int i, int j) -> {System.out.println(i)},传入两个int类型的参数,但是没有返回值
- (int i, int j) -> {return i+j;},传入两个int类型的参数,返回一个int值
- (int i, int j) -> {return i>j;},传入两个int类型的参数,返回一个boolean值
那么这每种表达式的写法其实都应该是某个函数式接口的实现类,需要特定函数式接口进行对应,比如上面的四种情况就分别对应:Supplier
Java8中提供给我们这么多函数式接口就是为了让我们写Lambda表达式更加方便,当然遇到特殊情况,你还是需要定义你自己的函数式接口然后才能写对应的Lambda表达式。
总的来说,如果没有函数式接口,就不能写Lambda表达式。
3、接口的默认方法和静态方法
在接口中用default修饰的方法称为默认方法。
接口中的默认方法一定要有默认实现(方法体),接口实现者可以继承它,也可以覆盖它。
/**
* 接口的默认方法
* @param s
* @return
*/
default String methodDefault(String s) {
System.out.println(s);
return "res--" + s;
}在接口中用static修饰的方法称为静态方法。
/**
* 接口的静态方法
* @param a
* @param b
* @return
*/
static String methodStatic(String a, String b) {
return a + b;
}4、方法引用
4.1、引用方法
- 实例对象::实例方法名
- 类名::静态方法名
- 类名::实例方法名
// 引用方法1 实例对象::实例方法名
// System.out代表的就是PrintStream类型的一个实例,println是这个实例的一个方法
// Consumer consumer1 = s -> System.out.println(s);
Consumer consumer2 = System.out::println;
consumer2.accept("呵呵");
// 引用方法2 类名::静态方法名
// Function中的唯一抽象方法apply方法参数列表与abs方法的参数列表相同,都是接收一个Long类型参数。
// Function f = x -> Math.abs(x);
Function f = Math::abs;
Long result = f.apply(-3L);
// 引用方法3 类名::实例方法名
// 若Lambda表达式的参数列表的第一个参数,是实例方法的调用者,第二个参数(或无参)是实例方法的参数时,就可以使用这种方法
// BiPredicate b = (x,y) -> x.equals(y);
BiPredicate b = String::equals;
b.test("a", "b"); 4.2、引用构造方法
// 引用构造方法
// 在引用构造方法的时候,构造方法参数列表要与接口中抽象方法的参数列表一致,格式为 类名::new
// Function fun = n -> new StringBuffer(n);
Function fun = StringBuffer::new;
StringBuffer buffer = fun.apply(10); 4.3、引用数组
// 引用数组
// 引用数组和引用构造器很像,格式为 类型[]::new,其中类型可以为基本类型也可以是类
// Function fun = n -> new int[n];
Function fun1 = int[]::new;
int[] arr = fun1.apply(10);
Function fun2 = Integer[]::new;
Integer[] arr2 = fun2.apply(10); 5、Optional
Optional实际上是个容器:它可以保存类型T的值,或者仅仅保存null。Optional提供很多有用的方法,这样我们就不用显式进行空值检测。
创建Optional对象的几个方法:
- Optional.of(T value), 返回一个Optional对象,value不能为空,否则会出空指针异常
- Optional.ofNullable(T value), 返回一个Optional对象,value可以为空
- Optional.empty(),代表空
其他API:
- optional.isPresent(),是否存在值(不为空)
- optional.ifPresent(Consumer consumer), 如果存在值则执行consumer
- optional.get(),获取value
- optional.orElse(T other),如果没值则返回other
- optional.orElseGet(Supplier other),如果没值则执行other并返回
- optional.orElseThrow(Supplier exceptionSupplier),如果没值则执行exceptionSupplier,并抛出异常
高级API:
- optional.map(Function mapper),映射,映射规则由function指定,返回映射值的Optional,所以可以继续使用Optional的API。
- optional.flatMap(Function > mapper),同map类似,区别在于map中获取的返回值自动被Optional包装,flatMap中返回值保持不变,但入参必须是Optional类型。
- optional.filter(Predicate predicate),过滤,按predicate指定的规则进行过滤,不符合规则则返回empty,也可以继续使用Optional的API。
/**
* 防止空指针,使用Optional
* @param person
* @return
*/
public static String getPersonNameOptional(Person person) {
// 使用Optional对person进行包装
return Optional.ofNullable(person).map((per) -> per.getName()).orElse(null);
}
/**
* 防止空指针,原有实现方法
* @param person
* @return
*/
public static String getPersonName(Person person) {
// 防止空指针,进行非空判断
if (person == null) {
return null;
}
return person.getName();
}使用 Optional 时尽量不直接调用 Optional.get() 方法, Optional.isPresent() 更应该被视为一个私有方法, 应依赖于
其他像 Optional.orElse(), Optional.orElseGet(), Optional.map() 等这样的方法。
6、Stream
Java 8 中的 Stream 是对集合(Collection)对象功能的增强,它专注于对集合对象进行各种非常便利、高效的聚合操作(aggregate operation),或者大批量数据操作 (bulk data operation)。Stream API 借助于同样新出现的 Lambda 表达式,极大的提高编程效率和程序可读性。同时它提供串行和并行两种模式进行汇聚操作,并发模式能够充分利用多核处理器的优势,使用 fork/join 并行方式来拆分任务和加速处理过程。通常编写并行代码很难而且容易出错, 但使用 Stream API 无需编写一行多线程的代码,就可以很方便地写出高性能的并发程序。所以说,Java 8 中首次出现的 java.util.stream 是一个函数式语言+多核时代综合影响的产物。
在传统的 J2EE 应用中,Java 代码经常不得不依赖于关系型数据库的操作如:取平均值、取最大最小值、取汇总值、或者进行分组等等类似的这些操作。
但在当今这个数据大爆炸的时代,在数据来源多样化、数据海量化的今天,很多时候不得不脱离 RDBMS,或者以底层返回的数据为基础进行更上层的数据统计。而 Java 的集合 API 中,仅仅有极少量的辅助型方法,更多的时候是程序员需要用 Iterator 来遍历集合,完成相关的聚合应用逻辑。这是一种远不够高效、笨拙的方法。在Java 7 中,如果要找一年级的所有学生,然后返回按学生分数值降序排序好的学生ID的集合,我们需要这样写:
public class Student {
/**
* ID
*/
private Integer id;
/**
* 年级
*/
private Grade grade;
/**
* 分数
*/
private Integer score;
public Student(Integer id, Grade grade, Integer score) {
this.id = id;
this.grade = grade;
this.score = score;
}
public Integer getId() {
return id;
}
public void setId(Integer id) {
this.id = id;
}
public Grade getGrade() {
return grade;
}
public void setGrade(Grade grade) {
this.grade = grade;
}
public Integer getScore() {
return score;
}
public void setScore(Integer score) {
this.score = score;
}
}public enum Grade {
ONE, TWO, THREE
} /**
* 传统方法
* @param studentList
* @return
*/
public static List oldMethod(List studentList) {
// 取出一年级学生
List gradeOneStudentList = new ArrayList<>();
for (Student student : studentList) {
if (Grade.ONE.equals(student.getGrade())) {
gradeOneStudentList.add(student);
}
}
// 按成绩排序
Collections.sort(gradeOneStudentList, new Comparator() {
@Override
public int compare(Student o1, Student o2) {
return o1.getScore().compareTo(o2.getScore());
}
});
// Collections.sort(gradeOneStudentList, Comparator.comparing(Student::getScore));
List studentIdList = new ArrayList<>();
for (Student student : gradeOneStudentList) {
studentIdList.add(student.getId());
}
return studentIdList;
} 而在 Java 8 使用 Stream,代码更加简洁易读;而且使用并发模式,程序执行速度更快。
/**
* 使用stream
* @param studentList
* @return
*/
public static List newMethod(List studentList) {
return studentList.stream()
.filter((student -> student.getGrade().equals(Grade.ONE)))
.sorted(Comparator.comparingInt(Student::getScore))
.map(Student::getId)
.collect(Collectors.toList());
} 6.1、什么是Stream
Stream 不是集合元素,它不是数据结构并不保存数据,它是有关算法和计算的,它更像一个高级版本的Iterator。
6.2、Stream的特点
- Iterator,用户只能显式地一个一个遍历元素并对其执行某些操作; Stream,用户只要给出需要对其包含的元素执行什么操作,比如 “过滤掉长度大于 10 的字符串”、“获取每个字符串的首字母”等,Stream 会隐式地在内部进行遍历,做出相应的数据转换。
- Stream 就如同一个Iterator,单向,不可往复,数据只能遍历一次,遍历过一次后即用尽了,就好比流水从面前流过,一去不复返。
- Stream 可以并行化操作,Iterator只能命令式地、串行化操作。顾名思义,当使用串行方式去遍历时,每个 item 读完后再读下一个 item。而使用并行去遍历时,数据会被分成多个段,其中每一个都在不同的线程中处理,然后将结果一起输出。Stream 的并行操作依赖于 Java7 中引入的 Fork/Join 框架来拆分任务和加速处理过程。
6.3、Stream的构成
当我们使用一个流的时候,通常包括三个基本步骤:
获取一个数据源(source)→ 数据转换→执行操作获取想要的结果,每次转换原有 Stream 对象不改变,返回一
个新的 Stream 对象(可以有多次转换),这就允许对其操作可以像链条一样排列,变成一个管道
6.4、生成Stream的方式
1. 从Collection 和数组生成
Collection.stream()
Collection.parallelStream()
Arrays.stream(T array)
Stream.of(T t)
2. 从 BufferedReader
java.io.BufferedReader.lines()
3. 静态工厂
java.util.stream.IntStream.range()
java.nio.file.Files.walk()
4. 自己构建
java.util.Spliterator
5. 其它
Random.ints()
BitSet.stream()
Pattern.splitAsStream(java.lang.CharSequence)
JarFile.stream()
6.5、Stream的操作类型
- 中间操作(Intermediate Operation):一个流可以后面跟随零个或多个 intermediate 操作。其目的主要是打开流,做出某种程度的数据映射/过滤,然后返回一个新的流,交给下一个操作使用。这类操作都是惰性化的(lazy),就是说,仅仅调用到这类方法,并没有真正开始流的遍历。
- 终止操作(Terminal Operation):一个流只能有一个 terminal 操作,当这个操作执行后,流就被使用“光”了,无法再被操作。所以这必定是流的最后一个操作。Terminal 操作的执行,才会真正开始流的遍历,并且会生成一个结果。
Intermediate Operation又可以分为两种类型:
- 无状态操作(Stateless Operation):操作是无状态的,不需要知道集合中其他元素的状态,每个元素之间是相互独立的,比如map()、filter()等操作。
- 有状态操作(Stateful Operation):有状态操作,操作是需要知道集合中其他元素的状态才能进行的,比如sort()、distinct()。
Terminal Operation从逻辑上可以分为两种:
- 短路操作(short-circuiting):短路操作是指不需要处理完所有元素即可结束整个过程
- 非短路操作(non-short-circuiting):非短路操作是需要处理完所有元素之后才能结束整个过程
6.6、Stream的使用
- 1. 构造流的几种常见方法
// 1、构造流的常用方法
// 1> Individual values
Stream stream = Stream.of("a", "b", "c");
// 2> Arrays
String [] strArray = new String[] {"a", "b", "c"};
stream = Stream.of(strArray);
stream = Arrays.stream(strArray);
// 3> Collections
List list = Arrays.asList(strArray);
stream = list.stream();
stream.forEach(System.out::println); - 2. 数值流的构造
对于基本数值型,目前有三种对应的包装类型 Stream:IntStream、LongStream、DoubleStream。
// 2、数值流的构造
// 对于基本数值型,目前有三种对应的包装类型 Stream:IntStream、LongStream、DoubleStream
IntStream.of(new int[]{1, 2, 3}).forEach(System.out::println);
IntStream.range(1, 3).forEach(System.out::println);
IntStream.rangeClosed(1, 3).forEach(System.out::println);- 3. 流转换为其他数据结构
// 3、流转换为其他数据结构
Stream stream3 = Stream.of(new String[]{"1", "2", "3"});
// List list1 = stream3.collect(Collectors.toList());
// List list2 = stream3.collect(Collectors.toCollection(ArrayList::new));
// 一个 Stream 只可以使用一次
String str = stream3.collect(Collectors.joining());
System.out.println(str); - 4. 流的典型用法
// 4、流的典型用法
// 1> map/flatMap
// map 生成的是个 1:1 映射,每个输入元素,都按照规则转换成为另外一个元素
Stream stream4 = Stream.of(new String[]{"a", "b", "c"});
stream4.map(String::toUpperCase).forEach(System.out::println);
// 还有一些场景,是一对多映射关系的,这时需要 flatMap
Stream> inputStream = Stream.of(
Arrays.asList(1),
Arrays.asList(2, 3),
Arrays.asList(4, 5, 6)
);
// Stream mapStream = inputStream.map(List::size);
// mapStream.forEach(System.out::println);
Stream flatMapStream = inputStream.flatMap(Collection::stream);
flatMapStream.forEach(System.out::println);
// 2> filter
// filter 对原始 Stream 进行某项测试,通过测试的元素被留下来生成一个新 Stream
Integer[] nums = new Integer[]{1,2,3,4,5,6};
Arrays.stream(nums).filter(n -> n<3).forEach(System.out::println);
// 3> forEach
// forEach 是 terminal 操作,因此它执行后,Stream 的元素就被“消费”掉了,无法对一个 Stream 进行两次terminal 运算
Stream stream13 = Arrays.stream(nums);
stream13.forEach(System.out::print);
// stream13.forEach(System.out::print); // 上面forEach已经消费掉了,不能再调用
System.out.println();
// 具有相似功能的 intermediate 操作 peek 可以达到上述目的
Stream stream14 = Arrays.stream(nums);
stream14
.peek(System.out::print)
.peek(System.out::print)
.collect(Collectors.toList());
System.out.println();
// 4> reduce 主要作用是把 Stream 元素组合起来,字符串拼接、数值的 sum、min、max、average 都是特殊的 reduce
// Stream 的 sum 就相当于:
Integer sum = Arrays.stream(nums).reduce(0, (integer, integer2) -> integer + integer2);
System.out.println(sum);
// 有初始值
Integer sum1 = Arrays.stream(nums).reduce(0, Integer::sum);
// 无初始值
Integer sum2 = Arrays.stream(nums).reduce(Integer::sum).get();
// 5> limit/skip
// limit 返回 Stream 的前面 n 个元素;skip 则是扔掉前 n 个元素。
Arrays.stream(nums).limit(3).forEach(System.out::print);
System.out.println();
Arrays.stream(nums).skip(2).forEach(System.out::print);
System.out.println();
// 6> sorted
// 对 Stream 的排序通过 sorted 进行,它比数组的排序更强之处在于你可以首先对 Stream 进行各类 map、filter、
// limit、skip 甚至 distinct 来减少元素数量后,再排序,这能帮助程序明显缩短执行时间。
Arrays.stream(nums).sorted((i1, i2) -> i2.compareTo(i1)).limit(3).forEach(System.out::print);
System.out.println();
Arrays.stream(nums).sorted((i1, i2) -> i2.compareTo(i1)).skip(2).forEach(System.out::print);
System.out.println();
// 7> min/max/distinct
System.out.println(Arrays.stream(nums).min(Comparator.naturalOrder()).get());
System.out.println(Arrays.stream(nums).max(Comparator.naturalOrder()).get());
Arrays.stream(nums).distinct().forEach(System.out::print);
System.out.println();
// 8> Match
// Stream 有三个 match 方法,从语义上说:
// allMatch:Stream 中全部元素符合传入的 predicate,返回 true
// anyMatch:Stream 中只要有一个元素符合传入的 predicate,返回 true
// noneMatch:Stream 中没有一个元素符合传入的 predicate,返回 true
// 它们都不是要遍历全部元素才能返回结果。例如 allMatch 只要一个元素不满足条件,就 skip 剩下的所有元素,返回 false。
Integer[] nums1 = new Integer[]{1, 2, 2, 3, 4, 5, 5, 6};
System.out.println(Arrays.stream(nums1).allMatch(integer -> integer < 7));
System.out.println(Arrays.stream(nums1).anyMatch(integer -> integer < 2));
System.out.println(Arrays.stream(nums1).noneMatch(integer -> integer < 0)); - 5. 用Collectors来进行reduction操作
// 5、用Collectors来进行reduction操作
// java.util.stream.Collectors 类的主要作用就是辅助进行各类有用的 reduction 操作,例如转变输出为 Collection,把 Stream 元素进行归组。
// 1> groupingBy/partitioningBy
final Collection students = Arrays.asList(
new Student(1, Grade.ONE, 60),
new Student(2, Grade.TWO, 80),
new Student(3, Grade.ONE, 100)
);
// 按年级进行分组groupingBy
students.stream().collect(Collectors.groupingBy(Student::getGrade)).forEach(((grade,students1) -> {
System.out.println(grade);
students1.forEach(student ->
System.out.println(student.getId()+","+student.getGrade()+","+student.getScore()));
}));
// 按分数段分组partitioningBy
students.stream().collect(Collectors.partitioningBy(student -> student.getScore()<=60)).forEach(((match, students1) -> {
System.out.println(match);
students1.forEach(student ->
System.out.println(student.getId()+","+student.getGrade()+","+student.getScore()));
})); - 6. parallelStream
// 6、parallelStream
// parallelStream其实就是一个并行执行的流.它通过默认的ForkJoinPool,可以提高你的多线程任务的速度
Arrays.stream(nums).parallel().forEach(System.out::print);
System.out.println();
System.out.println(Arrays.stream(nums).parallel().reduce(Integer::sum).get());
Arrays.stream(nums).forEach(System.out::print);
System.out.println();
System.out.println(Arrays.stream(nums).reduce(Integer::sum).get());parallelStream底层是使用的ForkJoin。而ForkJoin里面的线程是通过ForkJoinPool来运行的,Java 8为ForkJoinPool添加了一个通用线程池,这个线程池用来处理那些没有被显式提交到任何线程池的任务。它是ForkJoinPool类型上的一个静态元素。它拥有的默认线程数量等于运行计算机上的处理器数量,所以这里就出现了这个java进程里所有使用parallelStream的地方实际上是公用的同一个ForkJoinPool。parallelStream提供了更简单的并发执行的实现,但并不意味着更高的性能,它是使用要根据具体的应用场景。如果cpu资源紧张parallelStream不会带来性能提升;如果存在频繁的线程切换反而会降低性能。
6.7、Stream总结
- 不是数据结构,它没有内部存储,它只是用操作管道从 source(数据结构、数组、generator function、IO channel)抓取数据
- 它也绝不修改自己所封装的底层数据结构的数据。例如 Stream 的 filter 操作会产生一个不包含被过滤元素的新 Stream,而不是从 source 删除那些元素
- 所有 Stream 的操作必须以 lambda 表达式为参数
- 惰性化,很多 Stream 操作是向后延迟的,一直到它弄清楚了最后需要多少数据才会开始,Intermediate操作永远是惰性化的
- 当一个 Stream 是并行化的,就不需要再写多线程代码,所有对它的操作会自动并行进行的
7、Date/Time API
Java 8通过发布新的Date-Time API (JSR 310)来进一步加强对日期与时间的处理。对日期与时间的操作一直是Java程序员最痛苦的地方之一。标准的 java.util.Date以及后来的java.util.Calendar一点没有改善这种情况(可以这么说,它们一定程度上更加复杂)。
这种情况直接导致了Joda-Time——一个可替换标准日期/时间处理且功能非常强大的Java API的诞生。Java 8新的Date-Time API (JSR 310)在很大程度上受到Joda-Time的影响,并且吸取了其精髓。
7.1、LocalDate类
/**
* LocaleDate只持有ISO-8601格式且无时区信息的日期部分
*/
public static void testLocaleDate() {
LocalDate date = LocalDate.now(); // 当前日期
date = date.plusDays(1); // 增加一天
date = date.plusMonths(1); // 减少一个月
date = date.minusDays(1); // 减少一天
date = date.minusMonths(1); // 减少一个月
System.out.println(date);
}7.2、LocalTime类
/**
* LocaleTime只持有ISO-8601格式且无时区信息的时间部分
*/
public static void testLocaleTime() {
LocalTime time = LocalTime.now(); // 当前时间
time = time.plusMinutes(1); // 增加一分钟
time = time.plusSeconds(1); // 增加一秒
time = time.minusMinutes(1); // 减少一分钟
time = time.minusSeconds(1); // 减少1秒
System.out.println(time);
}7.3、LocalDateTime类
/**
* LocaleDateTime把LocaleDate与LocaleTime的功能合并起来,它持有的是ISO-8601格式无时区信息的日期与时间
*/
public static void testLocalDateTime() {
LocalDateTime localDateTime = LocalDateTime.now();
System.out.println(localDateTime); // UTC格式
System.out.println(localDateTime.format(DateTimeFormatter.ofPattern("yyyy-MM-dd HH:mm:ss"))); // 自定义格式
// 原有方法
// Date nowDate = new Date();
// System.out.println(nowDate);
// System.out.println(new SimpleDateFormat("yyyy-MM-dd'T'HH:mm:ss.SSSXXX").format(nowDate));
}7.4、ZoneDateTime类
/**
* ZonedDateTime持有ISO-8601格式,具有时区信息的日期与时间。
*/
public static void testZonedDateTime() {
ZonedDateTime zonedDateTime = ZonedDateTime.now();
System.out.println(zonedDateTime);
ZonedDateTime zonedDatetimeFromZone = ZonedDateTime.now(ZoneId.of("America/Los_Angeles"));
System.out.println(zonedDatetimeFromZone);
ZoneId zoneId = ZoneId.systemDefault();
System.out.println(zoneId);
}7.5、Clock类
/**
* 它通过指定一个时区,然后就可以获取到当前的时刻,日期与时间。
* Clock可以替换System.currentTimeMillis()与TimeZone.getDefault()
*/
public static void testClock() {
Clock utc = Clock.systemUTC(); // 世界标准时间
System.out.println(LocalDateTime.now(utc));
Clock shanghai = Clock.system(ZoneId.of("Asia/Shanghai")); // 上海时间
System.out.println(LocalDateTime.now(shanghai));
}7.6、Duration类
/**
* Duration使计算两个日期间的不同变的十分简单。
*/
public static void testDuration() {
final LocalDateTime from = LocalDateTime.parse("2019-07-15 18:50:50", DateTimeFormatter.ofPattern("yyyy-MM-dd HH:mm:ss"));
final LocalDateTime to = LocalDateTime.parse("2019-07-16 19:50:50", DateTimeFormatter.ofPattern("yyyy-MM-dd HH:mm:ss"));
final Duration duration = Duration.between(from, to);
System.out.println("Duration in days: " + duration.toDays()); // 1
System.out.println("Duration in hours: " + duration.toHours()); // 25
}8、其他特性
8.1、重复注解
假设,现在有一个服务我们需要定时运行,就像Linux中的cron一样,假设我们需要它在每周三的12点运行一次,那我们可能会定义一个注解,有两个代表时间的属性。
@Retention( RetentionPolicy.RUNTIME )
public @interface Schedule {
int dayOfWeek() default 1; // 周几
int hour() default 0; // 几点
}所以我们可以给对应的服务方法上使用该注解,代表运行的时间:
public class ScheduleService {
// 每周三的12点运行
@Schedule(dayOfWeek = 3, hour = 12)
public void starts() {
}
}那么如果我们需要这个服务在每周四的13点也需要运行一下,如果是JDK8之前,那么...尴尬了!你不能像下面的代码,会编译错误
public class ScheduleService {
// 每周三的12点运行
@Schedule(dayOfWeek = 3, hour = 12)
@Schedule(dayOfWeek = 4, hour = 13)
public void starts() {
}
}那么如果是JDK8,你可以改一下注解的代码,在自定义注解上加上@Repeatable元注解,并且指定重复注解的存储注解(其实就是需要需要数组来存储重复注解),这样就可以解决上面的编译报错问题。
@Retention( RetentionPolicy.RUNTIME )
@Repeatable(value = Schedule.schedules.class)
public @interface Schedule {
int dayOfWeek() default 1; // 周几
int hour() default 0; // 几点
@Retention( RetentionPolicy.RUNTIME )
@interface schedules {
Schedule[] value();
}
}同时,反射相关的API提供了新的函数getAnnotationsByType()来返回重复注解的类型。
public static void main(String[] args) throws NoSuchMethodException {
Method method = ScheduleService.class.getMethod("starts");
for (Annotation annotation : method.getAnnotations()) {
System.out.println(annotation);
}
for (Schedule schedule : method.getAnnotationsByType(Schedule.class)) {
System.out.println(schedule.dayOfWeek() + "--" + schedule.hour());
}
}输出结果:
@com.zjm.other.Schedule$schedules(value=[@com.zjm.other.Schedule(hour=12, dayOfWeek=3), @com.zjm.other.Schedule(hour=13, dayOfWeek=4)])
3--12
4--13
8.2、扩展注解
注解可以加在:
public enum ElementType {
/** Class, interface (including annotation type), or enum declaration */
TYPE,
/** Field declaration (includes enum constants) */
FIELD,
/** Method declaration */
METHOD,
/** Formal parameter declaration */
PARAMETER,
/** Constructor declaration */
CONSTRUCTOR,
/** Local variable declaration */
LOCAL_VARIABLE,
/** Annotation type declaration */
ANNOTATION_TYPE,
/** Package declaration */
PACKAGE,
/**
* Type parameter declaration
*
* @since 1.8
*/
TYPE_PARAMETER,
/**
* Use of a type
*
* @since 1.8
*/
TYPE_USE
}JDK8中新增了两种:
1. TYPE_PARAMETER,表示该注解能写在类型变量的声明语句中。
2. TYPE_USE,表示该注解能写在使用类型的任何语句中
8.3、更好的类型推测机制
public class Value {
public static T defaultValue() {
return null;
}
public T getOrDefault(T value, T defaultValue) {
return value != null ? value : defaultValue;
}
public static void main(String[] args) {
Value value = new Value<>();
System.out.println(value.getOrDefault("22", Value.defaultValue()));
}
} 上面的代码重点关注value.getOrDefault("22", Value.defaultValue()), 在JDK8中不会报错,那么在JDK7中呢?
答案是会报错: Wrong 2nd argument type. Found: 'java.lang.Object', required:'java.lang.String' 。所以Value.defaultValue()的参数类型在JDK8中可以被推测出,所以就不必明确给出。
8.4、参数名字保留在字节码中
先来想一个问题:JDK8之前,怎么获取一个方法的参数名列表?
在JDK7中一个Method对象有下列方法:
- Method.getParameterAnnotations() 获取方法参数上的注解
- Method.getParameterTypes() 获取方法的参数类型列表
但是没有能够获取到方法的参数名字列表!
在JDK8中增加了两个方法
- Method.getParameters() 获取参数名字列表
- Method.getParameterCount() 获取参数名字个数
public class ParameterNames {
public void test(String p1, String p2) {
}
public static void main(String[] args) throws Exception {
Method method = ParameterNames.class.getMethod("test", String.class, String.class);
for (Parameter parameter : method.getParameters()) {
System.out.println(parameter.getName());
}
System.out.println(method.getParameterCount());
}
}输出结果:
arg0
arg1
2
从结果可以看出输出的参数个数正确,但是名字不正确!需要在编译时增加–parameters参数后再运行。
在Maven中增加:
maven-compiler-plugin
3.8.0
-parameters
1.8
1.8
输出结果:
p1
p2
2
8.5、并行数组
Java 8增加了大量的新方法来对数组进行并行处理。可以说,最重要的是parallelSort()方法,因为它可以在多核机器上极大提高数组排序的速度。下面的例子展示了新方法(parallelXxx)的使用。
下面的代码演示了先并行随机生成20000个0-1000000的数字,然后打印前10个数字,然后使用并行排序,再次打印前10个数字。
long[] arrayOfLong = new long [ 20000 ];
Arrays.parallelSetAll(arrayOfLong, index -> ThreadLocalRandom.current().nextInt( 1000000 ));
Arrays.stream(arrayOfLong).limit( 10 ).forEach(i -> System.out.print( i + " " ));
System.out.println();
Arrays.parallelSort(arrayOfLong);
Arrays.stream(arrayOfLong).limit( 10 ).forEach(i -> System.out.print( i + " " ));
System.out.println();8.6、CompletableFuture
当我们Javer说异步调用时,我们自然会想到Future,比如:
public class FutureTest {
public static void main(String[] args) throws Exception {
ExecutorService executor = Executors.newCachedThreadPool();
Future result = executor.submit(new Callable() {
@Override
public Integer call() throws Exception {
int sum=0;
System.out.println(Thread.currentThread().getName()+"正在计算...");
for (int i=0; i<100; i++) {
sum = sum + i;
}
Thread.sleep(TimeUnit.SECONDS.toSeconds(3000));
System.out.println(Thread.currentThread().getName()+"计算完了!");
return sum;
}
});
System.out.println(Thread.currentThread().getName()+"做其他事情...");
System.out.println(Thread.currentThread().getName()+"计算结果:" + result.get());
System.out.println(Thread.currentThread().getName()+"事情都做完了!");
executor.shutdown();
}
} 输出结果:
main做其他事情...
pool-1-thread-1正在计算...
pool-1-thread-1计算完了!
main计算结果:4950
main事情都做完了!
那么现在如果想实现异步计算完成之后,立马能拿到这个结果继续异步做其他事情呢?这个问题就是一个线程依赖另外一个线程,这个时候Future就不方便,我们来看一下CompletableFuture的实现:
public class CompletableFutureTest {
public static void main(String[] args) {
ExecutorService executor = Executors.newFixedThreadPool(10);
CompletableFuture result = CompletableFuture.supplyAsync(() -> {
int sum=0;
System.out.println(Thread.currentThread().getName()+"正在计算...");
for (int i=0; i<100; i++) {
sum = sum + i;
}
try {
Thread.sleep(TimeUnit.SECONDS.toSeconds(3000));
} catch (InterruptedException e) {
e.printStackTrace();
}
System.out.println(Thread.currentThread().getName()+"计算完了!");
return sum;
}, executor).thenApplyAsync(sum -> {
System.out.println(Thread.currentThread().getName()+"打印:"+sum);
return sum;
}, executor);
System.out.println(Thread.currentThread().getName()+"做其他事情...");
try {
System.out.println(Thread.currentThread().getName()+"计算结果:" + result.get());
} catch (Exception e) {
e.printStackTrace();
}
System.out.println(Thread.currentThread().getName()+"事情都做完了!");
executor.shutdown();
}
}输出结果:
main做其他事情...
pool-1-thread-1正在计算...
pool-1-thread-1计算完了!
pool-1-thread-2打印:4950
main计算结果:4950
main事情都做完了!
只需要简单的使用thenApplyAsync就可以实现了。
8.7、JVM的新特性
PermGen空间被移除了,取而代之的是Metaspace(JEP 122)。JVM选项-XX:PermSize与-XX:MaxPermSize分
别被-XX:MetaSpaceSize与-XX:MaxMetaspaceSize所代替。